Константы и переменные, работа с памятью
Программисту часто бывает удобно работать не с «анонимными» значениями, а с именованными. По аналогии со средствами других языков эти средства языка Форт называются константами и переменными. Впоследствии мы увидим, что они являются не «изначальными», а (наряду с определениями через двоеточие) частными случаями более общего понятия «определяющие слова».
Слово CONSTANT (константа) А --> работает следующим образом. Со стека снимается верхнее значение, а из входного текста выбирается очередное слово и запоминается в словаре как новая команда. Ее действие состоит в следующем: поместить на стек значение А, снятое со стека в момент ее определения. Например, 4 CONSTANT XOP. В дальнейшем при исполнении слова XOP число 4 будет положено на стек.
Слово VARIABLE (переменная) А --> резервирует в словаре два байта, а из входного потока выбирает очередное слово и вносит его в словарь как новую команду, которая кладет на стек адрес зарезервированной двухбайтной области. Можно сказать, что переменная работает, как константа, значением которой является адрес зарезервированной двухбайтной области.
Работа с переменной помимо получения ее адреса состоит в получении ее текущего значения и присваивании нового. Для этого язык Форт имеет следующие слова:
@ A ---> B ! B,A --->
Слово @ (читается «разыменовать») снимает со стека значение и, рассматривая его как адрес области оперативной памяти, кладет на стек двухбайтное значение, находящееся по этому адресу. Обратное действие выполняет слово ! (восклицательный знак, читается «присвоить»), которое снимает со стека два значения и, рассматривая верхнее как адрес области оперативной памяти, засылает по нему второе снятое значение. Эти слова можно использовать не только для переменных, но и для любых адресов оперативной памяти. Следующий протокол работы показывает порядок использования переменной в сочетании с этими словами:
> VARIABLE X 1 X ! OK > X @ . 1 ОК > Х @ NEGATE X ! X @ . -1 ОК
В первой строке определяется переменная X, и ей присваивается начальное значение 1. Затем текущее значение переменной X распечатывается. После этого текущее значение меняется на противоположное по знаку и вновь распечатывается.
Полезным вариантом слова ! является слово +! (плюс-присвоить) N,A --> , которое увеличивает на N значение, находящееся в памяти по адресу A. Несмотря на то, что это слово легко выразить через + и !:
: +! ( N,A ---> ) DUP @ ROT + SWAP ! ;
оно включено в обязательный набор слов.
Слова, определенные через CONSTANT и VARIABLE, — такие же равноправные слова форт-системы, как и определенные через двоеточие. Их также можно использовать в определениях других слов и исключать из словаря словом FORGET.
Для работы со значениями двойной длины имеются слова
2CONSTANT AA ---> 2VARIABLE ---> 2@ A ---> BB 2! BB,A --->
из стандартного расширения двойных чисел. При размещении в памяти такие значения рассматриваются как пары смежных двухбайтных значений одинарной длины: сперва (в меньших адресах) располагается старшая половина, затем (в больших адресах) младшая. Адресом значения двойной длины считается адрес его старшей половины.
Константы и переменные позволяют программисту использовать память в словаре вполне определенным образом. А как быть, если требуется что-то иное? Общий принцип языка Форт состоит в том, чтобы не закрывать от программиста даже самые элементарные единицы, из которых строятся его более сложные слова, а предоставлять их наравне с другими словами. Элементарными словами для работы с памятью в словаре, помимо приведенных выше @ и ! , являются следующие:
HERE ---> A ALLOT A ---> , A --->
Предполагается, что словарь занимает некоторую начальную часть адресного форт-пространства и у него имеется указатель текущей вершины (словарь растет в сторону увеличения адресов). Слово HERE (здесь) возвращает текущее значение указателя (адрес первого свободного байта, следующего за последним занятым байтом словаря).
Слово ALLOT (распределить) резервирует в словаре область памяти, размер которой (в байтах) снимает со стека. Резервирование состоит в том, что текущее значение указателя изменяется на заданную величину, поэтому при положительном значении запроса память отводится вплотную от вершины словаря, а при отрицательном значении запроса происходит освобождение соответствующего участка памяти. Наконец, слово , (запятая) выполняет так называемую «компиляцию» значения, снимаемого со стека: значение переносится на вершину словаря, после чего указатель вершины продвигается на 2 (размер в байтах скомпилированного значения). Некоторые из приведенных слов легко выражаются через другие:
: , ( A --> ) HERE ! 2 ALLOT ; : 2@ ( A --> BB ) DUP 2 + @ SWAP @ ;
Такая избыточность позволяет программисту быстрее находить нужные ему решения и делает программы более удобочитаемыми.
А как создать в словаре поименованную область памяти? Можно завести область и связать ее адрес с именем через описание константы: HERE 10 ALLOT CONSTANT X10. Слово HERE оставляет на стеке адрес текущей вершины словаря, затем при исполнении текста 10 ALLOT от этой вершины резервируется 10 байт, после чего слово CONSTANT связывает адрес зарезервированной области с именем X10. В дальнейшем при исполнении слова X10 этот адрес будет положен на стек.
Другой возможный путь состоит в использовании слова CREATE (создать) --> в таком контексте: CREATE X10 10 ALLOT. Слово CREATE, подобно слову VARIABLE, выбирает из входной строки очередное слово и определяет его как новую команду с таким действием: положить на стек адрес вершины словаря на момент создания этого слова. Поскольку следующие действия в приведенном примере резервируют память, то слово X10 будет класть на стек адрес зарезервированной области. Очевидно, что слово VARIABLE можно выразить через CREATE
: VARIABLE ( ---> ) CREATE 2 ALLOT ;
или иначе (если мы хотим инициализировать нулем значение создаваемой переменной):
: VARIABLE ( ---> ) CREATE 0 , ;
В стандарте определен ряд системных переменных, к которым программист может свободно обращаться, в том числе STATE (состояние) --> А и BASE (основание) --> A. Исполнение каждого из этих слов заключается в том, что на стеке оставляется адрес ячейки, в которой хранится значение данной переменной.
Переменная STATE представляет текущее состояние текстового интерпретатора: нуль для исполнения и не нуль (обычно -1) для компиляции. Поэтому вся реализация слов [ и ] , переключающих интерпретатор из одного состояния в другое, сводится к одному присваиванию:
: [ ( ---> ) 0 STATE ! ; IMMEDIATE : ] ( ---> ) -1 STATE ! ;
Переменная BASE хранит текущее основание системы счисления для ввода и вывода чисел, поэтому реализация слов для установки стандартных систем выглядит так:
: DECIMAL ( ---> ) 10 BASE ! ; : HEX ( ---> ) 16 BASE ! ;
Отсюда следует более изящный способ кратковременной смены системы счисления во время компиляции определения: [ BASE @ HEX ] FF00 [ BASE ! ]. Сначала на стеке запоминается текущее основание, и система счисления переключается на основание 16, в котором и воспринимается следующее число FF00, после чего восстанавливается прежнее основание. А как узнать текущее основание системы счисления? Исполнение текста BASE @ . не поможет, поскольку ответом всегда будет 10 (почему?). Правильный ответ даст исполнение текста BASE @ DECIMAL . , в результате чего значение основания будет напечатано как число в десятичной системе. Еще более правильным было бы использовать текст BASE @ DUP DECIMAL . BASE ! , который после печати основания в десятичной системе восстанавливает его прежнее значение.
Литеры и строки, форматный вывод чисел
В современном программировании важное место занимает обработка текстовых данных. С каждой литерой, которую можно ввести с внешнего устройства или вывести на него, связывается некоторое число — код этой литеры, так что в памяти ЭВМ литеры представлены своими кодами. Стандарт языка Форт предусматривает использование таблицы кодов ASCII, в которой задействованы все числа в диапазоне от 0 до 127. Каждый код занимает один 8-разрядный байт, в котором для представления литеры используются младшие 7 разрядов.
Такая привязка к одной конкретной кодировке не является существенным препятствием к использованию других, если сохраняется условие, что код литеры занимает один байт. В применяемых в нашей стране форт-системах помимо ASCII применяются коды КОИ-7, КОИ-8, ДКОИ и другие.
Для доступа к однобайтным значениям, расположенным в памяти, используются слова C@ A-->B и C! B,A -->, которые аналогичны словам @ и !. Префикс С (от слова CHARACTER — литера) говорит о том, что эти слова работают с литерными кодами (однобайтными значениями).
Слово C@ возвращает содержимое байта по адресу A, дополняя его до 16-разрядного значения нулевыми разрядами. Обратное действие выполняет слово C!, которое засылает младшие 8 разрядов значения B в память по адресу A.
Для политерного обмена с терминалом стандарт предусматривает такие слова:
KEY ---> A EMIT A ---> CR ---> TYPE A,N ---> EXPECT A,N --->
Слово KEY (клавиша) возвращает в младших разрядах значения A — код очередной литеры, введенной с терминала. В отличие от слова C@ старшие разряды зависят от реализации и могут быть ненулевыми. Обратное действие выполняет слово EMIT (испустить), которое снимает значение со стека и, рассматривая его младшие разряды как код литеры, выводит эту литеру на терминал. Специальное слово CR (сокращение от CARRIAGE RETURN — возврат каретки) вынолняет перевод строки при выводе на терминал.
Расположенные в памяти побайтно коды литер образуют строку, которую можно напечатать на терминале словом TYPE (напечатать).
Это слово снимает со стека число — количество литер (оно должно быть неотрицательно) и адрес начала строки (ее первого байта):
: TYPE ( A,N ---> ) ?DUP IF 0 DO DUP I + C@ EMIT LOOP THEN DROP ;
Если число литер равно нулю, то ничего не печатается.
Обратное действие — ввод строки литер — выполняет слово ЕХРЕСТ (ожидать), которое снимает со стека длину и адрес области памяти для размещения вводимых литер. Коды литер, последовательно вводимых с терминала, помещаются в указанную область до тех пор, пока не будет введено заданное число литер или не будет введена управляющая литера «возврат каретки» (код этой литеры в память не заносится). Фактическое число введенных литер сообщается в стандартной переменной SPAN (размер), эти литеры к тому же отображаются на терминале.
Ввиду его особой важности для кодирования пробела выделена специальная константа BL (от BLANK — пробел), которую для кода ASCII можно задать так: 32 CONSTANT BL. При исполнении слова BL на стеке остается код пробела. Чтобы вывести пробел на терминал, имеются следующие стандартные слова:
: SPACE ( ---> ) BL EMIT ; : SPACES ( N ---> ) ?DUP IF 0 DO SPACE LOOP THEN ;
Слово SPACE (пробел) выводит на терминал один пробел, а слово SPACES (пробелы) — несколько, снимая их количество со стека (это значение, как и длина строки в слове TYPE, должно быть неотрицательным).
Внутри определений через двоеточие можно использовать явно заданные тексты для вывода их на терминал. При исполнении слова ." (точка и кавычка), употребленного в контексте ." текст ", следующие за ним литеры до закрывающей кавычки исключительно печатаются на терминале. Пробел, отделяющий слово .", в число печатаемых литер не входит. Другое слово .( (точка и скобка) отличается от ." тем, что ограничителем текста является закрывающая правая скобка, и это слово можно использовать как внутри определений, так и вне их.
Помимо строки — поля байт, длина которого задается отдельно — язык Форт использует строки со счетчиком.
Строка со счетчиком представляется полем байт, причем в первом байте записана длина строки. Стандарт не определяет форму представления счетчика длины, оставляя решение этого вопроса на усмотрение разработчиков конкретной реализации. Для перехода от строки со счетчиком к строке с явно заданной длиной имеется слово COUNT (счетчик) A --> B,N, которое преобразует адрес A строки со счетчиком в адрес B ее первой литеры (обычно это A+1) и значение счетчика. Строки со счетчиком используются при вводе слов из входной строки. Стандартное слово WORD (слово) C--> A снимает со стека код литеры-ограничителя и выделяет из входной строки подстроку, ограниченную этой литерой (начальные вхождения литеры-ограничителя пропускаются). Из выделенной подстроки формируется строка со счетчиком, адрес которой возвращается в качестве результата. Слова-команды языка Форт вводятся исполнением текста BL WORD, а текстовая строка в слове ." — исполнением текста QUOTE WORD, где слово QUOTE — константа, обозначающая код кавычки. Литеры введенной строки обычно располагаются вслед за вершиной словаря, т.е. в незащищенном месте, и поэтому их нужно как-то защитить, если предполагается их дальнейшее использование. Некоторые реализации предусматривают слово " (кавычка), которое используется внутри определения через двоеточие и во время его исполнения кладет на стек адрес следующей строки как строки со счетчиком. Это позволяет работать с явно заданными текстами.
Чтобы программист мог задавать коды литер, не связывая себя конкретной кодировкой, во многие реализации введено слово С", которое кладет на стек код первой литеры следующего слова и может использоваться как внутри определения через двоеточие, так и вне его:
: C" ( ---> C ) BL WORD COUNT DROP C@ [COMPILE] LITERAL ; IMMEDIATE
Исполнение текста BL WORD COUNT DROP C@ оставляет на стеке код первой литеры следующего слова. Далее этот код нужно либо скомпилировать как число, либо оставить на стеке в зависимости от текущего состояния текстового интерпретатора.
Для этого используется уже известное нам слово LITERAL. Однако включить его непосредственно в текст нельзя, так как это слово имеет признак немедленного исполнения и будет исполняться во время компиляции данного определения. Чтобы скомпилировать слово с признаком немедленного исполнения, используется слово [COMPILE] (от COMPILE — компилировать), которое само имеет такой признак. Оно принудительным образом компилирует следующее за ним слово независимо от наличия у него признака немедленного исполнения. Таким образом, ввод строки, ограниченной кавычкой, с помощью слова C" можно задать так: C" " WORD. Такой текст более нагляден, чем тот, в котором используется конкретный код или обозначающая его константа.
Важной областью применения строковых значений являются форматные преобразования, позволяющие переводить число из машинного двоичного представления в строку литер. Эти преобразования выполняются над числами двойной длины, результирующая строка размещается во временном буфере PAD (прокладка), который заполняется с конца. Такое название буфера связано с тем, что он располагается в незащищенной части адресного пространства между словарем и стеком. Слово PAD кладет на стек адрес конца этого буфера и обычно определяется так:
: PAD ( ---> А ) HERE 100 + ;
В данном случае предполагается, что размер буфера не будет превышать 100 байт.
