Задачи статистики в пакете SPSS
18.2 Пример из области социологии
В своём исследовании "Культурный прорыв. Изменение ценностей в западном мире" (см. дополнительную литературу) Рональд Инглехарт (Ronald Inglehart) приводит тезис, что в более зрелых возрастных группах значимо большее количество человек высказались в пользу материальных ценностей (см. гл. 8.4.2). Среди младших поколений, согласно Инглехарту, растёт доля постматериалистов. Склонность опрошенных к постматериалистическим ценностям зависит от их образования и профессиональной квалификации. Чем выше образование и профессиональная квалификация, тем выше склонность к постматериалистическим ценностям. Значение имеет также и социально-экономический статус отца; согласно мнению Инглехарта, чем он выше, тем значительней доля постматериалистов. При помощи дискриминантного анализа мы проверим эту теорему смены ценностей, сформулированную американским политологом.- Откройте в редакторе данных файл postmat.sav.
| Имя переменной | Значение |
| ingMnd | Индекс Инглехарта |
| Ценности: | |
| 1 Постматериалисты | |
| 2 Постматериалисты смешанного типа | |
| 3 Материалисты смешанного типа | |
| 4 Материалисты | |
| 5 Не могу дать ответ | |
| 6 Нет данных | |
| statpaps | Социально-экономический статус отца (индекс) |
| Значения: | |
| 1 Низкий | |
| 5 Высокий | |
| 8 Формируется в данный момент (отсутствующее значение) | |
| 9 Безработный, в заключении, умер, пенсионер и т.д. (отсутствующее | |
| значение) | |
| schule | Уровень образования опрашиваемых |
| Значения: | |
| 1 Без образования | |
| 2 Начальная школа | |
| 3 Незаконченное среднее | |
| 4 Среднее | |
| alter | Возраст опрашиваемых |
| Значения: | |
| 1 18 до 29 лет | |
| 2 30 до 44 лет | |
| 3 45 до 59 лет | |
| 4 60 до 74 лет | |
| 5 75 до 88 лет | |
| 6 89 и старше | |
| 9 Не указан (отсутствующее значение) | |
| ausbild | Профессиональное образование опрашиваемых Значения: 0 Образование отсутствует (отсутствующее значение) 1 Краткосрочное образование 2 Ученик 3 Мастер/техник 4 Высшее образование |
- Для этого в редакторе синтаксиса введите следующие команды:
RECODE ingl_ind (1,2 = 1) (3,4 = 2)
INTO ingl_dic. VARIABLE LABELS
ingl_dic = "Inglehart-Index, dichotom".
VALUE LABELS
ingl_dic 1 "Postmat. Typen"
2 "Materialist.Typen".
EXECUTE.
- Вы можете также загрузить в редактор синтаксиса и файл ingledic.sps, в котором находятся эти команды.
- Пометьте команды и запустите программу щелчком на кнопке Run Current (Выполнить текущие команды).
- Выберите в меню опции Analyze (Анализ) Classify (Классифицировать) Discriminant... (Дискриминантный анализ)
- Переменную ingl_dic поместите в поле групповых переменных.
- Щёлкните на выключателе Define Range... (Определить область) и в качестве минимального значения введите 1, а в качестве максимального значения 2.
- Переменные statpaps, schule, alter и ausbild поместите в список Independents (Независимые переменные). Оставьте метод ввода переменных Enter independents together (Независимые переменные вводить одновременно), установленный по умолчанию.
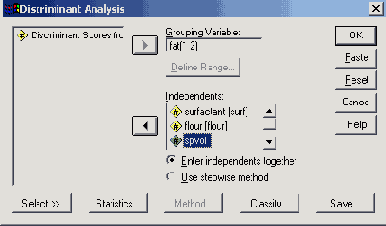
Рис. 18.4: Диалоговое окно Discriminant Analysis (Дискриминантный анализ).
