10.4.2 Анализ для групп наблюдений
Проанализируем исходное содержание холестерина (переменная
cho10), которое содержится в файле hyper.sav, для четырех возрастных классов (переменная
ak).
-
В диалоговом окне Explore кнопкой Reset (Сброс) восстановите настройки по умолчанию и перенесите переменную cholO в список зависимых переменных (Dependent List), а переменную ak — в список факторов
(Factor List).
-
Щелкните на кнопке ОК.
В результате будут вычислены характеристики описательной статистики и построена диаграмма ветвей и листьев раздельно по четырем возрастным классам. На коробчатой диаграмме соответственно появятся четыре прямоугольника (см. рис. 10.8).
Остальные статистические параметры также можно вычислить раздельно по разным значениям группирующей переменной (в данном случае по возрастным классам). Это относится и к выводу гистограмм и диаграмм нормального распределения в окне просмотра.
Далее можно проверить, значимо ли различаются группы наблюдений, образованные в соответствии со списком факторов, по дисперсиям зависимых переменных. В нашем примере можно выяснить, существуют ли значимые различия между пациентами четырех возрастных классов по разбросу содержания холестерина. Такая проверка гомогенности дисперсий необходима, например, если требуется провести для четырех возрастных группах простой дисперсионный анализ на сравнение средних (см. главу 13). Дисперсионный анализ как раз предусматривает гомогенность распределения дисперсий по отдельным ячейкам.
-
В диалоговом окне Explore: Plots в группе Spread vs. Level with Levene Test (Зависимость «Разброс — средний уровень по тесту Левена») выберите опцию Power estimation (Экспоненциальная оценка).
-
Запустите вычисления, щелкнув на Continue и ОК.
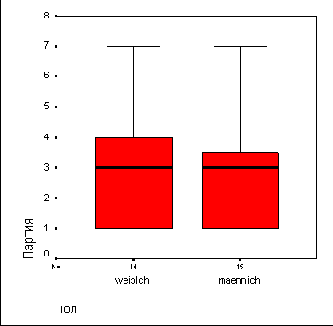
Рис. 10.8: Коробчатая диаграмма по группам
В результате во всех четырех вариантах будет проведен тест Левена на гомогенность
дисперсий. Этот тест определяет уровень значимости (допустимую вероятность ошибки р. При р > 0,05 различие дисперсии между данными группами не значимо. Следовательно, их можно рассматривать как гомогенные. В данном примере тест Левена
не дает значимого результата.
Test of Homogenity of Variances (Тест на гомогенность дисперсий)
|
|
Levene Statistic (Статистика Левена)
|
df1
|
df2
|
Sig. (Значи-мость)
|
|
холестерин, исходный
|
Based on Mean (На основе среднего)
|
,190
|
3
|
170
|
,903
|
|
Based on Median (На основе медианы)
|
,157
|
3
|
170
|
,925
|
|
Based on Median and with adjusted df (Ha основе медианы и с уточненным df)
|
,157
|
3
|
169,024
|
,925
|
|
Based on trimmed mean (На основе усеченного среднего)
|
,178
|
3
|
170
|
,912
|
Далее выводится диаграмма, на которой для каждой группы изображена зависимость разброса значений от центрального значения. Точнее говоря, на оси X откладывается логарифм медианы, а на оси Y — логарифм межквартильной широты. Если дисперсии не гомогенны, а гетерогенны (тест Левена дает значимый результат, SPSS дает возможность провести так называемое степенное преобразование данных. Для этого выберите в диалоговом окне Explore: Plots опцию Transformed (С пре-5разованием) и в списке Power (Степень) выберите подходящую степень. Возможные
степеные преобразования показаны в нижеследующей таблице.
|
Степень
|
Преобразование
|
|
3
|
кубическое
|
|
2
|
квадратное
|
|
|
|
квадратный корень
|
|
В
|
натуральный логарифм.
|
|
-1/2
|
величина, обратная квадратному корню
|
|
-1
|
обратная величина
|
Успешность преобразования можно оценить, вновь построив зависимость разброса от среднего уровня (Spread vs. Level with Levene Test). Однако с такими преобразованиями следует обходиться очень осторожно. Нелинейные преобразования изменяют отношения между группами, и, кроме того, статистические суждения в таком
случае основываются уже не на исходных, а на преобразованных значениях.