Собственно форматное преобразование начинается словом <# которое устанавливает служебную переменную HLD на конец буфера PAD:
: <# ( ---> ) PAD HLD ! ;
Занесение очередной литеры в буфер PAD выполняет слово HOLD (сохранить):
: HOLD ( С ---> ) -1 HLD +! HLD @ C! ;
Преобразование числа выполняет слово # DD1 --> DD2, которое работает со значениями двойной длины. Параметр делится на текущее значение переменной BASE (основание системы счисления) и заменяется на стеке получившимся частным, а остаток переводится в литеру соответствующую ему как цифра в данной системе счисления, и через слово HOLD эта литера добавляется в буфер PAD.
Полный перевод числа выполняет слово #S:
: #S ( DD ---> 0,0 ) BEGIN # 2DUP D0= UNTIL ;
которое выделяет цифры числа последовательным делением, пока не получится нуль. Наконец, слово #> завершает форматное преобразование, возвращая адрес и длину получившейся текстовой строки:
: #> ( DD ---> A,N ) 2DROP HLD @ PAD OVER - ;
Для вывода знака «минус» имеется слово SIGN (знак):
: SIGN ( A ---> ) 0< IF C" - HOLD THEN ;
которое добавляет в буфер PAD знак «минус», если параметр на вершине стека (число одинарной точности) отрицателен.
С помощью перечисленных средств легко определить стандартные слова D. и . для печати чисел в свободном (минимальном) формате:
: D. ( DD ---> ) 2DUP DABS ( DD,DDABS ) <# #S ( DD,0,0 ) ROT ( D-МЛ,0,0,D-СТ ) SIGN ( D-МЛ,0,0 ) #> ( D-ML,A,N ) TYPE SPACE DROP ; : . ( N ---> ) S>D D. ;
Слово D. сначала переводит абсолютное значение исходного числа в строку литер, потом добавляет к ней возможный знак «минус», анализируя для этого старшую половину первоначального значения, и затем печатает получившуюся строку, выводя после нее еще один пробел. Слово . дополняет свой параметр до значения двойной длины распространением знакового разряда и обращается к слову D. для печати получившегося числа. Аналогичным образом реализуются стандартные слова D.R и .R , которые печатают число в поле заданного размера вплотную к его правому краю (отсюда в их мнемонике присутствует буква R от RIGHT — правый), добавляя при необходимости начальные пробелы:
: D.R ( DD:ЧИСЛО,F:РАЗМЕР ПОЛЯ ---> ) OVER 2SWAP DABS ( D-СТ,F,DD,DABS ) <# #S ROT SIGN #> ( F,A,N ) ROT OVER - ( A,N,F-A ) DUP 0> IF SPACES ELSE DROP THEN TYPE ; : .R (N:ЧИСЛО,F:РАЗМЕР ПОЛЯ ---> ) SWAP S>D D.R ;
В заключение рассмотрим программу шестнадцатиричиой распечатки областей памяти словом DUMP (дамп), которое получает на стеке адрес области и ее длину:
: DUMP ( A:АДРЕС,N:ДЛИНА ---> ) OVER BASE @ HEX 2SWAP ( A,B,A,N ) + ROT -2 AND ( B,A+N,A ) DO I <# C" * HOLD ( B,AI ) 0 15 DO DUP I + ( B,AI,AI+J ) C@ DECODE HOLD -1 +LOOP ( B,AI ) C" * HOLD ( B,AI ) 0 14 DO BL HOLD DUP ( B,AI,AI+J ) @ 0 # # 2DROP -2 +LOOP ( B,AI ) BL HOLD BL HOLD 0 # # # # #> ( B,AT,NT ) CR TYPE 16 +LOOP BASE ! ;
Внешний цикл с шагом 16 формирует и печатает текстовую строку. Первый внутренний цикл с шагом -1 засылает в буфер PAD литерные значения, соответствующие распечатываемым байтам. Здесь слово DECODE C --> C/C1 заменяет код C на некоторый код C1 (например, код литеры «точка»), если он не является кодом литеры, которую можно напечатать на данном терминале. Второй внутренний цикл с шагом -2 засылает в буфер четыре шестнадцатиричные цифры — представления двухбайтных значений, разделяя их одним пробелом. Далее в буфере PAD (т.е. в начале строки) формируется адрес тоже в виде четырехзначного числа. Перед началом работы устанавливается шестнадцатиричная система счисления, а в конце восстанавливается первоначальная. Следующий протокол работы показывает результат исполнения слова DUMP в конкретном случае:
> 1000 40 DUMP 03E8 03C0 03EC 45E0 A220 0003 4520 A390 07FA *...Ж..s..,..TM.3* 03F8 04C5 D4C9 E300 03E4 0402 9180 A331 4780 *.EMIT..U..JЦT..B* 0408 A414 45E0 A230 0004 4520 A37A 9180 A330 *U...S.....T:JЦT.*
Обратите внимание, что адреса и значения байтов напечатаны в шестнадцатиричной системе. Точки в литерном представлении байтов заменяют литеры, которые не могут быть напечатаны.
Логические операции
В языке Форт имеется только один тип значений — 16-разрядные двоичные числа, которые, как мы видели, рассматриваются в зависимости от ситуации как целые числа со знаком или как адреса и т. д. Точно так же подходят и к проблеме представления логических значений ИСТИНА и ЛОЖЬ: число 0, в двоичном представлении которого все разряды нули, представляет значение ЛОЖЬ, а любое другое 16-разрядное значение понимается как ИСТИНА. Вместе с тем стандартные слова, которые должны возвращать в качетве результата логическое значение, из всех возможных представлений значения ИСТИНА используют только одно: число -1 (или, что то же самое, 65535), в двоичном представлении которого все разряды единицы. Такое соглашение связано с тем, что традиционные логические операции конъюнкции, дизъюнкции и отрицания выполняются в Форте поразрядно над всеми шестнадцатью разрядами операндов:
AND A,B ---> A B логическое И OR A,B ---> A B логическое ИЛИ XOR A,B ---> A B исключающее ИЛИ NOT A ---> ^ A логическое НЕ
Как и в предыдущих случаях, эти операции не являются независимыми: операция отрицания (поразрядное инвертирование) легко выражается через исключающее ИЛИ (поразрядное сложение по модулю два):
: NOT ( A --> ^A ) -1 XOR ;
Нетрудно увидеть, что для принятого в Форте стандартного представления значений ИСТИНА и ЛОЖЬ все эти слова работают, как обычные логические операции.
Логические значения возникают в операциях сравнения, которые входят в обязательный набор слов и имеют общепринятую программистскую мнемонику:
< A,B ---> A < B меньше = A,B ---> A = B равно > A,B ---> A > B больше
Эти операции снимают со стека два врехних значения, сравнивают их как числа со знаком (операция «равно» выполняет поразрядное сравнение) и возвращают результат сравнения как значение ИСТИНА или ЛОЖЬ в описанном выше стандартном представлении. Из-за стремления к минимизации обязательного набора операций в него не включены слова для операций смешанного сравнения, поскольку их легко выразить через уже имеющиеся:
: <= ( A,B ---> A <= B ) SWAP < NOT ; : >= ( A,B ---> A >= B ) SWAP > NOT ; : <> ( A,B ---> A <> B ) = NOT ;
Для сравнения 16- разрядных чисел без знака имеется слово U< A,B --> A < B. Эта операция обычно используется для сравнения адресов, которые лежат в диапазоне от 0 до 65535. Буква U (от UNSIGNED — беззнаковый) в ее мнемонике говорит о том, что операнды рассматриваются как числа без знака.
Ввиду частого использования и возможности непосредственной реализации на многих существующих ЭВМ в обязательный набор слов включены одноместные операции сравнения с нулем:
0< A ---> A < 0 0= A ---> A = 0 0> A ---> A > 0
При этом слово 0= можно использовать вместо NOT как операцию логического отрицания, и в отличие от NOT оно будет правильно работать при любых представлениях логического значения ИСТИНА.
Описанные выше двухместные операции сравнения естественным образом выражаются через сравнения с нулем:
: < ( A,B ---> A < B ) - 0< ; : = ( A,B ---> A = B ) - 0= ; : > ( A,B ---> A > B ) - 0> ;
Стандартное расширение двойных чисел имеет аналогичные слова для сравнения 32-разрядных значений:
D0= AA ---> AA = 0 D< AA,BB ---> AA < BB D= AA,BB ---> AA = BB DU< AA,BB ---> AA < BB
Слова D< и DU< различаются тем, что первое рассматривает свои операнды как числа со знаком, а второе — как числа без знака. Для слов D0= и D= такое различие несущественно, их, например, можно определить так:
: D0= ( AA ---> AA = 0 ) OR 0= ; : D= ( AA,BB ---> AA = BB ) D- D0= ;
Слово OR (логическое ИЛИ) в определении слова D0= логически складывает старшую и младшую половины исходного 32-разрядного значения. Нулевой результат будет получен тогда и только тогда, когда исходное значение было нулевым. Следующее слово 0= преобразует этот результат к логическому значению в стандартном представлении. Исполнение слова D= состоит в вычислении разности его операндов в сравнении этой разности с нулем.
Определяющие слова
Конструкции языка Форт, которые мы рассматривали до сих пор, имеют аналоги в других известных языках программирования. Например, определению через двоеточие очевидным образом соответствует описание процедуры в языках Фортран и Паскаль. Теперь мы рассмотрим свойство языка Форт, которое существенно отличает его от других и в значительной степени определяет его как нечто новое.
Программируя какую-либо задачу, мы моделируем понятия, в которых эта задача формулируется и решается, через понятия данного языка программирования. Традиционные языки имеют определенный набор понятий (процедуры, переменные, массивы, типы данных, исключительные ситуации и т.д.), с помощью которых программист должен выразить решение исходной задачи. Этот набор выразительных средств фиксирован в каждом языке, но поскольку он содержит такие универсальные средства, как процедуры и типы данных, то опытный программист может смоделировать любые необходимые ему понятия программирования.
Язык Форт предлагает вместо фиксированного набора порождающих понятий единый механизм порождения таких порожающих понятий. Таким образом, приступая к программированию задачи на языке Форт, программист определяет необходимые ему понятия и с их помощью решает поставленную задачу. Такое прямое введение в язык нужных для данной задачи средств вместо их моделирования (часто весьма сложного) через имеющиеся универсальные средства уменьшает разрыв между постановкой задачи и ее программной реализацией. Это упрощает понимание и отладку программы, так как в ней более наглядно проступают объекты и отношения исходной задачи, и вместе с тем повышает ее эффективность, так как вместо сложного моделирования понятий задачи через универсальные используется их непосредственная реализация через элементарные.
Новые понятия вводятся посредством определения через двоеточие, в теле которого используются слова
CREATE ---> DOES> ---> (компиляция) ---> A (исполнение)
Рассмотрим уже известное нам слово CONSTANT (константа), которое используется для определения констант.
Его определение можно задать так:
: CONSTANT ( N ---> ) CREATE , DOES> @ ;
Часть определения от слова CREATE до DOES> называется создающей (CREATE — создать), остальная часть от слова DOES> и до конца называется исполняющей (DOES — исполняет). В данном случае создающая часть состоит из одного слова , (запятая), а исполняющая часть — из слова @ (разыменование).
Рассмотрим исполнение данного определения на примере 4 CONSTANT XOP. Слово 4 кладет число 4 на стек. Далее исполняется слово CONSTANT. Слово CREATE, с которого начинается его определение, выбирает из входной строки очередное слово (в данном случае XOP) и добавляет его в словарь как новую команду. Создающая часть, состоящая из слова «запятая», переносит число 4 в память, компилируя его на вершину словаря. Слово DOES>, отмечающее конец создающей части, завершает исполнение данного определения, при этом семантикой созданного слова XOP будет последовательность действий исполняющей части, начиная от слова DOES>. В дальнейшем исполнение слова XOP начнется с того, что слово DOES> положит на стек адрес вершины словаря, какой она была на момент начала работы создающей части, после чего будет работать исполняющая часть определения. Поскольку по данному адресу создающая часть скомпилировала число 4, то исполняющая часть — разыменование — заменит на стеке этот адрес его содержимым, т.е. числом 4, что и требуется по смыслу данного понятия.
Рассмотрим другой пример. Введем понятие вектора. При создании вектора будем указывать размер (число элементов), а при обращении к нему — индекс (номер) элемента, в результате чего получается адрес данного элемента. Этот адрес можно разыменовать и получить значение элемента или можно заслать по этому адресу новое значение. Если желательно контролировать правильность индекса при обращении к вектору, то определение может выглядеть так:
: ВЕКТОР ( N:PA3MEP ---> ) CREATE DUP , 2* ALLOT DOES> ( I:ИНДЕКС,A ---> A[I]:АДРЕС ЭЛ-ТА I) OVER 1- OVER @ U< ( ПРОВЕРКА ИНДЕКСА) IF SWAP 2* + EXIT THEN ." ОШИБКА В ИНДЕКСЕ" ABORT ;
Разберем, как работает данное определение при создании вектора 10 ВЕКТОР X.
Создающая часть компилирует размер вектора и вслед за этим отводит память на 10*2, т.е. 20 байт. Таким образом, для вектора X в словаре отводится область размером 22 байта, в первых двух байтах которой хранится число 10 — размер вектора. При обращении к вектору X на стеке должно находиться значение индекса. Слово DOES> кладет сверху адрес области, сформированной создающей частью, после чего работает исполняющая часть определения. Проверив, что индекс I лежит в диапазоне от 1 до 10, она оставляет на стеке адрес, равный начальному адресу области плюс I*2, т.е. адрес I-го элемента вектора, если считать, что элементы располагаются в зарезервированной области подряд. Слово EXIT (выход) завершает исполнение определения, что позволяет обойтись без части «иначе» в условном операторе. Если окажется, что индекс не положителен или больше числа элементов, то будет напечатано сообщение «ошибка в индексе» словом .", и исполнение закончится через слово ABORT (выброс). Если по каким-либо причинам контроль индексов не нужен, можно дать более краткое определение:
: ВЕКТОР ( N:PA3MEP ---> ) CREATE 2 * ALLOT DOES> ( I:ИНДЕКС,A ---> A[I]:АДРЕС ЭЛ-ТА I) SWAP 1- 2 * + ;
Если мы условимся считать индексы не от единицы, а от нуля, то исполняющая часть еще более сократится за счет исключения слова 1- для уменьшения значения индекса на единицу.