- Щёлкните по выключателю Statistics... (Статистики)
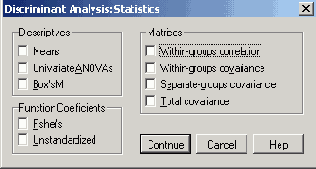
Рис. 18.5: Диалоговое окно Discriminant Analysis: Statistics (Дискриминантный анализ: Статистики)
- Активируйте опции: Means (Средние значения), Univariate ANOVAs (Одномерные тесты AN OVA), Unstandardized Func-tion Coefficients (He стандартизированные коэффициенты функции) и Within-groops Correlation Matrice (Корреляционная матрица внутри группы).
- Подтвердите нажатием Continue (Далее).
- Щёлкните на выключателе Classify... (Классифицировать). Откроется диалоговое окно Discriminant Analysis: Classification (Дискриминантный анализ: Классификация) (см. рис. 18.6).
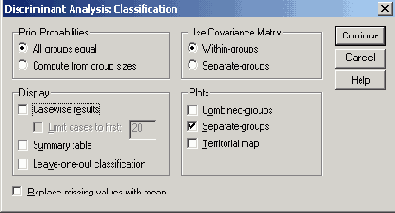
Рис. 18.6: Диалоговое окно Discriminant Analysis: Classification (Дискриминантный анализ: Классификация)
- Сделайте здесь запрос на Summary table (Сводную таблицу).
- Щёлкните на выключателе Save... (Сохранить). Откроется диалоговое окно Discriminant Analysis: Save (Дискриминантный анализ: Сохранить) (см. рис. 18.7).
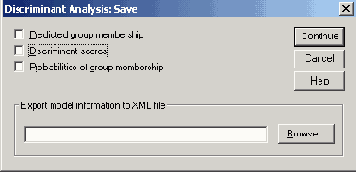
Рис. 18.7: Диалоговое окно Discriminant Analysis: Save (Дискриминантный анализ: Сохранить)
Видно, что в 10 версии появилась возможность сохранения информации о модели в так называемом, XML-файле (см. примечания к рис. 16.3).- Активируйте вывод Predicted group membership (Прогнозируемой принадлежности к группе), Discriminant scores (Значений дисриминантной функции) и Probabilities of group membership (Вероятностей принадлежности к группе).
- Подтвердите нажатием Continue (Далее) и затем ОК.
Analysis Case Processing Summary (Анализ обработанных наблюдений)
| Unweighted Cases (He взвешенные случаи) | N | Percent (Процент) | |
| Valid (Действительные) | 2200 | 71,9 | |
| Excluded (Исключенные) | Missing or out-of-range group codes (Отсутствующие или находящиеся за пределами допустимой области кодировки принадлежности к группе) | 19 | ,6 |
| At least one missing discriminating variable (По меньшей мере одна отсутствующая дискриминационная переменная) | 816 | 26,7 | |
| Both missing or out-of-range group codes and at least one missing discriminating variable (Обе кодировки принадлежности к группе отсутствуют или находятся за пределами допустимой области, или по меньшей мере одна отсутствующая дискриминационная переменная) | 23 | ,8 | |
| Total (Общее количество исключённых) | 858 | 28,1 | |
| Total (Общее количество случаев) | 3058 | 100,0 |
Group Statistics
| (Статистики для групп) |
|||||
| INGL_DIC (Индекс Ингпехарта, дихото-мический) | Mean (сред-нее значе-ние) | Std. Deviation (Станда-ртное отклоне-ние) | Valid N (listwise) (Действительные значения (по списку)) | ||
| Unwei-ghted (Не взвеше-нные) | Weigh-ted (Взвеше-нные) | ||||
| 1,00 (Пост-материа-листический тип) | SES-lndex des Vaters (социально-экономи-ческий статус отца) | 2,8148 | 1,1718 | 1091 | 1091,000 |
| Schulabschluss (Образование) | 2,9853 | ,8194 | 1091 | 1091,000 | |
| ALTER, BEFRAGTE<R>, KATEGORISIERT (Возраст, опрошен-ного(ой), разбит на категории) | 2,1842 | 1,0887 | 1091 | 1091,000 | |
