Задачи статистики в пакете SPSS
8.5 Агрегирование данных
На базе значений одной или нескольких группирующих переменных (переменных разбиения) можно объединить наблюдения в группы (агрегировать) и создать новый файл данных, содержащий по одному наблюдению для каждой группы разбиения. Для этого SPSS предоставляет большое количество функций агрегирования. В сельскохозяйственном исследовании рассматривалось содержание свиней в двух различных типах свинарников. При этом в каждом из двух свинарников осуществлялся мониторинг поведения восьми свиней в течение двадцатидневного периода. На протяжении этого периода фиксировалась длительность определенных действий животных (то есть сколько времени свиньи рылись, ели, чесали голову и туловище). Данные хранятся в файле schwein.sav, содержащем следующие переменные:| Имя переменной | Пояснение |
| stall | Тип свинарника (1 или 2) |
| nr | Порядковый номер свиньи (от 1 до 8) |
| zert | Номер дня (от 1 до 20) |
| wuehlen | Длительность рытья (в секундах) |
| fressen | Длительность кормежки (в секундах) |
| massage | Длительность чесания (в секундах) |
- Загрузите файл schwein.sav.
- Выберите в меню команды Data (Данные) Aggregate... (Агрегировать)
- В качестве переменных разбиения перенесите переменные stall и nr в поле Break Variable(s), а в качестве переменных агрегирования (Aggregate Variable(s)) выберите wuehlen, fressen и massage. Диалоговое окно приобретет вид, показанный на рис. 8.8.
- Для этого щелкните на первой переменной, а затем на кнопке Funktion... (Функция). Откроется диалоговое окно Aggregate Data: Aggregate Function (Агрегировать данные: Функция агрегирования) (см. рис. 8.9).
- Выберите пункт Sum of values (Сумма значений) и щелчком на кнопке Continue вернитесь в первое диалоговое окно.
- Выполните те же действия для двух других переменных агрегирования. Агрегированные данные будут сохранены в новом файле.
- Щелкните на кнопке File... и выберите для нового файла имя pigaggr.sav.
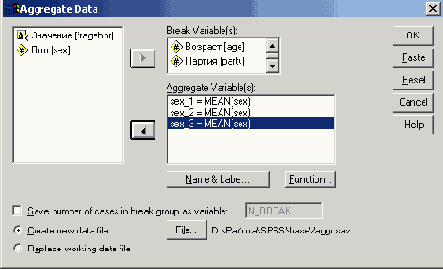
Рис. 8.8: Диалоговое окно Aggregate Data
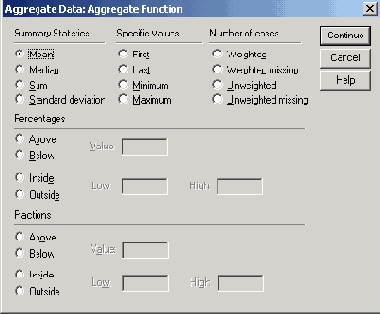
Рис. 8.9: Диалоговое окно Aggregate Data: Aggregate Function
После щелчка на кнопке Отбудет создан новый файл, содержащий 2 х 8=16 наблюдений и переменные stall, nr, wuehle_l, fresse_l и massag_l.- Загрузите этот файл и просмотрите его содержимое в редакторе данных.
- Как описано в разделе 13.1, проведите тест Стьюдента для независимых выборок с группирующей переменной stall и тестируемыми переменными fresse_l, massag_l и wuehle_l. Вы получите следующий результат:
Group Statistics (Статистика группы)
| STALL | N | Mean (Среднее значение) | Std. Deviation (Стандартное отклонение) | Std. Error Mean (Стандартная ошибка среднего значения) |
| FRESSE 1 1 2 | 8 8 | 339,0125 231,6750 | 98,2384 109,5381 | 34,7325 38,7276 |
| MASSAG 1 1 2 | 8 8 | 2,2875 40,3625 | 3,3689 54,1795 | 1,1911 19,1553 |
| WUEHLE 1 1 2 | 8 8 | 1996,587 1964.600 | 326,3919 642,5314 | 115,3970 227,1692 |
Independent Samples Test (Тест для независимых выборок)
| Levne's Test forEquality of Variancies (Tecт Левена на равенство дисперсий) | Т-Test for Equality of Means (Тест Стьюдента на равенство средних) | |||||||||
| F | Значи-мость | Т | df | (дву сторон-няя) | Разность средних | Стан-дартная ошибка разницы | 95% доверительный интервал разности Нижняя и Верхняя | |||
| FRES-SE_.1 | Equal variances assumed (Дис-персии равны) Equal variances not assumed (Дис-персии не равны) | .128 | .726 | 2,063 2,063 | 14 13, 837 | ,058 ,058 | 107 ,3375 107 ,3375 | 52, 0209 52 ,0209 | -4,2362 -4,3594 | 218, 9112 219, 0344 |
| MAS-SAG 1 | Equal variances assumed (Дис-персии равны) Equal variances not assumed (Дис-персии не равны) | 7.390 | ,017 | -1,984 -1,984 | 14 7,054 | ,067 ,087 | -38, 0750 -38,0750 | 19, 1923 19. 1923 | -79,2385 -83,3872 | 3,0885 7,2372 |
| WU-EHLE_1 | variances assumed (Дис-персии равны) Equal variances not assumed (Дис-персии не равны) | 2,274 | ,154 | ,126 ,126 | 14 10 ,387 | ,902 ,902 | 31, 9875 31 ,9875 | 254 ,7985 254 ,7985 | -514 ,5010 -532, 8844 | 578. 4760 596 ,8594 |