Таким образом, программист может реализовывать варианты понятий, наиболее подходящие для его задачи. Исходный небольшой набор слов-команд форт-системы он может избирательно наращивать в нужном направлении, постоянно совершенствуя свой инструментарий.
Используемый в языке Форт способ введения определяющих слов связан с очень важным понятием — частичной параметризацией. Определяющее слово задает целый класс слов со сходным действием, которое описывается исполняющей частью определяющего слова. Каждое отдельное слово из данного класса характеризуется результатом исполнения создающей части — тем или иным содержимым связанной с ним области памяти, адрес которой передается исполняющей части как параметр.Таким образом, исполняющая часть — то общее, что характеризует данный класс слов, — во время ее исполнения частично параметризуется результатом исполнения создающей части для данного отдельного представителя этого класса. Как создающая часть, так и частично параметризованная исполняющая часть, могут требовать дополнительных параметров для своего исполнения (в примере для вектора это размер вектора и индекс). Все это представляет программисту практически неограниченную свободу в создании новых понятий и удобных инструментальных средств.
Основные понятия
Приступая к изучению нового для нас языка программирования, мы прежде всего задаемся вопросами: какие конструкции есть в этом языке (какова морфология), как они записываются (каков синтаксис) и что означают (какова семантика). Например, в широко распространенном языке Паскаль имеется около двадцати конструкций (идентификатор, число без знака, присваивание, условный оператор и др.), синтаксис которых обычно задают с помощью граф-схем или порождающих правил, а семантику объясняют на основе той или иной машиннонезависимой модели вычислений. Часть языка ассемблера любой ЭВМ, предназначенная для записи машинных команд, содержит по одной конструкции на каждую команду. Запись такой конструкции обычно представляет отдельную строку и состоит из мнемонического обозначения команды и размещения операндов, а семантика определяется в терминах реальных действий, которые данная команда выполняет над ячейками памяти, регистрами и другими компонентами архитектуры ЭВМ.
Язык Форт больше всего похож на язык ассемблера. Его синтаксис также максимально прост. Запись каждой конструкции (команды) состоит из одного слова — мнемонического обозначения, в качестве которото может выступать последовательность любых литер, не содержащая пробела. Простота синтаксиса является следствием того, что в качестве вычислительной модели используется стековая машина. Слова-команды этой машины снимают необходимые операнды со стека и оставляют свои результаты (если они есть) также на стеке. Таким образом, программа, написанная на языке Форт, выглядит как последовательность слов, каждое из которых подразумевает выполнение тех или иных действий. Слова разделяются любым числом пробелов и переходов на новую строку; ограничение накладывается только на длину слова — оно должно содержать не более 31 литеры. Стандарт языка определяет сравнительно небольшой набор из 132 «обязательных» слов. Среди них есть слова, позволяющие определять новые через уже имеющиеся и тем самым расширять исходный набор слов-команд в нужном для данной задачи направлении.
Некоторые часто требующиеся расширения включены в стандарт в качестве «стандартных расширений» обязательного набора слов.
Вычислительная модель, лежащая в основе языка Форт, состоит из адресного пространства оперативной памяти объемом до 64 Кбайт, терминала и поля внешней памяти на магнитных дисках объемом до 32768 блоков по 1 Кбайт каждый. В пределах имеющегося адресного пространства располагаются стек данных и стек возвратов, словарь, буфер для ввода с терминала и буфера для обмена с внешней памятью.
Стек данных обычно располагается в старших адресах оперативной памяти и используется для передачи параметров и результатов между исполняемыми словами. Его элементами являются двухбайтные значения, которые в зависимости от ситуации могут рассматриваться различным образом: как целые числа со знаком в диапазоне от -32768 до +32767, как адреса оперативной памяти в диапазоне от 0 до 65535 (отсюда ограничение 64 К на размер адресного пространства), как коды литер (диапазон зависит от принятой кодировки) для обмена с терминалом, как номера блоков внешней памяти в диапазоне от 0 до 32767 или просто как 16-разрядные двоичные значения. В процессе исполнения слов значения помещаются на стек и снимаются с него. Переполнение и исчерпание стека, как правило, не проверяется; его максимальный объем устанавливается реализацией. Стандарт предусматривает, что стек растет в сторону убывания адресов; это согласуется с аппаратной реализацией стека в большинстве ЭВМ, которые ее имеют.
Стек возвратов по своей структуре аналогичен стеку данных, но используется особым образом некоторыми стандартными словами (подробнее об этом см. в ).
Начальную часть адресного пространства обычно занимает словарь (иначе «кодофайл») — хранилище слов и данных. По мере расширения исходного набора слов словарь растет в сторону увеличения адресов. Специальные слова из обязательного набора позволяют управлять вершиной словаря — поднимать и опускать ее.
Наряду со стеком данных и стеком возвратов в старших адресах оперативной памяти обычно размещается буфер на 64–100 байт для построчного ввода форт-текста с терминала и буферный пул для обмена с внешней дисковой памятью размером от 1 до 3 и более Кбайт.Доступ к этим буферам и фактический обмен осуществляют специальные слова из обязательного набора.
Работа в диалоговом режиме
Программирование на языке Форт является существенно диалоговым. Работая за терминалом, программист вводит слова-команды, а загруженная в память ЭВМ форт-система, т.е. реализация языка Форт на данной ЭВМ, немедленно выполняет обозначаемые этими словами действия. О своей готовности к обработке очередной строки текста форт-система обычно сообщает программисту специальным приглашением (например, знаком > , который печатается на терминале). Получив такое приглашение, программист набирает на терминале очередную порцию форт-текста, заканчивая ее специальным управляющим символом (например, нажимая клавишу «Ввод» или «Перевод строки»). Получив сигнал о завершении ввода, форт-система начинает обработку введенного текста (он размещается в буфере для ввода с терминала), выделяя в нем слова-команды и исполняя их. Успешно обработав весь введенный текст, форт-система вновь приглашает программиста к вводу, и описанный цикл диалога повторяется. Многие форт-системы после успешного завершения обработки выводят на терминал подтверждающее сообщение (обычно ОК — сокращение от английского o'kay — все в порядке). Если во время обработки введенного текста выявляется какая-либо ошибка (например, встретилось неизвестное форт-системе слово), то на терминал выводится поясняющее сообщение, обработка введенного текста прекращается и форт-система приглашает программиста к вводу нового текста.
Для завершения работы обычно предусматриваются специальные слова-команды.
Непосредственно вводить с терминала большие форт-тексты неудобно, поэтому их хранят во внешней памяти на дисках, а с терминала программист вводит только слова-команды, отсылающие форт-систему к обработке тех или иных блоков из внешней памяти Для создания и исправления форт-текстов во внешней памяти используется текстовый редактор, который является специализированным расширением форт-системы.
Стек данных и вычисления
Как уже говорилось, в основе вычислительной модели для языка Форт лежит стековая машина. Ее команды (слова в языке Форт) обычно используют в качестве своих операндов верхние элементы стека, убирая их со стека и возвращая результаты (если они есть) на место операндов Как правило, слова используют одно-два верхних значения на стеке. Для их описания будем применять следующую диаграмму:
имя вершина стека до ---> вершина стека после слова исполнения слова исполнения слова
При этом считаем, что самое верхнее значение в стеке (последнее добавленное) находится справа.
Для работы с собственно вершиной стека имеются следующие слова:
DUP A ---> A,A DROP A ---> OVER A,B ---> A,B,A ROT A,B,C ---> B,C,A SWAP A,B ---> B,A
Слово DUP (от DUPLICATE — дублировать) дублирует вершину стека, добавляя в стек еще одно значение, равное тому, которое было до этого верхним. Слово DROP (сбросить) убирает верхнее значение. Слово OVER (через) дублирует значение, лежащее на стеке непосредственно под верхним. Слово ROT (от ROTATE — вращать) циклически переставляет по часовой стрелке три верхних значения в стеке. Наконец, слово SWAP (обменять) меняет местами два верхних значения.
Можно работать с любым элементом стека с помощью слов
PICK An,An-1,...Ao,n ---> An,An-1,...Ao,An ROLL An,An-1,...Ao,n ---> An-1,...Ao,An
Слово PICK (взять) дублирует n-й элемент стека (считая от нуля), так что 0 PICK равносильно DUP, а 1 PICK равносильно OVER. Слово ROLL (повернуть) циклически переставляет n верхних элементов стека (тоже считая от нуля) по часовой стрелке, так что 2 ROLL равносильно ROT, 1 ROLL равносильно SWAP, а 0 ROLL является пустой операцией.
Чтобы «увидеть» верхнее значение на стеке, используется слово . (точка) А -->, которое снимает значение с вершины стека и печатает его на терминале как целое число в свободном формате (т.е. без ведущих нулей и со знаком минус, если число отрицательное). Вслед за последней цифрой числа слово-точка выводит один пробел, чтобы выводимые подряд числа не сливались в сплошной ряд цифр.
Если программист хочет, чтобы напечатанное значение осталось на стеке, он должен исполнить текст DUP .. Слово DUP создаст копию верхнего значения, а точка ее распечатает и уберет со стека.
Перечисленные выше слова работают со значениями, уже находящимися в стеке. А как занести значение в стек? Язык Форт имеет следующее замечательное правило умолчания: если введенное слово форт-системе не известно, то прежде чем сообщать программисту об ошибке, форт-система пытается понять это слово как запись числа. Если слово состоит из одних цифр с возможным начальным знаком минус, то ошибки нет: слово считается известным и его действие состоит в том, что данное число кладется на вершину стека.
Теперь у нас достаточно средств, чтобы привести примеры диалога. Рассмотрим следующий протокол работы:
> 5 6 7 OK > SWAP . . . 6 7 5 ОК
В ответ на приглашение к вводу (знак >, печатаемый системой) программист вводит три числа: 5, 6 и 7. Обрабатывая введенный текст, форт-система кладет эти числа в указанном порядке на стек и по завершении обработки выводит подтверждающее сообщение OK и вновь приглашает программиста к вводу. Далее программист вводит текст из четырех слов: SWAP и три точки. Исполняя эти слова-команды, форт-система меняет местами два верхних элемента стека (5, 6, 7 -> 5, 7, 6) и затем поочередно три раза снимает верхнее значение со стека и печатает его. В результате на терминале появляется текст 6 7 5 и сообщение ОК, указывающее на завершение обработки, после чего система вновь выдает программисту приглашение на ввод.
Для внешнего представления чисел используется система счисления, задаваемая программистом. Стандарт языка предусматривает следующие слова для переключения в наиболее общеупотребительные системы:
DECIMAL ---> десятичная HEX ---> шестнадцатеричная OCTAL ---> восьмиричная
Первоначально устанавливается десятичная система. Если в процессе работы будет исполнено, например, слово HEX (от HEXADECIMAL — шестнадцатиричная), то при дальнейшем вводе и выводе чисел будет использоваться шестнадцатиричная система с цифрами от 0 до 9 и от A до F до тех пор, пока основание системы счисления не будет вновь изменено.
Внутренним же представлением чисел является обычный двоичный дополнительный код, применяемый в большинстве существующих ЭВМ.
Слова-команды, выполняющие арифметические операции над числами, являются общепринятыми математическими обозначениями:
+ A,B ---> сумма A+B - A,B ---> разность A-B * A,B ---> произведение A*B / A,B ---> частное от A/B MOD A,B ---> остаток от A/B /MOD A,B ---> остаток от A/B, частное от A/B ABS A ---> абсолютная величина A NEGATE A ---> значение с обратным знаком -A 1+ A ---> A+1 1- A ---> A-1 2+ A ---> A+2 2- A ---> A-2 2/ A ---> частное от A/2
При сложении, вычитании и умножении не учитывается возможность переполнения, в случае его возникновения используются младшие 16 разрядов результата. Такая арифметика называется арифметикой по модулю 65536 (2 в степени 16); ее основное достоинство состоит в том, что она дает одинаковые в двоичном представлении результаты независимо от того, как понимаются операнды: как числа со знаком в диапазоне от -32768 до +32767 или как числа без знака в диапазоне от 0 до 65535.
Операции деления / , MOD и /MOD рассматривают свои операнды как числа со знаком. Из нескольких известных математических определений деления с остатком (которые по-разному трактуют случаи, когда операнды имеют разные знаки или оба отрицательны) язык Форт использует так называемое деление с нижней границей: остаток имеет знак делителя или равен нулю, а частное округляется до его арифметической нижней границы («пола») []. Во многих ЭВМ, имеющих аппаратную реализацию деления, применяются другие правила для определения частного и остатка, однако это обычно не вызывает трудностей при программировании, поскольку самый важный случай с неотрицательными операндами все определения трактуют одинаково.
При выполнении деления возможно возникновение ошибочной ситуации, если делитель — нуль или частное не умещается в 16 разрядов (переполнение, возникающее при делении -32768 на -1).
Одноместные операции ABS и NEGATE игнорируют переполнение, возникающее в том единственном случае, когда операндом является число -32768, возвращая в качестве результата 0.
Наконец, одноместные операции 1+, 1-, 2+, 2- выполняют действие, отраженное в их мнемонике: увеличение или уменьшение значения на вершине стека на 1 или 2; аналогично слово 2/ возвращает частное от деления своего параметра на 2. Эти слова включены в стандарт ввиду частого использования соответствующих действий.
Использование стека для хранения промежуточных значений естественным образом приводит к так называемой «обратной польской форме» — одному из способов бесскобочной записи арифметических выражений, подразумевающему постановку знака операции после операндов. Например, выражение (A/B+C)*(D*E-F*(G-H)) записывается следующим образом: A B / C + D E * F G H - * - *. Очевидно, что этот текст выполним для Форта, если A, B и т.д. — слова, которые кладут на стек по одному числу. Таким образом, форт-систему можно использовать как калькулятор. Чтобы вычислить, например, значение (25+18+32)*5, достаточно ввести такой текст: 25 18 + 32 + 5 * .. В ответ система напечатает (исполняя точку) ответ: 375.