| Berufsaus-bildung (Профес-сиональное образо-вание) | 2,1888 | 1,1562 | 1091 | 1091,000 | |
| 2,00 (Материа-листический тип) | SES-lndex des Vaters (социально-экономи-ческий статус отца) | 2,3904 | 1,0407 | 1109 | 1109,000 |
| Scnulabschluss (Образование) | 2,5248 | ,7627 | 1109 | 1109,000 | |
| ALTER, BEFRAGTE<R>, KATEGORISIERT (Возраст ,опрошен-ного(ой), разбит на категории) | 2,8151 | 1,2111 | 1109 | 1109,000 | |
| Berufsa-usbildung (Профес-сиональное образование) | 1,8792 | 1,0249 | 1109 | 1109,000 | |
| Total (Сумма) | SES-lndex des Vaters (социально-экономи-ческий статус отца) | 2,6009 | 1,1275 | 2200 | 2200,000 |
| Schulabschluss (Образование) | 2,7532 | ,8240 | 2200 | 2200,000 | |
| ALTER, BEFRAGTE<R>, KATEGORI-SIERT (Возраст, опрошен-ного(ой), разбит на категории) | 2,5023 | 1,1942 | 2200 | 2200,000 | |
| Berufsa-usbildung (Профес-сиональное образование) | 2,0327 | 1,1027 | 2200 | 2200,000 |
Tests of Equality of Group Means (Тест равенства групповых средних значений)
| Wilks1 Lambda (Лямбда Уилкса) | F | df1 | df2 | Sig. (Значимость) | |
| SES-lndex des Vaters (социально-экономический статус отца) | ,965 | 80,746 | 1 | 2198 | ,000 |
| Schulabschluss (Образование) | ,922 | 186,281 | 1 | 2198 | ,000 |
| ALTER, BEFRAGTE<R>, KATEGORISIERT (Возраст, опрошенного(ых), разбит на категории) | ,930 | 164,951 | 1 | 2198 | ,000 |
| Berufsausbildung (Профессиональное образование) | ,980 | 44,222 | 1 | 2198 | ,000 |
| SES-lndex des Vaters (социально- экономи-ческий статус отца) | Schulab-schluss (Образо-вание) | ALTER, BEFRAG -TE<R>, KATEGO-RISIERT (Возраст, опрошен-ного(ой), разбит на категории) | Berufsau-sbildung (Профес- сиона-льное образо-вание) | ||
| Corre-lation (Корре-ляция) | SES-lndex des Vaters (социально-экономи-ческий статус отца) | 1,000 | ,327 | -,033 | ,137 |
| Schula-bschluss (Образо-вание) | ,327 | 1,000 | -,275 | ,377 | |
| ALTER, BEFRA-GTE<R>, KATEGO-RISIERT (Возраст, опрошен-ного(ых), разбит на категории) | -,033 | -,275 | 1,000 | ,018 | |
| Berufsa-usbildung (Профес-сиональное образо-вание) | ,137 | ,377 | ,018 | 1,000 |
Eigenvalues (Собственные значения)
| Function (Функция) | Eigenvalue (Собствен-ное значение) | % of Variance (% диспе-рсии) | Cumulative % (Сово-купный %) | Canonical Correlation (Канони-ческая корре-ляция) |
| 1 | ,142а | 100,0 | 100,0 | ,353 |
Wilks' Lambda (Лямбда Уилкса)
| Test of Function(s) Wilks' Lambda (Тест функции (и)) (Лямбда Уилкса) | Chi-square (Хи-квадрат) | df | Sig. (Значимость) |
| 1 ,875 | 292,431 | 4 | ,000 |
Standardized Canonical Discriminant Function Coefficients
|
(Стандартизиро-ванные канонические коэффициенты дискриминантной функции) |
|
| Function (Функция) | |
| 1 | |
| SES-lndex des Vaters (социально-экономический статус отца) | ,321 |
| Schulabschluss (Образование) | ,434 |
| ALTER, BEFRAGTE<R>, KATEGORISIERT (Возраст, опрошенного(ой), разбит на категории) | -,599 |
| Berufsausbildung (Профессиональное образование) | ,179 |
Structure Matrix
