Задачи статистики в пакете SPSS
21.1 Задания типа верно — не верно
В качестве примера, который мы хотим обработать при помощи SPSS, рассмотрим личностный тест, с помощью которого определяется степень любопытства опрашиваемых.| № | Вопрос | Правильный ответ |
| 1 | У Вас много книг? | Да |
| 2 | Ходите ли Вы за покупками всё время в одни и те же магазины? | Нет |
| 3 | Считаете ли Вы, что космонавтику развивать необходимо? | Да |
| 4 | Вас не интересует, почему на вашего соседа одели наручники? | Нет |
| 5 | Можете ли Вы долго заниматься чем-нибудь одним? | Да |
| 6 | Регулярно ли Вы смотрите новости? | Да |
| 7 | Знаете ли Вы, сколько человек живёт в городе, в котором проживаете Вы? | Да |
| 8 | Ходите ли Вы на работу всегда одной и той же дорогой? | Нет |
| 9 | Становится ли Вам иногда скучно? | Нет |
| 10 | Хотели бы Вы полететь на Луну? | Да |
| 11 | Читаете ли Вы ежедневные газеты регулярно? | Да |
| 12 | Спрашивали ли Вы уже себя, как будет выглядеть мир через сто лет? | Да |
| 13 | Замечаете ли вы иногда, что недовольны тем, что Вы можете и знаете? | Да |
| 14 | Предоставите ли Вы себя для научных экспериментов? | Да |
| 15 | Интересует ли Вас, сколько зарабатывает ваш сосед? | Да |
| 16 | Бездельничаете ли Вы во время отпуска? | Нет |
| 17 | Приятней ли Вам находиться в кругу большого количества друзей, нежели с одним другом? | Да |
| 18 | Случается ли с вами часто так, что Вы не знаете с чего начать? | Да |
Индекс сложности
В простейшем случае он представляет собой долю правильных ответов на данный вопрос, взятую в процентах от общего количества ответов. Для вопросов с несколькими возможными ответами и ступенчатыми ответами существуют модифицированные формулы. Удивительно, но для сложных вопросов индекс сложности принимает малые значения, а для лёгких большие. Вопросы с низким и высоким индексом сложности считаются не желательными.Коэффициент избирательности
Коэффициентом избирательности, который является важным критерием для оценки применимости вопроса, служит корреляционный коэффициент между ответом на вопрос и суммарным показателем теста. В качестве суммарного показателя теста берётся сумма всех ответов. Это означает, что все правильные ответы должны иметь одинаковый знак! К сожалению, этому важному обстоятельству в справочниках уделяется не достаточно внимания. Для приведенного примера это означает, что пункты 2, 4, 8, 9 и 16 перед анализом должны быть подвергнуты перекодировке. Для определения корреляционного коэффициента Линерт предлагает различные варианты, так, к примеру, двухрядная поточечная корреляция между заданием с ответом верно — не верно и значением масштаба или ранговая корреляция между заданием со ступенчатым ответом и значением масштаба. Как ни странно: SPSS всегда использует коэффициенты Пирсона. Непригодные для применения пункты обычно отбираются посредством сравнения индексов сложности и избирательности. Самым простым способом является отбор сначала тех вопросов, которые обладают индексом сложности ниже 20 или выше 80, а затем из списка оставшихся вопросов исключаются те, которые имеют самые низкие коэффициенты избирательности. Линерт предлагает рассчитывать ещё и дополнительные показатели вопросов, такие как: индекс однородности, индекс пригодности, селекционный показатель и (если имеется так называемый внешний критерий) коэффициенты действительности.Коэффициент пригодности
Коэффициент пригодности является важным критерием для оценки результата теста. Он является мерой точности, с которой проводится тестирование некоторого признака. SPSS предлагает для этой цели множество методов; по умолчанию устанавливается альфа Кронбаха (Cronbach's Alpha) со значением, модуль которого находится между 0 и 1. Обработаем наш пример при помощи SPSS.- Откройте файл nuegier.sav.
- Это можно сделать при помощи метода, рассмотренного в главе 8, посредством выбора меню Transform (Трансформировать) Recode (Перекодировать) Into same Variables... (В те же переменные)
RECODE item2, item4, item8, item9, item16 (1=2) (2=1). EXECUTE.
- После перекодировки выберите в меню Analyze (Анализ) Scale (Масштабировать) Reliability Analysis... (Анализ пригодности) Откроется диалоговое окно Reliability Analysis (Анализ пригодности).
- Переменные iteml-itemlS поместите в поле пунктов (Items:). Затем из числа предлагаемых методов расчёта коэффициентов пригодности необходимо выбрать подходящий:
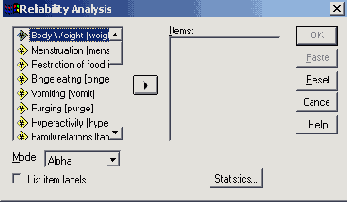
Рис. 21.1: Диалоговое окно Reliability Analysis (Анализ пригодности)
- Alpha (Альфа): Альфа Кронбаха (при дихотомических пунктах используется формула Кудера-Ричардсона 20 (Kuder-Richardson- Formula 20))
- Split-half (Расщепление на две половины): Определение пригодности с расщеплением на две половины по Спирману-Брауну (Spearman-Brown)
- Guttman (Гуттман): Определение нижней границы пригодности Гуттмана
- Parallel (Парралельно): Оценка максимального правдоподобия пригодности теста при условии наличия одинаковых дисперсий пунктов
- Strict parallel (Строго параллельно): Оценка максимального правдоподобия пригодности теста при условии наличия одинаковых средних значений пунктов и одинаковых дисперсий пунктов.