Чтобы повысить точность вычислений в последовательности умножение-деление, стандарт предусматривает два необычных слова:
*/ A,B,C ---> частное от (A*B/C) */MOD A,B,C ---> остаток, частное от (A*B/C)
Особенность этих слов состоит в том, что промежуточный результат А*В вычисляется с двойной точностью, и в качестве делимого для С используются все его 32 разряда. Окончательные же результаты являются 16-разрядными числами.
Наряду с описанной выше 16-разрядной арифметикой, язык Форт имеет полный набор средств для работы с 32-разрядными целыми числами через стандартное расширение двойной точности. Внутренним представлением таких чисел является 32-разрядный двоичный дополнительный код, представляющий их как числа со знаком в диапазоне от -2147483648 до +2147483647 или как числа без знака в диапазоне от 0 до 4294967295. При размещении в стеке числа двойной точности занимает два элемента: верхний — старшая половина, предыдущий — младшая.
Такое расположение делает простым переход от двойной точности к обычной через слово DROP. Расширение двойных чисел включает следующие слова:
2DROP AA ---> 2DUP AA ---> AA,AA 2OVER AA,BB ---> AA,BB,AA 2ROT AA,BB,CC ---> BB,CC,AA 2SWAP AA,BB ---> BB,AA D. AA ---> D+ AA,BB ---> сумма AA+BB D- AA,BB ---> разность AA-BB DABS AA ---> абсолютная величина AA DNEGATE AA ---> число с обратный знаком -AA
Здесь обозначение типа AA подчеркивает, что значение занимает два элемента стека. Хотя стандартное расширение этого не предусматривает, во многих реализациях языка Форт этот ряд продолжают операции умножения и деления:
D* AA,BB ---> произведенме AA*BB D/ AA,BB ---> частное от AA/BB DMOD AA,BB ---> остаток от AA/BB
Операндами и результатами перечисленных слов являются значения двойной длины, занимающие по два элемента стека каждый; это обстоятельство отражено в мнемонике, начинающейся с цифры 2, когда два элемента стека выступают как одно целое, или с буквы D (от слова DOUBLE — двойной), когда речь идет арифметическом значении двойной длины.
Следующие два слова являются переходными между арифметическими операциями одинарной и двойной точности; их мнемоника включает букву M (от слова MIX — смесь) и U (от слова UNSIGNED — беззнаковый):
UM* A,B ---> CC UM/MOD AA,B ---> C,D
Слово UM* перемножает операнды A и B как 16-разрядные числа без знака, возвращая все 32 разряда получившегося произведения. Слово UM/MOD рассматривает 32-разрядное делимое AA и 16-разрядный делитель B как числа без знака и возвращает получающиеся 16-разрядные остаток C и частное D. Если делитель нуль или частное превышает 65535, то это рассматривается как ошибка. Для перехода к двойной точности с учетом знака многие реализации имеют слово S>D A --> AA, которое расширяет исходное число A до числа двойной точности распространением знакового разряда.
Чтобы при вводе различать числа двойной и одинарной точности, в сформулированное выше правило умолчания внесена оговорка: если не найденное в словаре слово состоит только из цифр с возможным начальным знаком минус, то это число одинарной точности, а если в слово входят точки (в любом месте), то это число двойной длины.Пример использования форт-системы как калькулятора для работы с числами двойной длины представляет следующий протокол работы:
> 1234567. 7654321. D+ D. 8888888 ОК
В ответ на приглашение (знак > ) программист вводит два числа двойной длины, операцию сложения этих чисел и операцию печати результата. Выполняя указанные действия, форт-система печатает ответ (заметьте, что он уже не содержит точки) и подтверждающее сообщение ОК.
Структуры управления
Во всех приводившихся выше определениях слов тело определения записывалось как последовательность уже известных слов-команд; семантика определяемого таким образом слова состоит в последовательном выполнении слов-команд тела. Помимо последовательного исполнения традиционными приемами в программировании стали ветвление (выбор между разными последовательностями действий) и цикл (многократное повторение одной последовательности действий).
В языке Форт тоже имеются условные операторы и циклы, реализованные с помощью специальных слов-команд, которые легко выражаются через другие, более элементарные слова (см. ). Это открывает путь к реализации таких вариантов структур управления, которые больше всего подходят для данной задачи, что дает программисту широкие возможности для создания новых структур управления.
Стандарт языка предусматривает ряд слов для построения условных операторов и циклов в некотором конкретном виде. Эти слова используются внутри определений через двоеточие и разделяют тело определения на отрезки. Действия, соответствующие словам из этих отрезков, выполняются, не выполняются или выполняются многократно в зависимости от условий, проверяемых во время выполнения данного определения. Условные операторы и циклы могут свободно вкладываться друг в друга.
Условный оператор строится с помощью слов:
IF А ---> (исполнение) ELSE ---> (исполнение) THEN ---> (исполнение)
Внутри определения через двоеточие отрезок текста IF <часть-то> ELSE <часть-иначе> THEN задает следующую последовательность действий. Слово IF (если) снимает значение с вершины стека и рассматривает его как логическое. Если это ИСТИНА (любое ненулевое значение), то выполняется часть «то» — слова, находящиеся между IF и ELSE, а если ЛОЖЬ (равно нулю), то исполняется часть «иначе» — слова между ELSE и THEN. Сами слова ELSE (иначе) и THEN (то) играют роль ограничителей для слова IF и самостоятельной семантики не имеют. Часть «иначе» вместе со словом ELSE может отсутствовать, и тогда условный оператор имеет сокращенную форму IF <часть-то> THEN.
Если логическое значение, снимаемое со стека словом IF, ИСТИНА, то выполняются слова, составляющие часть «то», а если ЛОЖЬ, то данный оператор не выполняет никаких действий. Обратите внимание, что условие для слова IF вычисляется предшествующими словами.
Для примера рассмотрим определение слова ABS, вычисляющего абсолютное значение числа:
: ABS ( A --->абс A) DUP 0< IF NEGATE THEN ;
Слово DUP дублирует исходное значение, следующее слово 0< проверяет его знак, заменяя копию на логическое значение — результат проверки. Слово IF снимает со стека этот результат, и если это ИСТИНА, то лежащее на стеке исходное отрицательное значение словом NEGATE заменяется на противоположное.
Еще пример: стандартное слово ?DUP дублирует верхнее значение, если это не ноль, и оставляет стек в исходном состоянии, если на вершине ноль:
: ?DUP ( A ---> A,A/0 ) DUP IF DUP THEN ;
В спецификации данного слова косая черта разделяет два варианта результата, который это слово может оставить на стеке. Примером использования полного условного оператора может служить определение слова S>D, расширяющего исходное значение до значения двойной длины распространением знакового разряда:
: S>D ( A ---> AA ) DUP 0< IF -1 ELSE 0 ТНЕN ;
Это слово добавляет в стек -1, если число на вершине стека отрицательно, или 0 в противном случае. Таким образом, выполняется распространение знакового разряда на старшую половину значения двойной точности.
В стандарт языка Форт включены циклы с условием и циклы со счетчиком. Циклы первой группы образуются с помощью слов
BEGIN ---> (исполнение) UNTIL A ---> (исполнение) WHILE A ---> (исполнение) REPEAT ---> (исполнение)
и имеют две формы:
BEGIN <тело> UNTIL BEGIN <тело-1> WHILE <тело-2> REPEAT
В обоих случаях цикл начинается словом BEGIN (начать), которое служит открывающей скобкой, отмечающей начало цикла, и во время счета не выполняет никаких действий.
Цикл BEGIN-UNTIL называется циклом с проверкой в конце.
После исполнения слов, составляющих его тело, на стеке остается логическое значение — условие завершения цикла. Слово UNTIL (пока не) снимает это значение со стека и анализирует его. Если это ИСТИНА (не нуль), то исполнение цикла завершается, т.е. далее будут исполняться слова, следующие за UNTIL, а если это ЛОЖЬ (нуль), то управление возвращается к началу цикла от слова BEGIN. Например, определение слова, вычисляющего факториал, может выглядеть так:
: ФАКТОРИАЛ ( N ---> N! ВЫЧИСЛЕНИЕ N ФАКТОРИАЛ) DUP 2 < IF DROP 1 ( 1 ЕСЛИ N<2, ТО N!=1) ELSE ( N ИНАЧЕ ) DUP ( S,K S=N,K=N ) BEGIN ( S,K ) 1- ( S,K' K'=K-1 ) SWAP OWER ( K',S,K' ) * SWAP ( S',K' S'=S*К' ) DUP 1 = ( S',K',К'=1 ) UNTIL ( S',1 S'=N! ) DROP THEN ; ( N! )
Как и ранее, в комментариях, сопровождающих каждую строчку текста, мы указываем значения, которые остаются на вершине стека после ее исполнения. Такое документирование облегчает понимание программы и помогает при ее отладке.
Цикл с проверкой в начале BEGIN-WHILE-REPEAT используется, когда в цикле есть действия, которые не надо выполнять в заключительной итерации. Исполнение слов, составляющих его тело-1, оставляет на стеке логическое значение — условие продолжения цикла. Слово WHILE (пока) снимает это значение со стека и анализирует его. Если это ИСТИНА (не нуль), то исполняются слова, составляющие тело-2 данного цикла до ограничивающего слова REPEAT (повторять), после чего вновь исполняется тело-1 от слова BEGIN. Если же значение условия ЛОЖЬ (нуль), то исполнение данного цикла завершается и начинают выполняться слова, следующие за REPEAT. Заметьте, что в отличие от цикла BEGIN-UNTIL, значение ИСТИНА соответствует продолжению цикла. Для примера рассмотрим программу вычисления наибольшего общего делителя по алгоритму Евклида:
: НОД ( A,B ---> C:НАИБОЛЬШИЙ ОБЩИЙ ДЕЛИТЕЛЬ) 2DUP < IF SWAP THEN ( ТЕПЕРЬ A>=B ) BEGIN DUP ( A,B,B ) WHILE ( ПОКА B НЕ НОЛЬ ) 2DUP MOD ( A,B,C:ОСТАТОК ) ROT ( B,C,A ) DROP ( A',B' A'=B,B'=C ) REPEAT DROP ; ( НОД )
Для организации циклов с целочисленной переменной — счетчиком цикла — используются слова
DO A,B ---> (исполнение) LOOP ---> (исполнение) +LOOP A ---> (исполнение) I ---> A (исполнение) J ---> A (исполнение) LEAVE ---> (исполнение)
Такие циклы записываются в одной из следующих двух форм: DO <тело> LOOP или DO <тело> +LOOP. В обоих случаях цикл начинается словом DO (делать), которое снимает со стека два значения: начальное (на вершине стека) и конечное (второе сверху) — и запоминает их. Текущее значение счетчика полагается равным начальному значению, после чего исполняются слова, составляющие тело цикла. Слово LOOP увеличивает текущее значение счетчика на единицу и проверяет условие завершения цикла. В отличие от него, слово +LOOP прибавляет к текущему значению счетчика значение шага, которое вычисляется на стеке телом цикла и рассматривается как число со знаком. В обоих случаях условием завершения цикла является пересечение границы между A–1 и A при переходе от прежнего значения счетчика к новому (направление перехода определяется знаком шага), где A — конечное значение, снятое со стека словом DO.
Если пересечения не произошло, то тело цикла исполняется вновь с новым значением счетчика в качестве текущего.
Такое определение позволяет рассматривать исходные параметры цикла (начальное и конечное значения) и как числа со знаком, и как числа без знака (адреса). Например, текст 10 0 DO <тело> LOOP предписывает выполнять тело цикла 10 раз со значениями счетчика 0, 1, 2, ..., 9, а в случае 0 10 DO <тело> LOOP тело цикла будет исполнено 65 526 раз со значением счетчика 10, 11, ..., 32767, -32768, -32767, .... -1 или (что то же самое) со значениями счетчика 10, 11, ..., 65535. В то же время цикл 0 10 DO <тело> -1 +LOOP будет исполняться 11 раз (а не 10) со значениями счетчика 10, 9, ..., 0, поскольку пересечение границы между -1 и 0 произойдет при переходе от значения счетчика 0 к следующему значению — -1.
Цикл 10 0 DO <тело> -1 +LOOP будет исполняться 65 527 раз со значениями счетчика 0, -1, -2, ..., -32768, 32767, ..., 10 или (что то же самое) 0, 65535, 65534, ..., 10. Таким образом, цикл со счетчиком всегда выполняется хотя бы один раз. Некоторые реализации предусматривают слово ?DO, которое не исполняет тело цикла ни разу, если начальное и граничное значения оказались одинаковыми.
Внутри тела цикла слово I кладет на стек текущее значение счетчика. Например, следующее определение вычисляет сумму квадратов первых N натуральных чисел:
: SS2 ( N ---> S:СУММА КВАДРАТОВ ОТ 1 ДО N) 0 SWAP ( 0,N S[0]=0 ) 1+ 1 ( S[0],N+1,1 ) DO I ( S[I-1],I ) DUP ( S[I] S[I]=S[I-1]+I*I) LOOP ; ( S[N] )
Слово LEAVE (уйти), употребленное внутри цикла, вызывает прекращение исполнения его тела; управление переходит к словам следующим за словом LOOP или +LOOP.
В программировании часто применяется конструкция цикл в цикле. Чтобы во внутреннем цикле получить текущее значение счетчика объемлющего цикла, используется слово J: DO ... I ... DO ... I ... J ... LOOP ... I ... LOOP. Первое вхождение слова I дает текущее значение счетчика внешнего цикла. Следующее вхождение I дает уже значение счетчика внутреннего цикла. Чтобы получить счетчик внешнего цикла, надо использовать слово J.
По выходе из внутреннего цикла доступ к этому значению вновь дает слово I. Этим слова I и J отличаются от переменных цикла в традиционных языках программирования. Некоторые реализации предусматривают еще и слово К для доступа к счетчику третьего объемлющего цикла.
Введение новых слов
Замечательное свойство языка Форт — это возможность вводить в него новые слова, расширяя тем самым набор его команд в нужном программисту направлении. Для введения новых слов чаще всего используется определение через двоеточие — определение нового слова через уже известные. Такое определение начинается словом : (двоеточие) и заканчивается словом ; (точка с запятой). Сразу после двоеточия идет определяемое слово, а за ним — последовательность слов, через которые оно определяется. Например, текст : S2 DUP * SWAP DUP * + ; определяет слово S2, вычисляющее сумму квадратов двух чисел, снимаемых с вершины стека S2 A,B --> A**2+B**2. После ввода данного описания слово S2 можно исполнять и включать в описания других слов. При создании таких определений рекомендуется тщательно комментировать все изменения стека. Слово ( (открывающая круглая скобка) отмечает начало комментария; все следующие литеры до первой ) (закрывающей скобки) считаются комментарием и при обработке вводимого форт-текста пропускаются.