|
(Структурная матрица) |
|
| Function (Функция) | |
| 1 | |
| Schulabschluss (Образование) | ,771 |
| ALTER, BEFRAGTE<R>, KATEGORISIERT (Возраст, опрошенного(ой), разбит на категории) | -,726 |
| SES-lndex des Vaters (социально-экономический статус отца) | ,508 |
| Berufsausbildung (Профессиональное образование) | ,376 |
Canonical Discriminant Function Coefficients
|
(Канонические коэффициенты дискриминантной функции) |
|
| Function (Функция) | |
| 1 | |
| SES-lndex des Vaters (социально-экономический статус отца) | ,290 |
| Schulabschluss (Образование) | ,549 |
| ALTER, BEFRAGTE<R>, KATEGORISIERT (Возраст, опрошенного(ой), разбит на категории) | -,520 |
| Berufsausbildung (Профессиональное образование) | ,164 |
| (Constant) (Постоянно) | -1,297 |
Functions at Group Centroids (Функции для групповых центроидов)
| INGL DIC | Function (Функция) |
| 1 | |
| 1 ,00 (Постматериалистический тип) | ,380 |
| 2,00 (Материалистический тип) | -.374 |
Classification Resultsа
| (Классификационные результаты) |
|||||
| INGL_DIC (Индекс Инглехарта, дихото-мический) | Predicted Group Membership (Прогнозируемая принадлежность к группе) | Total (Сум-ма) | |||
| 1,00 (Постматери-алисти-ческий тип) | 2,00 (Материа-листи-ческий тип) | ||||
| Original (Перво-начально) | Count (Коли-чество) | 1 ,00 (Пост-материа-листи-ческий тип) | 710 | 381 | 1091 |
| 2,00 (Материа-листический тип) | 410 | 699 | 1109 | ||
| Ungrouped cases (He сгруп-пирован-ные наблю-дения) | 7 | 12 | 19 | ||
| % | 1 ,00 (Постматериа-листический тип) | 65,1 | 34,9 | 100,0 | |
| 2,00 (Материа-листи-ческий тип) | 37,0 | 63,0 | 100,0 | ||
| Ungrouped cases (He сгруп-пирован-ные наблю-дения) | 36,8 | 63,2 | 100,0 |
- Выберите в меню Data (Данные) Select Cases... (Выбрать наблюдения)
- Щёлкните на опции If condition is satisfied (Если выполняется условие) и затем на выключателе If... (Если).
- В редакторе условий введите следующее условие:
- Подтвердите нажатием Continue (Далее) и затем ОК.
- В диалоговом окне Discriminant Analysis (Дискриминантный анализ) переменную ingl_ind (не ingl_dic!) поместите в поле для групповых переменных. В качестве границ области изменения задать значения 1 и 4.
- В список независимых переменных поместите переменные statpaps, schule, alter и ausbild.
- Дополнительные установки под выключателями Statistics... (Статистики), Classify... (Классифицировать) и Save... (Сохранить) произведите так, как было описано ранее.
Classification Results
|
(Результаты классификации) |
|||||
| INGLEHART-INDEX (Индекс Инглехарта, дихото-мический) | Predicted Group Membership (Прогнозируемая принадлежность к группе | Total (Сумма) | |||
| POSTMATE-RIALISTEN (Постмате-риалисты) | MATERI-ALISTEN (Матери-алисты) | ||||
| Original (Перво-начально) | Count (Коли-чество) | POSTMATE-RIALISTEN (Постмате-риалисты) | 409 | 109 | 518 |
| MATERI-ALISTEN (Матери-алисты) | 133 | 297 | 430 | ||
| % | POSTMATE-RIALISTEN (Постмате-риалисты) | 79,0 | 21,0 | 100,0 | |
| MATERI-ALISTEN (Матери-алисты) | 30,9 | 69,1 | 100,0 |