- Оставьте предварительную установку Alpha (Альфа) и щёлкните на выключателе Statistics...(Статистики). Откроется диалоговое окно Reliability AnalysisStatistics (Анализ пригодности: Статистики).
- Descriptives for (Дескриптивные (описательные) статистики для) Item (Пункт): Среднее значение и стандартное отклонение для каждого пункта анкеты или вопроса Scale (Шкала): Среднее значение, дисперсия и стандартное отклонение для значения масштаба
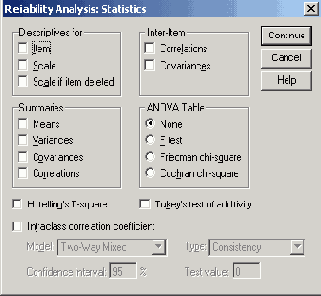
Рис. 21.2: Диалоговое окно Reliability Analysis'.Statistics (Анализ пригодности: Статистики)
Scale if item deleted (Масштабировать, если пункт удалён): Когда при расчёте значения масштаба этот пункт (вопрос) не учитывается, для каждого такого Пункта (ответа на вопрос анкеты), выводятся: среднее значение и дисперсия значения шкалы, корреляция пункта со значением масштаба (то есть избирательность) и альфа Кохрана.- Summaries (Итоги, общие сведения)
- Inter-Item (Между пунктами)
- ANOVA-ТаЫе (Таблица ANOVA)
- Hottelling's T-square (Т-квадрат Хоттелинга): Тест Хоттелинга для проверки утверждения, что средние значения пунктов равны между собой.
- Tukey's test ofadditivity (Критерий аддитивности Тьюки): Тест Тьюки на аддитивность пунктов.
- Здесь ограничьтесь активизацией опции Scale if item deleted (Масштабировать, если пункт удалён) и щёлкните на Continue (Далее).
- Начните расчёт нажатием ОК.
| RЕLIАВILIТУ ANALYSIS SCALE (ALPHA) | ||||
| Item-total | Statistics | |||
| Scale Mean if Item Deleted | Scale Variance if Item Deleted | Corrected Item-Total Correlation | Alpha if Item Deleted | |
| ITEM1 | 24,9333 | 13,5126 | ,5410 | ,7664 |
| ITEM2 | 25,0667 | 14,4092 | ,2679 | ,7862 |
| ITEM3 | 25,1000 | 13,5414 | ,5097 | ,7684 |
| ITEM4 | 25,4333 | 16,0471 - | -,1676 | ,8052 |
| ITEMS | 25,2000 | 13,6828 | ,4907 | ,7701 |
| ITEM6 | 25,1667 | 14,5575 | ,2358 | ,7883 |
| ITEM7 | 25,5000 | 15,2931 | ,1738 | ,7887 |
| ITEMS | 24,8000 | 15,1310 | ,1154 | ,7942 |
| ITEM9 | 25,2000 | 13,8897 | ,4304 | ,7745 |
| ITEM10 | 24,8667 | 13,8437 | ,4732 | ,7717 |
| ITEM11 | 25,3667 | 14,2402 | ,4223 | ,7760 |
| ITEM12 | 25,0667 | 13,3057 | ,5763 | ,7633 |
| ITEM13 | 25,0000 | 13,2414 | ,6017 | ,7615 |
| ITEM14 | 24,9667 | 13,8954 | ,4196 | ,7752 |
| ITEM15 | 25,0000 | 13,3103 | ,5813 | ,7630 |
| ITEM16 | 25,0333 | 14,0333 | ,3713 | ,7787 |
| ITEM17 | 24,9667 | 15,3437 | ,0283 | ,8023 |
| ITEM18 | 24,9667 | 13,9644 | ,4000 | ,7766 |
| Reliability Coefficients | ||||
| N of Cases =30,0 | N of Items= 18 | |||
| Alpha =,7887 |
- Мы уже говорили о необходимости проведения расчета индекса сложности. Для расчёта индекса сложности выберите в меню Analyze (Анализ) Descriptive Statistics (Дескриптивные статистики) Frequencies... (Частоты)
| Пункт | Индекс сложности | Пункт | Индекс сложности |
| 1 | 36,7 | 10 | 30,0 |
| 2 | 50,0 | 11 | 80,0 |
| 3 | 53,3 | 12 | 50,0 |
| 4 | 86,7 | 13 | 43,3 |
| 5 | 63,3 | 14 | 40,0 |
| 6 | 60,0 | 15 | 43,3 |
| 7 | 93,3 | 16 | 46,7 |
| 8 | 23,3 | 17 | 40,0 |
| 9 | 63,3 | 18 | 40,0 |