Перепишем приведенное выше определение слова S2, показывая состояние вершины стека после исполнения каждой строки:
: S2 ( A,B ---> A**2+B**2 сумма квадратов) DUP ( A,B,B) * SWAP ( B**2,A) DUP * ( B**2,A**2) + ; ( A**2+B**2)
По-видимому, минимальным требованием к документированности определения следует считать задание начального и конечного состояний вершины стека при работе слова.
Рассмотрим подробнее работу форт-системы во время определения новых слов. Мы уже знаем, что получив от программиста очередную порцию входного текста, форт-система выделяет в ней отдельные слова и ищет их в своем словаре. Эту работу выполняет текстовый интерпретатор форт-системы. Если слово в словаре не найдено, то текстовый интерпретатор пытается понять его как число, используя описанное выше правило умолчания. Если слово найдено или оказалось записью числа, то дальнейшие действия интерпретатора зависят от его текущего состояния. В каждый момент времени текстовый интерпретатор находится в одном из двух состояний: в состоянии исполнения или в состоянии компиляции.
В состоянии исполнения найденное слово исполняется (т.е. выполняется действие, составляющее его семантику), а число кладется на стек. Если же интерпретатор находится в состоянии компиляции, то найденное слово не исполняется, а компилируется, т.е. включается в создаваемую последовательность действий для определяемого в данный момент слова. Найденное и скомпилированное таким образом слово будет исполнено наряду с другими такими словами во время исполнения определенного через них слова. Если требуется скомпилировать число, то текстовый интерпретатор компилирует особый литеральный код, который во время исполнения положит значение данного числа на стек.
Проследим за работой текстового интерпретатора по обработке уже рассмотренного определения слова : S2 DUP * SWAP DUP * + ;. Предположим, что перед началом обработки введенной строки интерпретатор находится в состоянии исполнения. Первым словом является : (двоеточие), которое исполняется. Его семантика состоит в том, что из входной строки выбирается очередное слово и запоминается в качестве определяемого, а интерпретатор переключается в состояние компиляции. Следующие слова, которые интерпретатор будет извлекать из входной строки (DUP, *, SWAP и т.д.), будут компилироваться, а не исполняться, так как интерпретатор находится в состоянии компиляции. В результате с определяемым словом S2 связывается последовательность действий, отвечающая этим словам. Процесс выделения и компиляции слов будет продолжаться до тех пор, пока не встретится ; (точка с запятой). Это слово особенное, оно имеет так называемый «признак немедленного исполнения». Слова с таким признаком исполняются независимо от текущего состояния текстового интерпретатора, поэтому точка с запятой будет вторым исполненным словом после двоеточия. Семантика точки с запятой заключается в том, что построение определения, начатого двоеточием, завершается и интерпретатор вновь переключается в состояние исполнения Поэтому после ввода определения слова S2 мы тут же можем проверить, как оно работает на конкретных значениях:
> 5 4 S2 . 41 ОК
Слова с признаком немедленного исполнения ( другим примером такого слова помимо точки с запятой является открывающая круглая скобка — начало комментария) выполняются по-разному в зависимости от состояния текстового интерпретатора. Некоторые из них даже используются только в одном из этих состояний. Поэтому на диаграмме для таких слов будем отмечать эти случаи, специально указывая состояние компиляции
( ---> ---> (компиляция)
Слово ( в обоих состояниях действует одинаково: пропускает все следующие вводимые литеры до закрывающей круглой скобки включительно или до конца введенной строки, если закрывающая скобка отсутствует.
Слово ; допустимо применять только в состоянии компиляции: ; --> (компиляция). Оно завершает построение нового определения и переключает текстовый интерпретатор в состояние исполнения.
Слово IMMEDIATE (немедленный) --> устанавливает признак немедленного исполнения для последнего определенного слова. (Подробнее использование этого признака рассматривается в п.1.7.)
Введенные слова можно исключить из словаря с помощью слова FORGET (забыть) -->, которое выбирает из входной строки следующее слово и исключает его из словаря вместе со всеми словами, определенными позже.
Разберем следующий протокол диалога:
> 2 2 * . 4 ОК > : 2 3 ; ОК > 2 2 * . 9 ОК > FORGET 2 ОК > 2 2 * . 4 ОК
Сначала программист вычисляет произведение от умножения 2 на 2 и получает ответ 4. Введя затем определение слова 2 как числа 3, он в дальнейшем получает уже другой ответ. Исключив это определение слова 2 через FORGET, он возвращается к прежней семантике слова 2.
В процессе работы текстового интерпретатора программист может переключать его из состояния компиляции в состояние исполнения и обратно с помощью слов [ (открывающая квадратная скобка) --> и ] (закрывающая квадратная скобка) -->. Слово [ имеет признак немедленного исполнения и переключает интерпретатор в состояние исполнения, а слово ] переключает его в состояние компиляции.
Обычно эти слова используются внутри определения через двоеточие, чтобы вызвать исполнение слова или группы слов, не имеющих признака немедленного исполнения. Например, если в тексте определения понадобилась константа FF00 (в шестнадцатиричной системе), а текущей используемой системой является десятичная, то было бы неправильно включить в текст определения фрагмент HEX FF00 DECIMAL, поскольку слово HEX будет не выполнено, а скомпилировано и число не будет воспринято правильно. Вместо этого следует писать: [ HEX ] FF00 [ DECIMAL ]. В языке есть и другие способы, чтобы выразить это же более точно и красиво.
Еще один пример дает использование слова LITERAL (литерал), имеющего признак немедленного исполнения, внутри определения через двоеточие. Оно используется в виде: [ <значение> ] LITERAL, где <значение> — слова, вычисляющие на вершине стека значение, которое словом LITERAL будет скомпилировано в код как число. Во время исполнения определения это значение будет положено на стек. Таким образом, текст [ 2 2 * ] LITERAL внутри определения через двоеточие эквивалентен употреблению слова-числа 4. Это дает большие возможности для использования констант, «вычисляемых» во время компиляции определения. Аналогичное соответствие имеет место и вне определения через двоеточие, поскольку в состоянии исполнения слово LITERAL не выполняет никаких действий, и поэтому на стеке остается вычисленное перед этим значение.
Целевая компиляция и модель форт-системы
Решая задачу на языке Форт, программист расширяет исходный набор слов-команд форт-системы, добавляя к нему новые определения. Его конечной целью является определение некоторого «главного» слова, исполнение которого и решает поставленную задачу. Главное слово можно запустить на счет через текстовый интерпретатор форт-системы, если ввести имя слова в качестве очередной форт-команды. Во время исполнения этого слова используются ранее введенные определения вспомогательных слов и (прямо или косвенно) ряд слов исходной форт-системы.
Во многих форт-системах предусмотрена возможность сохранения текущего состояния словаря во внешней памяти в качестве двоичного форт-модуля. Это позволяет при последующих обращениях к данной задаче сразу начинать счет, запуская на исполнение ее главное слово. При таком подходе естественно возникает задача минимизации используемых средств и построения конечного программного продукта, уже не зависящего от форт-системы. Такую задачу позволяет решать пакет целевой компиляции, который является ценным инструментальным средством при создании прикладного программного обеспечения на языке Форт.
Целевая компиляция позволяет создавать единый независимый рабочий модуль исходя из комплекса взаимосвязанных определений на языке Форт. Составной частью этого комплекса является запись определений всех стандартных слов, которая образует модель форт-системы и над которой «надстраиваются» определения данной задачи. В тексте модели обычно выделяется запускающая часть, которая обеспечивает инициирование работы и переход к исполнению главного слова в данном комплексе определений. Если в реализации есть пакет целевой компиляции, его часто используют для раскрутки самой форт-системы исходя из некоторой ее начальной версии. В этом случае главным является приводившееся выше слово ФОРТ-СИСТЕМА, которое выполняет бесконечный цикл по вводу входного потока с терминала и его текстовой интерпретации.
Входной текст для целевой компиляции помимо собственно текста на языке Форт содержит еще ряд слов-директив, позволяющих выполнять компиляцию за один проход по тексту.
Эти директивы включают, в частности, средства предописания слов для того, чтобы некоторые слова можно было использовать раньше их определения (например, чтобы в запускающей части, с которой обычно начинается входной текст, указать имя главного слова, которое будет определено только в конце). Важной возможностью является управление построением целевой словарной статьи: некоторые или даже все статьи можно создать без заголовка, значительно сократив за счет этого размер рабочего модуля. Кроме того, язык директив обычно содержит средства для диагностики, распечатки карты создаваемого модуля, построения таблицы перекрестных ссылок, сбора и распечатки статистической информации об использовании тех или иных слов.
Пакет целевой компиляции представляет собой отдельно загружаемый пакет, написанный на языке Форт. В начале работы он резервирует область памяти для целевого адресного пространства, в которой строит двоичный код конечного программного продукта по мере обработки входного текста. После завершения целевой компиляции построенный модуль может быть выгружен во внешнюю память для дальнейшего использования в качестве независимого модуля в соответствии с заложенными в него соглашениями о связях.
В состав пакета целевой компиляции входят целевой ассемблер и целевой компилятор. Целевой ассемблер отличается от обычного встроенного ассемблера форт-системы только тем, что строит машинный код не в инструментальном адресном пространстве от текущей вершины словаря, которая задается словом HERE (здесь), а в целевом. Указатель в целевом адресном пространстве обычно обозначается словом THERE (там) внутри самого пакета, который пользуется обоими этими указателями. Для того чтобы получить целевой ассемблер из исходного инструментального, как правило, достаточно оттранслировать его в контексте других определений компилирующих слов (, , C, , ALLOT и т.д.), которые выполняют те же действия, но в целевом адресном пространстве, а не в инструментальном.
Задача целевого компилятора состоит в построении высокоуровневого шитого кода в целевом адресном пространстве, причем все ссылки на статьи, включая и ссылки на все стандартные форт-слова, должны также относиться к этому пространству.
Для решения этой задачи обычно поступают следующим образом. В списке слов целевой компиляции переопределяют все стандартные определяющие слова (:, CONSTANT, VARIABLE, CODE и т.д.) таким образом, чтобы они строили две статьи: одну стандартным образом, но в целевом адресном пространстве, а другую — специальным образом — в инструментальном. Исполнение инструментальной статьи компилирует ссылку, соответствующую целевой статье данного слова, как очередной элемент шитого кода на вершину целевого словаря. Обрабатывая стандартным текстовым интерпретатором высокоуровневое определение в контексте таких инструментальных определений, мы получаем в целевом пространстве соответствующий шитый код. Аналогичным образом должны быть переопределены и все слова с признаком немедленного исполнения, реализующие структуры управления и выполняющие какую-либо компиляцию во время обработки определений (IF, THEN, ; и т.д.). Эти слова в отличие от их стандартных прототипов должны компилировать статьи и переходы для целевого адресного пространства, а не инструментального. Совокупность перечисленных определений и образует целевой компилятор.
При построении конечного программного продукта путем целевой компиляции возможно существенное уменьшение его размера. Кроме уже упоминавшегося исключения из словарных статей ненужных заголовков целевая компиляция позволяет вести учет всех используемых данной задачей слов и автоматически собрать для нее специальное ядро поддержки, состоящее только из тех слов, которые в ней действительно используются. При этом возможна еще большая оптимизация за счет непосредственной подстановки определений в место их вызова для тех слов, которые оказались использованными только один раз. Некоторые пакеты целевой компиляции дают возможность довести такую подстановку до уровня машинного кода, при этом высокоуровневые определения рассматриваются как своеобразные макроопределения. После выполнения такой макрогенерации результирующий машинный код уже не требует адресного интерпретатора и представляет собой линейную последовательность непосредственно исполняемых машинных команд.
Именно этот прием был применен, например, при создании известного пакета машинной графики ГРАФОРТ для персонального компьютера фирмы ИБМ и компьютеров фирмы «Эппл» (Apple, США). Сравнительно большой объем получившегося машинного кода компенсировался чрезвычайно высоким быстродействием, недостижимым для традиционных языков программирования. В то же время совершенно очевидно, что разработать и отладить программу такого объема на языке ассемблера вручную практически невозможно.
Описанный подход к целевой компиляции применим и в том случае, когда целевая ЭВМ, для которой строится конечный программный продукт, отличается по своей архитектуре и системе команд от инструментальной. В этом случае изменения касаются только целевого ассемблера и определений в машинном коде, которые должны отвечать системе команд целевой ЭВМ. Такое использование целевой компиляции в качестве инструментального кросс-средства все чаще имеет место при создании программного обеспечения встроенных микропроцессоров и специализированных микропроцессорных устройств на их основе.
Интерпретация входного потока
Собственно работа форт-системы заключается в распознавании и исполнении слов-команд, которые программист вводит с терминала. Ввод осуществляется построчно: набрав нужный текст, программист нажимает специальную управляющую клавишу, сообщая тем самым о завершении ввода. Форт-система размещает введенный текст в специальном буфере для ввода с терминала, который располагается в адресном пространстве оперативной памяти. Адрес начала этого буфера дает стандартное слово TIB (сокращение от TEXT INPUT BUFFER — буфер для ввода текста), его длина хранится в стандартной переменной #TIB. Данный буфер представляет собой входной поток, из которого слово WORD выбирает слова. По исчерпании входного потока форт-система вводит в этот буфер новый текст, получаемый от программиста. При возникновении какой-либо ошибочной ситуации форт-система прекращает дальнейшую интерпретацию текущего содержимого этого буфера и, выдав соответствующее сообщение программисту, заполняет буфер новым текстом, который после этого вводит программист.
Альтернативой вводу текста с терминала является ввод из внешней памяти форт-системы. Переключением входного потока на внешнюю память и обратно на терминал управляет стандартная переменная BLK (сокращение от BLOCK — блок), значение которой проверяется каждый раз в слове WORD. Если это нуль, то в качестве входного потока служит буфер TIB, в противном случае это значение рассматривается как номер блока внешней памяти, который используется как входной поток (этот блок переносится в оперативную память словом BLOCK). Текущая позиция во входном потоке хранится в стандартной переменной >IN (от IN — вход) и в случае ввода с терминала изменяется в пределах от 0 до значения #TIB, а при вводе из внешней памяти — в диапазоне от 0 до 1024.
Обычно конец входного потока в оперативной памяти отмечается нулевым кодом (именно для этого в буферном пуле после памяти для данных блока резервируется еще одна ячейка). Слово WORD, «натыкаясь» на нулевой код, возвращает в качестве результата пустую строку с нулевым значением счетчика литер, при этом в список FORTH включается словарная статья для такого «пустого» слова.
Оно имеет признак немедленного исполнения и поэтому всегда исполняется назависимо от текущего состояния текстового интерпретатора. Его исполнение состоит в прекращении интерпретации данного входного потока и тем самым позволяет избежать дополнительных проверок на исчерпание. Обычно в реализациях языка Форт определяется слово INTERPRET (интерпретировать), выполняющее интерпретацию текущего входного потока. Оно представляет собой бесконечный цикл по вводу и исполнению (или компиляции) слов:
: INTERPRET ( ---> ) BEGIN BL WORD FIND ?DUP IF ( ПРОВЕРИТЬ ПРИЗНАК IMMEDIATE) 1+ IF EXECUTE ELSE STATE @ IF , ELSE EXECUTE THEN THEN ELSE ( МОЖЕТ БЫТЬ ЭТО ЧИСЛО?) NUMBER DPL @ 1+ IF [COMPILE] 2LITERAL ELSE DROP [COMPILE] LITERAL THEN THEN AGAIN ;
В приведенном примере конструкция BEGIN-AGAIN определяет бесконечный цикл.
Слово AGAIN выполняет безусловный переход на начало цикла.
В случае если очередное введенное слово не найдено в словаре, исполняется слово NUMBER, которое пытается воспринять его как запись числа в соответствии с текущим основанием системы счисления — значением переменной BASE. Если это удалось, то слово NUMBER возвращает значение числа как значение двойной длины и дополнительно в переменной DPL сообщает позицию десятичной точки в нем (-1, если точки в записи числа не было). В противном случае возникает ошибочная ситуация «Слово не найдено», и интерпретация прекращается. Если же введенное слово оказалось числом, то в зависимости от наличия в нем точки оно рассматривается как число двойной или одинарной точности. Таким образом, пустое слово-ограничитель входного потока-прекращает исполнение слова INTERPRET и возобновляет исполнение слова, его вызвавшего:
: X ( ---> ) R> DROP ; IMMEDIATE
Здесь X обозначает пустое слово.
Таким образом, работу форт-системы можно задать таким бесконечным циклом:
: ФОРТ-СИСТЕМА ( ---> ) BEGIN CR ." >" ( ПРИГЛАШЕНИЕ К ВВОДУ) TIB 80 EXPECT ( ВВЕСТИ ТЕКСТ С ТЕРМИНАЛА) SPAN @ #TIB ! ( УСТАНОВИТЬ ЕГО ДЛИНУ) 0 TIB #TIB @ + C! ( УСТАНОВИТЬ ОГРАНИЧИТЕЛЬ) 0 >IN ! 0 BLK ! ( УСТАНОВИТЬ ВХОДНОЙ ПОТОК) INTERPRET ( ИНТЕРПРЕТИРОВАТЬ ВВЕДЕННЫЙ ТЕКСТ) STATE @ 0= IF ." OK" THEN ( ПОДТВЕРЖДЕНИЕ) AGAIN ;
Для переключения входного потока на внешнюю память стандарт предусматривает слово LOAD (загрузить) :
: LOAD ( N:НОМЕР ---> ИНТЕРПРЕТИРОВАТЬ ЭКРАН) >IN @ >R BLK @ >R ( СОХРАНИТЬ ТЕКУЩИЙ) BLK ! 0 >IN ! ( УСТАНОВИТЬ НОВЫЙ) INTERPRET ( ПРОИНТЕРПРЕТИРОВАТЬ ЕГО) R> BLK ! R> >IN ! ; ( ВЕРНУТЬСЯ К ПРЕЖНЕМУ)
Параметром слова LOAD является номер экрана (блока) для интерпретации. Очевидно, что приведенное нами выше определение допускает рекурсивное использование слова LOAD внутри экранов во внешней памяти.
Некоторые реализации предусматривают слово THRU (сквозь) для последовательной интерпретации диапазона экранов:
: THRU ( N1,N2 ---> ИНТЕРПРЕТИРОВАТЬ ЭКРАНЫ) ( ОТ N1 ДО N2 ВКЛЮЧИТЕЛЬНО) 1+ SWAP DO I LOAD LOOP ;
Для продолжения интерпретации следующего экрана часто используется слово -->, логически сцепляющее следующей экран с данным:
: --> ( ---> ) BLK @ 0= ABORT" НЕДОПУСТИМОЕ ИСПОЛЬЗОВАНИЕ -->" 0 >IN ! BLK @ 1+ BLK ! ; IMMEDIATE
В этом случае интерпретации сцепленных экранов нужно «загрузить» словом LOAD только первый из этих экранов.
Работа с внешней памятью
В настоящее время в каждом языке программирования тем или иным способом решаются вопросы обмена с внешней памятью. Из-за огромного разнообразия внешних устройств и способов хранения информации на внешних носителях единый универсальный механизм обмена отсутствует. В каждом языке определяется своя, в известной мере универсальная файловая система, которая при реализации моделируется на реальной файловой системе конкретной операционной системы.
Поскольку в язык Форт легко включать новые слова-команды, то надобность в стандартных универсальных развитых средствах обмена отпадает. В каждой реализации можно ввести такие средства исходя из особенностей и возможностей применяемых для данной ЭВМ файловой системы и конкретных внешних устройств. Вместе с тем желательно иметь механизм, обеспечивающий по крайней мере перенос и хранение на машинном носителе программных текстов на языке Форт. Исходя из этого стандарт предусматривает элементарнейшую файловую систему, которая легко реализуется в любой конкретной файловой системе или непосредственно через драйверы внешних устройств (магнитных дисков).
В языке Форт применяется механизм виртуальной внешней памяти, состоящей из блоков по 1 Кбайт каждый. Блок идентифицируется номером — числом в диапазоне от 1 до 32767. В адресном пространстве форт-системы выделяется память под буферный пул, рассчитанный на одновременное хранение одного или более блоков. Каждый буфер помимо памяти для хранения собственно блока данных содержит номер блока и признак его измененности.
Слово BUFFER (буфер), получив номер блока, ищет свободный буфер в пуле и возвращает его адрес, записывая в служебную ячейку буфера переданный номер блока. Тем самым найденный буфер приписывается данному блоку, однако содержимое буферной памяти пока остается прежним. Если свободного буфера не оказалось, то аналогичным образом используется один из занятых. Если при этом в служебной ячейке буфера был установлен признак измененности, то данные из буферной памяти переписываются во внешнюю, они заменяют там прежнее содержимое соответствующего блока.
Слово BLOCK (блок) аналогично по использованию слову BUFFER за исключением того, что перепись данных из внешней памяти производится в приписанный данному блоку буфер. Разумеется, если данный блок уже находится в буферном пуле, то переписи данных не происходит, и слово BLOCK возвращает адрес этого буфера.
Наконец, слово UPDATE (изменить) устанавливает признак измененности последнего блока, к которому было адресовано обращение через слово BLOCK или BUFFER. Таким образом, впоследствии этот блок будет автоматически переписан во внешнюю память.
При реализации обмена с внешней памятью в качестве буферного пула обычно используется связный участок оперативный памяти. Пусть его начало задается константой FIRST, а конец — адрес байта, следующего за последним, — константой LIMIT. (Если пул располагается вплотную к концу адресного пространства, то этот следующий адрес равен нулю!) Буфера в пуле располагаются подряд, каждый начинается двухбайтной ячейкой, в которой записывается номер приписанного блока, причем старший разряд используется под признак измененности. Далее идет буферная память для блока размером 1024 байта, завершается буфер еще одной служебной ячейкой, в которой записан ноль (ее назначение указано в ). Пусть переменные PREV и USE указывают на текущий используемый буфер и следующий, который будет выдан при запросе на свободный буфер. Определим слово +BUF, которое вычисляет адрес буфера, следующего в пуле за переданным, и возвращает признак несовпадения его с текущим:
: +BUF ( A1 ---> A2,F ) 1024 + 4 + DUP LIMIT - IF DROP FIRST THEN DUP PREV @ - ;
Пусть служебные слова RBLK A,N --> и WBLK A,N --> выполняют чтение блока с указанным номером в заданную область оперативной памяти и запись из нее. Тогда с учетом принятых условий слова, выполняющие работу с внешней памятью, можно задать так:
: BUFFER ( N ---> A ПРИПИСАТЬ БЛОКУ N БУФЕР) USE @ DUP >R ( ВЕРНЕМ ЭТОТ БУФЕР) BEGIN +BUF UNTIL USE ! ( УСТАНАВЛ.СЛЕДУЮЩИЙ) R@ @ 0< ( ПРИЗНАК ИЗМЕНЕННОСТИ?) IF R@ 2+ R@ @ 32767 AND WBLK THEN R@ ! ( ПРИПИСАЛИ НОВОМУ БЛОКУ) R@ PREV ! R> 2+ ; : BLOCK ( N ---> A:АДРЕС БУФЕРА С ДАННЫМИ БЛОКА) >R PREV @ DUP R@ - DUP + ( ТЕКУЩИЙ - ТОТ ЖЕ?) IF ( НЕТ) BEGIN +BUF 0= IF DROP R@ BUFFER DUP R@ RBLK 2- THEN DUP @ R@ - DUP + 0= UNTIL DUP PREV ! THEN R> DROP 2+ ; : UPDATE ( ---> ) PREV @ @ 32768 OR PREV @ ! ;
Для записи всех измененных буферов во внешнюю память служит слово SAVE-BUFFERS (сохранить буфера):
: SAVE-BUFFERS ( ---> ) LIMIT FIRST DO I @ 32768 AND IF I @ 32767 AND DUP I ! I 2+ SWAP WBLK THEN 1028 +LOOP ;
При исполнении слова SAVE-BUFFERS все буфера остаются приписанными прежним блокам. Слово FLUSH (очистить) переписывает все исправленные блоки во внешнюю память и освобождает буфера. Многие реализации имеют слово EMPTY-BUFFERS (опустошить буфера), которое освобождает буферный пул, не переписывая исправленные блоки:
: EMPTY-BUFFERS ( ---> ) LIMIT FIRST DO 0 I @ ! 1028 +LOOP ; : FLUSH ( ---> ) SAVE-BUFFERS EMPTY-BUFFERS ;
Внешняя память форт-системы в основном используется для хранения форт-текстов. Блок внешней памяти с форт-текстом называется экраном и условно разбивается на 16 строк по 64 литеры в каждой. Такой формат экрана сложился традиционно и закреплен в стандарте.
Программист создает и исправляет экраны во внешней памяти, используя встроенный редактор форт-системы. Как и в случае встроенного ассемблера, стандарт не определяет конкретный вид и состав его команд, поскольку это в значительной степени определяется функциональными возможностями и характеристиками конкретных терминалов и средствами работы с ними. Обычно слова-команды текстового редактора составляют отдельный список слов с именем EDITOR (редактор), базирующийся на списке FORTH. Для распечатки редактируемого экрана на терминале чаще всего используют слово LIST (распечатать), которое, кроме того, сохраняет номер экрана в служебной переменной SCR:
: LIST ( N ---> ) DUP SCR ! CR ." ЭКРАН " DUP . BLOCK 16 0 DO DUP I 64 * + CR I 3 .R SPACE 64 TYPE LOOP DROP ;
Вначале печатается номер данного экрана, затем его строки. Перед каждой строкой печатается ее номер — число в диапазоне от 0 до 15. По завершении редактирования исправленные экраны можно записать во внешнюю память словом FLUSH.
Реализация определяющих слов
Механизм определяющих слов составляет одно из основных достоинств языка Форт, главную «находку» его создателей. С его помощью программист может вводить свои типы данных и структуры управления, задавая их внешнее синтаксическое оформление и внутреннюю семантическую реализацию. Исходный строительный материал программист может брать из сравнительно небольшого исходного запаса слов-команд языка или создавать сам.
Широкие выразительные возможности и вместе с тем компактность реализации этого механизма вытекают из того, что в его основе лежит фундаментальный принцип частичной параметризации. Его применению в традиционных языках программирования мешал громоздкий аппарат процедурного вызова, который считался в этих языках элементарным и неделимым действием. В языке Форт конструкция вызова разложена на отдельные составляющие и доступна «по частям», в частности имеется доступ к адресу возврата и всему динамическому контексту вызова.
В сочетании с единым механизмом передачи параметров через стек и компактной реализацией через шитый код это дает недостижимый для других языков уровень свертки понятий.
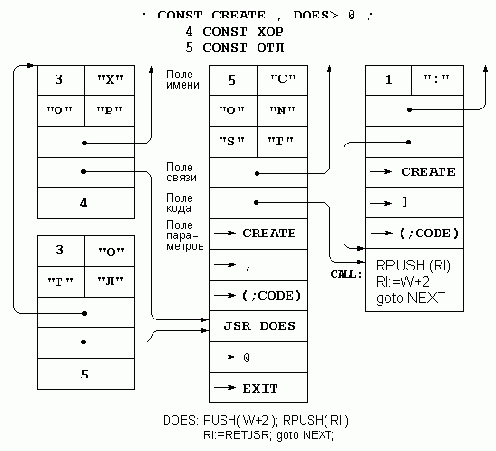
Рис. 2.8. Структура статьи определяющих и определяемых слов
На рис. 2.8 приведена структура словарных статей, возникающая после обработки определений
: CONST CREATE , DOES> @ ; 4 CONST ХОР 5 CONST ОТЛ
Там же показана словарная статья для слова :, в теле которой находится точка CALL адресного интерпретатора.
Поле кода статьи CONST содержит адрес точки CALL, а поле параметров содержит последовательность ссылок на словарные статьи, скомпилированную адресным интерпретатором в соответствии с техникой шитого кода. Слово DOES>, входящее в это определение, имеет признак немедленного исполнения, поэтому оно не компилируется вслед за ссылкой на статью для запятой, а исполняется. Его исполнение состоит в компиляции ссылки на статью вспомогательного слова (;CODE) и компиляции машинной команды JSR перехода с возвратом на специальную точку DOES в ядре форт-системы.
Далее текстовый интерпретатор компилирует ссылку на статью для @ и исполняет (в силу признака немедленного исполнения) слово ;, которое завершает построение словарной статьи. Оно компилирует ссылку на статью EXIT и переключает текстовый интерпретатор в состояние исполнения.
Во время исполнения слова CONST во фрагменте 4 CONST ХОР входящее в него слово CREATE создаст для слова ХОР заголовок словарной статьи и поле кода, заслав туда стандартный адрес. Следующее слово, скомпилирует число 4 в поле параметров, а слово (;CODE) занесет в поле кода адрес следующей за ним машинной программы и закончит исполнение слова CONST:
: (;CODE) ( ---> ) R> LATEST NAME> ! ;
Значение, снимаемое с вершины стека возвратов словом R>, — это как раз адрес команды JSR в определении слова CONST. Слово LATEST кладет на стек адрес заголовка последней созданной статьи, т.е. статьи ХОР, а слово NAME> преобразует этот адрес в адрес поля кода. Поскольку со стека возвратов было снято одно значение, то по завершении данного определения управление вернется в точку после вызова определения, вызвавшего данное, т.е. на продолжение работы после вызова слова CONST. Аналогичные действия будут исполнены при обработке текста 5 CONST ОТЛ. Если теперь слово ХОР будет исполняться, то из точки NEXT адресного интерпретатора управление будет передано на машинную программу по адресу из поля кода, т.е. на команду JSR в теле определения CONST. Эта команда перехода с возвратом передает управление на точку DOES, сообщив ей в качестве своего адреса возврата адрес следующей последовательности ссылок — исполняющей части определения CONST. Точка DOES кладет на стек адрес поля параметров статьи ХОР (в этот момент в рабочей ячейке W еще находится адрес поля кода статьи ХОР, загруженный туда действием NEXT) и исполняет действие CALL для исполняющей части определения CONST. Следующее исполняемое слово @ заменит на стеке адрес поля параметров статьи ХОР числом 4, скомпилированным по этому адресу, и затем слово EXIT завершит исполнение данного вызова слова ХОР.
Слово : тоже является определяющим, и его словарная статья имеет такую же структуру. Рассмотрим его работу на примере трансляции определения CONST.
Создающая часть слова : состоит из слов CREATE и ]. Первое выбирает из входной строки следующее за двоеточием слово (в данном случае CONST) и создает для него начало словарной статьи (заголовок и поле кода), а второе переключает текстовый интерпретатор в состояние компиляции. Последнее в создающей части слово (;CODE) вписывает в поле кода создаваемой новой статьи текущее значение указателя интерпретации, т.е. адрес точки CALL, которая располагается в теле данного определения, после чего исполнение двоеточия заканчивается. Поскольку теперь интерпретатор находится в состоянии компиляции, то следующие вводимые слова будут компилироваться, заполняя поле параметров статьи CONST последовательностью ссылок. Так будет продолжаться до тех пор, пока слово — точка с запятой, отмечающее конец определения и имеющее признак немедленного исполнения, не переключит интерпретатор обратно в состояние исполнения:
: ; ( ---> ) COMPILE EXIT [COMPILE] [ ; IMMEDIATE
Определяющие слова являются механизмом для создания классов слов со сходным «поведением», которое определяется исполняющей частью и включается в словарную статью слова через поле кода. Разница между словами внутри одного класса состоит в значении поля параметров, которое строится при определении слова. Слова, определенные через двоеточие, составляют один из классов наряду с константами, переменными, списками слов и другими, которые программист может вводить по своему усмотрению. При этом достигается существенная экономия памяти за счет того, что общая часть всех слов одного класса присутствует в памяти в единственном экземпляре в статье определяющего слова.
Таким образом, в основе языка Форт лежат две структуры: внешняя — простейшая синтаксическая структура слова, представленного как последовательность литер, ограниченная пробелом, и внутренняя — структура словарной статьи, в которой поле кода задает интерпретатор поля параметров.Одним из частных случаев такого интерпретатора является адресный интерпретатор, и тогда поле параметров содержит последовательность интерпретируемых адресов в шитом коде. Этому случаю отвечает определение через двоеточие. Другие определяющие слова задают другие интерпретаторы и соответственно другие структуры поля параметров.
Шитый код и его разновидности
Логически можно выделить два подхода к реализации языков программирования — трансляцию и интерпретацию []. Транслятор преобразует входной текст программы в машинный код данной ЭВМ; впоследствии этот код, объединяясь с другими машиниыми модулями, образует рабочую программу, которую можно загрузить в оперативную память и исполнить. Интерпретатор непосредственно исполняет программу на языке высокого уровня, рассматривая входной текст как последовательность кодов операций, управляющих его работой. Между этими полюсами располагается целый спектр промежуточных подходов, состоящих в предварительном преобразовании входного текста программы в некоторый промежуточный язык с последующей интерпретацией получившегося кода. Чем ближе промежуточный язык к машинному языку, тем ближе данный подход к классической трансляции, а чем ближе он к исходному языку программирования, тем ближе этот подход к интерпретации.
Оптимальный вариант промежуточного языка должен существенно отличаться от исходного языка программирования и быть удобным для создания простых и надежных интерпретаторов. Примером одного из таких промежуточных языков является известный П-код, используемый во многих реализациях языка Паскаль. Рассматриваемые нами варианты шитого кода образуют специальный класс представлений промежуточных языков, особенно удобных для интерпретации [, , ].
В общем случае промежуточный язык состоит из набора элементарных операций, средств управления локальной памятью для хранения и передачи данных и средств управления процессом вычисления. Однако если по своей сложности промежуточный язык приближается к исходному машиннонезависимому языку программирования, то целесообразность его использования снижается. Одним из приемов, направленных на упрощение набора команд промежуточного языка, является применение стековой архитектуры (или нуль-адресных команд). В этом случае для работы с памятью требуется всего две операции: перенести значение со стека в память и наоборот из памяти в стек.
Кроме того, стековая архитектура естественным образом приводит к стековому механизму передачи параметров, который таким образом становится общей частью всех реализации данного промежуточного языка.
Шитый код особенно удобен для реализации виртуальных машин со стековой архитектурой: П-кода, Лиспа и, конечно, Форта. Вместе с тем в каждом случае следует различать качества реализации, которые обеспечиваются применением шитого кода, и качества, которые присущи самому языку.
Известны четыре разновидности шитого кода: подпрограммная, прямая, косвенная и свернутая. Во всех четырех случаях операции промежуточного языка представляются ссылками на подпрограммы, соответствующие этим операциям. Перечисленные разновидности различаются способом представления этих ссылок и соответственно интерпретатором такой последовательности. Подпрограммы, реализующие операции языка, разделяются на два класса: верхнего уровня, представленные в том же шитом коде, и нижнего уровня, реализованные непосредственно в машинном коде данной ЭВМ. Подпрограммы нижнего уровня взаимодействуют с интерпретатором шитого кода, используя выделенные ему машинные ресурсы. Вместе с тем конкретный вид этих ресурсов может быть самым разным для разных архитектур ЭВМ.
Во всех разновидностях шитого кода его интерпретатор должен обеспечивать выполнение трех действий, которые традиционно обозначаются так:
NEXT (следующий) — переход к интерпретации следующей ссылки в данной последовательности ссылок;
CALL (вызов) — переход в подпрограмму верхнего уровня, представленную в шитом коде;
RETURN (возврат) — возврат из подпрограммы верхнего уровня на продолжение интерпретации.
В силу его очевидной рекурсивности интерпретатор использует специальный стек в качестве собственной структуры данных. Этот стек называется стеком возвратов, чтобы отличать его от стека данных, обычно используемого операциями промежуточного языка. В качестве еще одной собственной структуры данных интерпретатора выступает указатель на текущее место в интерпретируемой последовательности ссылок, представляющих операции промежуточного языка.
Из всех разновидностей шитого кода подпрограммный максимально эффективен по времени исполнения. Он удобен в том случае, когда архитектура данной ЭВМ включает аппаратные стеки, команду перехода на подпрограмму (перехода с возвратом), в которой адрес возврата запоминается на вершине стека, и команду возврата по адресу, находящемуся на вершине стека. Для ЭВМ СМ-4 и «Электроника-60» это команды JSR и RST, для микропроцессора К580 — команды CALL и RET.
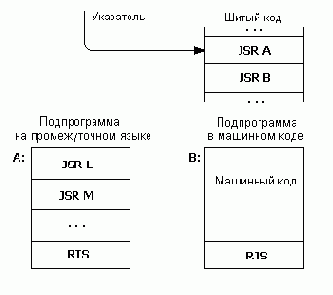
Рис. 2.1. Подпрограммный шитый код
Структура подпрограммного шитого кода приведена на рис. 2.1. Каждая ссылка на операцию промежуточного языка представляется в виде машинной команды перехода на соответствующую подпрограмму. Стек возвратов используется для сохранения адреса возврата этими командами, а в качестве указателя текущего места в интерпретируемой последовательности ссылок выступает внутренний регистр счетчика адреса. Высокоуровневая подпрограмма на промежуточном языке представляет собой последовательность таких же команд перехода с возвратом, которая заканчивается командой возврата по адресу, снимаемому с вершины стека возвратов. Подпрограмма нижнего уровня должна заканчиваться такой же командой возврата для продолжения обработки. Таким образом, в подпрограммном шитом коде интерпретатор реализуется непосредственным образом в структуре самого кода. Действие NEXT состоит в исполнении пары команд JSR/RST, действие CALL как таковое отсутствует, действие RETURN состоит в команде RST. Подпрограммный шитый код в отличие от всех остальных разновидностей допускает большую оптимизацию по времени счета за счет непосредственной вставки подпрограмм нижнего уровня в место их вызова.
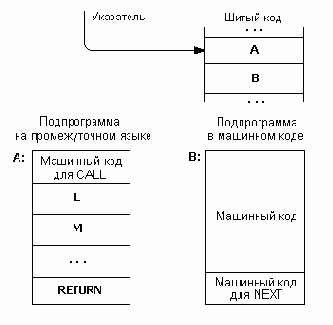
Рис. 2.2. Прямой шитый код
Прямой шитый код (рис. 2.2.) уступает подпрограммному по скорости исполнения, но дает выигрыш по объему памяти, необходимой для его размещения. В качестве последовательности операций промежуточного языка выступает последовательность адресов соответствующих подпрограмм. Ее можно рассматривать как последовательность вызовов подпрограммного шитого кода с удаленным кодом команды JSR (именно это и дает экономию объема памяти примерно на 1/3 по сравнению с подпрограммным кодом).
Поскольку код команды отсутствует, требуется специальный интерпретатор последовательности ссылок. Подпрограммы верхнего уровня должны начинаться машинными командами, выполняющими действие CALL (положить текущее значение указателя на стек возвратов, перевести указатель на начало последовательности адресов данной подпрограммы, исполнить NEXT) и заканчиваться адресом подпрограммы RETURN (снять значение со стека возвратов и заслать его в указатель, исполнить NEXT). Подпрограммы в машинном коде должны заканчиваться исполнением действия NEXT (скопировать адрес подпрограммы по текущему значению указателя в рабочую ячейку, перевести указатель на следующий элемент кода, передать управление по адресу в рабочей ячейке). В тех случаях, когда архитектура ЭВМ позволяет выразить действия CALL и NEXT одной-двумя машинными командами (например, для ЭВМ СМ-4), эти команды вставляются непосредственно в подпрограммы; если же требуется более длинная последовательность команд, то в подпрограммы вставляются команды перехода на соответствующие точки, которые выносятся в отдельное подпрограммное ядро.
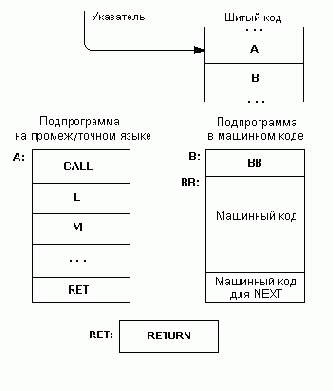
Рис. 2.3. Косвенный шитый код
Косвенный шитый код уступает прямому по скорости исполнения, но имеет то преимущество, что его высокоуровневые подпрограммы не зависят от машины, поскольку не содержат машинных кодов. Как и в случае прямого кода, последовательность операций промежуточного языка состоит из последовательности адресов подпрограмм, разница заключается в организации этих подпрограмм и действиях интерпретатора (рис. 2.3.). Теперь чтобы передать управление на машинный код, в действии NEXT требуется выполнить еще одно разыменование. Подпрограмма верхнего уровня начинается не машинными командами для действия CALL, а ячейкой, где записан адрес этой точки, и заканчивается ячейкой, где записан адрес ячейки с адресом точки RETURN. Подпрограмму на машинном языке представляет ячейка, где записан адрес начала соответствующего кода. Завершающим действием такой подпрограммы, как и раньше, является исполнение действия NEXT.
Для этого обычно используется безусловный переход на соответствующую точку интерпретатора.
Наконец, свернутый шитый код, который может быть как прямым, так и косвенным, отличается тем, что вместо прямых адресов подпрограмм и кодов в нем используются их свертки, которые, вообще говоря, короче этих адресов. Таким путем за счет усложнения доступа к подпрограммам в действии NEXT (через использование таблицы сверток или специальной функции, преобразующей свертку в соответствующий адрес) можно добиться экономии памяти или возможности использовать больший диапазон адресов для размещения кода. Пусть, например, архитектура ЭВМ требует, чтобы адреса подпрограмм и команд были четными. Тогда, используя в качестве свертки, представляющей такой адрес, его значение, деленное на 2, мы получаем возможность использовать вдвое большее адресное пространство.
Таким образом, разновидности шитого кода предлагают широкий диапазон характеристик по скорости исполнения и требованиям к памяти. Поскольку все они логически эквивалентны, то выбор конкретного варианта определяется конкретными требованиями. В реализациях языка Форт встречаются все эти варианты.
Стек возвратови реализация структур управления
Один из важных принципов языка Форт состоит в том, чтобы предоставить программисту максимальный доступ ко всем средствам его реализации. В соответствии с этим принципом собственные данные адресного интерпретатора — стек возвратов — были сделаны доступными, для чего введены специальные слова: >R A -->, R> --> А и R@ --> A. Буква R (от RETURN — возврат) в имени этих слов напоминает о том, что они работают со стеком возвратов. Все эти слова можно использовать только внутри компилируемых определений. Во время исполнения любого такого определения, представленного в шитом коде как подпрограмма верхнего уровня, на вершине стека возвратов находится адрес того места, откуда данное определение было вызвано (адрес возврата). Это значение было помещено туда действием CALL при входе в данное определение. Адрес возврата будет снят со стека возвратов и использован для продолжения интерпретации действием RETURN, составляющим семантику слова EXIT.
Перечисленные слова позволяют программисту вмешиваться в описанный механизм вызова, реализуя свои собственные схемы передач управления, и, кроме того, использовать стек возвратов для хранения временных данных в пределах одного определения (все положенные на стек возвратов значения должны быть сняты с него перед выходом из определения). Однако неосторожное манипулирование стеком возврата может вызвать непредсказуемые последствия, вплоть до разрушения форт-системы. Слово >R (читается «на эр») переносит значения с вершины стека данных на стек возвратов. Обратное действие выполняет слово R> (читается «с эр»). Слово R@ (читается «эр разыменовать») копирует вершину стека возвратов на стек данных, сохраняя это значение на стеке возвратов.
С помощью описанных слов легко определить, например, приведенное выше слово LIT, компилируемое в шитый код вместе со следующим за ним значением, чтобы во время счета положить это значение на стек данных:
: LIT ( --> A ) R@ @ R> 2+ >R ;
Во время работы данного определений слово R@ кладет на стек адрес возврата, указывающий в этот момент на следующий после адреса статьи LIT элемент в интерпретируемой последовательности адресов (см. рис. 2.4). Слово @ разыменовывает этот адрес, таким образом на стеке оказывается скомпилированное в шитый код число. Слова R> 2+ >R увеличивают адрес возврата на 2, чтобы обойти значение числа, т.е. чтобы оно не было воспринято как адрес некоторой статьи. Таким образом, в приведенном определении слова LIT реализован интересный способ передачи параметра через адрес возврата, невозможный в традиционных языках программирования.
Рассмотренные ранне структуры управления — условный оператор и циклы — также легко выражаются через эти понятия. По их образцу программист может создавать собственные структуры управления, совершенствуя свой инструментарий. Реализация условного оператора и циклов с проверкой опирается на следующие слова, аналогичные рассмотренному выше слову LIT:
: COMPILE ( ---> ) R@ @ , R> 2+ >R ; : BRANCH ( ---> ) R> @ >R ; : ?BRANCH ( A ---> ) R> SWAP IF 2+ ELSE @ THEN >R ;
Слово COMPILE (компилировать) комлилирует (т.е. добавляет) на вершину словаря значение, находящееся в шитом коде непосредственно за данной ссылкой на статью COMPILE. Слово BRANCH (переход) переустанавливает указатель интерпретации по адресу, скомпилированному вслед за данной ссылкой на статью BRANCH. Наконец, слово ?BRANCH снимает значение со стека и анализирует его: если это ЛОЖЬ (нуль), то оно работает, как BRANCH, — указатель интерпретации устанавливается по адресу, скомпилированному вслед за данной ссылкой на статью ?ВRANCH, а если это ИСТИНА (не нуль), то при интерпретации данной последовательности скомпилированный адрес перехода будет обойден. То обстоятельство, что в определении слова ?BRANCH используется условный оператор, для реализации условного оператора несущественно, потому что на практике слова BRANCH и ?BRANCH реализуются в форт-системах как подпрограммы нижнего уровня.
Приведенные определения лишь иллюстрируют выразительные возможности языка, показывая, что даже такие, самые элементарные действия можно задать машиннонезависимым способом в виде высокоуровневых определений.
Вот еще пример определения важного стандартного слова:
: LITERAL ( A ---> A/ ) STATE @ IF COMPILE LIT , THEN ; IMMEDIATE
Слово LITERAL анализирует текущее состояние текстового интерпретатора: если это компиляция, то компилирует значение, находящееся на вершине стека, как литерал в шитый код; в противном случае это значение остается на стеке.
Теперь у нас достаточно средств, чтобы выразить стандартные структуры управления, как обычные определения, через двоеточие. Например, слова для условного оператора можно определить так:
: IF ( ---> A ) COMPILE ?BRANCH HERE 2 ALLOT ; IMMEDIATE : THEN ( A ---> ) HERE SWAP ! ; IMMEDIATE : ELSE ( A1 ---> A2 ) COMPILE BRANCH HERE 2 ALLOT HERE ROT ! ; IMMEDIATE
Все эти слова имеют признак немедленного исполнения, который придается им словом IMMEDIATE, исполненным сразу после завершения каждого определения. Это означает, что данные слова будут исполняться, а не компилироваться, как остальные, во время обработки тела определений текстовым интерпретатором форт-системы.
На рис. 2.5 показана последовательность состояний словаря и стека в разные моменты обработки фрагмента A B IF C D THEN E F в теле определения через двоеточие. Эту обработку выполняет текстовый интерпретатор, находящийся в состоянии компиляции. В результате строится последовательность адресов словарных статей в соответствии с принятой техникой шитого кода.
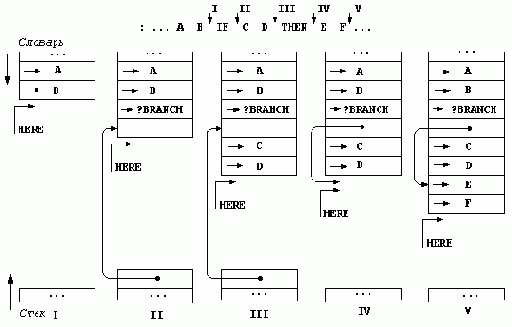
Рис. 2.5. Компиляция условного оператора
Пусть слова A, B, ..., F являются обычными форт-словами, не имеющими признака немедленного исполнения. Тогда соответствующие им адреса будут компилироваться на вершину словаря.
Состояние I на рис. 2.5. соответствует моменту обработки непосредственно перед вводом слова IF. На вершине словаря скомпилированы адреса статей A и B и указатель вершины HERE указывает на следующий адрес.
Слово IF имеет признак немедленного исполнения, поэтому будет не скомпилировано, а исполнено.
Состояние II показывает результат исполнения слова IF. На вершину словаря скомпилирована ссылка на статью ?BRANCH, вслед за которой отведено еще 2 байта под адрес перехода, и адрес зарезервированного места сохранен на стеке данных.
Дальнейшие слова C и D будут опять компилироваться. Состояние III соответствует моменту перед вводом слова THEN.
Слово THEN, как и IF, имеет признак немедленного исполнения, поэтому будет исполняться; в результате возникнет состояние IV. В этот момент определяется адрес перехода для скомпилированной словом IF ссылки на статью ?BRANCH; это текущее значение указателя вершины словаря HERE, которое и вписывается в зарезервированные ранее 2 байта. Результат дальнейшей компиляции приводит к состоянию V.
Аналогичным образом исполняется и определение слова ELSE, которое компилирует обход части «иначе» и вписывает адрес ее начала в качестве адреса перехода для ссылки ?BRANCH. В свою очередь, адрес перехода для скомпилированного обхода будет вписан завершающим условный оператор словом THEN.
Можно повысить надежность программирования условного оператора введением контроля за соответствием слов IF, THEN и ELSE с помощью вспомогательного слова ?PAIRS:
: ?PAIRS ( A1,A2 ---> ) - ABORT" НЕПАРНЫЕ СКОБКИ" ;
которое снимает два значения со стека и, если они не равны между собой (их разность не нуль), выдает сообщение об ошибке с пояснительным текстом «Непарные скобки». Стандартное слово ABORT" (выброс и кавычка) А --> (исполнение) по своему употреблению аналогично слову ." (точка и кавычка): оно снимает значение со стека и, рассматривая его как логическое, сигнализирует об ошибке, печатая следующий за ним текст до кавычки, если это значение ИСТИНА (не нуль). Усиленные таким контролем определения слов условного оператора выглядят следующим образом:
: IF ( ---> A,1 ) COMPILE ?BRANCH HERE 2 ALLOT ; IMMEDIATE : THEN ( A,1 ---> ) 1 ?PAIRS HERE SWAP ! ; IMMEDIATE : ELSE ( A1,1 ---> A2,1 ) 1 ?PAIRS COMPILE BRANCH HERE 2 ALLOT HERE ROT ! ; IMMEDIATE
В этих определениях для контроля вместе с адресом зарезервированного места передается число 1, которое проверяется с помощью слова ?PAIRS в словах, использующих переданный адрес. Такой простой способ контроля на практике оказывается вполне достаточным. При этом программист может встроить любой другой контроль по своему желанию.
Приведенное определение условного оператора связано с реализацией стандартных слов BRANCH и ?BRANCH, выполняющих переходы в шитом коде. Из соображений эффективности эти слова обычно задают как подпрограммы нижнего уровня в машинном языке. Тогда в зависимости от архитектуры ЭВМ может оказаться предпочтительней не абсолютный, как в приведенной реализации, а относительный адрес перехода, компилируемый в шитый код сразу после ссылки на статью BRANCH или ?BRANCH. Чтобы сделать определения, использующие эти слова, машиннонезависимыми, стандарт предусматривает следующие слова для организации таких ссылок:
>MARK ---> A >RESOLVE A ---> <MARK ---> A <RESOLVE A --->
Слово >MARK (от MARK — отметить) резервирует место для ссылки вперед и оставляет адрес зарезервированного места на стеке. Слово >RESOLVE (от RESOLVE — разрешить) снимает этот адрес со стека и вписывает в него ссылку на текущую вершину словаря в соответствии с принятой реализацией переходов в шитом коде, согласованной с реализацией слов BRANCH и ?BRANCH. Аналогично слова <MARK и <RESOLVE предназначены для организации ссылок назад. Слово <MARK кладет на стек текущий адрес вершины словаря, а слово <RESOLVE компилирует ссылку на переданную точку. Окончательно определения слов условного оператора можно задать следующим образом (как они и выглядят в большинстве практических реализаций):
: IF ( ---> A,1 ) COMPILE ? BRANCH >MARK 1 ; IMMEDIATE : THEN ( A,1 ---> ) 1 ?PAIRS >RESOLVE ; IMMEDIATE : ELSE ( A1,1 ---> A2,1 ) 1 ?PAIRS COMPILE BRANCH >MARK SWAP >RESOLVE 1 ; IMMEDIATE
Аналогичным образом реализуются слова для циклов с проверкой (рис. 2.6):
: BEGIN ( ---> A,2 ) <MARK 2 ; IMMEDIATE : UNTIL ( A1,2 ---> ) 2 ?PAIRS COMPILE ?BRANCH <RESOLVE ; IMMEDIATE : WHILE ( A1,2 ---> A1,A2,3 ) 2 ?PAIRS COMPILE ?BRANCH >MARK 3 ; IMMEDIATE : REPEAT ( A1,A2,3 ---> ) 3 ?PAIRS COMPILE BRANCH SWAP <RESOLVE >RESOLVE ; IMMEDIATE
Очевидно, что реализованные таким образом стандартные структуры управления могут произвольно глубоко вкладываться друг в друга; несоответствие скобочных структур будет немедленно замечено, и программист получит сообщение об ошибке.
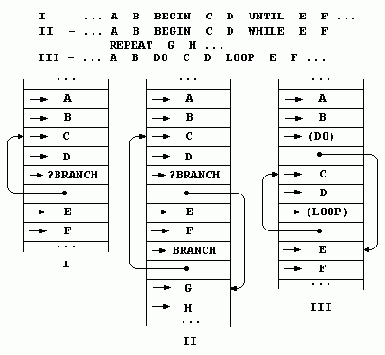
Рис. 2.6. Компиляция циклов
Циклы со счетчиком (рис. 2.6) реализуются аналогичным образом через вспомогательные слова (DO), (LOOP) и (+LOOP), компилируемые в шитый код вместе с адресом перехода:
: DO ( ---> A1,A2,4 ) COMPILE (DO) >MARK <MARK 4 ; IMMEDIATE : LOOP ( A1,A2,4 ---> ) 4 ?PAIRS COMPILE (LOOP) <RESOLVE >RESOLVE ; IMMEDIATE : +LOOP ( A1,A2,4 ---> ) 4 ?PAIRS COMPILE (+LOOP) <RESOLVE >RESOLVE ; IMMEDIATE
Слово (DO), с которого начинается исполнение скомпилированного цикла со счетчиком, переносит на стек возвратов следующий за ним адрес конца цикла (он нужен для немедленного выхода из цикла по слову LEAVE) и параметры данного цикла — начальное и граничное значения счетчика, снимая их с вершины стека данных. Эти значения находятся на вершине стека возвратов в течение всего времени исполнения тела цикла.
Слово (LOOP), завершающее скомпилированный цикл, продвигает текущее значение счетчика и в случае повторения цикла переводит указатель интерпретации на начало тела по скомпилированному вслед за ним адресу перехода, а при завершении цикла сбрасывает стек возвратов в исходное состояние.
Аналогично работает и слово (+LOOP), которое дополнительно снимает со стека данных значение шага цикла. Разумеется, реализация этих слов должна соответствовать принятому способу задания переходов в шитом коде. Для прямых адресов перехода соответствующие определения можно задать так:
: (DO) ( A2:ГРАНИЧНОЕ,A1:НАЧАЛЬНОЕ ---> ) R> ( A2,A1,R:ВОЗВРАТ) DUP @ >R ( ДЛЯ LEAVE) ROT >R ( ГРАНИЧНОЕ) SWAP >R ( НАЧАЛЬНОЕ) 2+ >R ( ОБОЙТИ АДРЕС В ШИТОМ КОДЕ) ) : (LOOP) ( ---> ) R> R> R@ ( R:ВОЗВРАТ,I:ТЕКУЩЕЕ,A2:ГРАНИЧНОЕ) - 0 1.
D+ ( R,I-A2+1,F:ПРИЗНАК ЗАВЕРШЕНИЯ) IF ( ЗАКОНЧИТЬ) DROP R> R> 2DROP 2+ ( ОБОЙТИ АДРЕС ) ELSE ( ПРОДОЛЖИТЬ) R@ + >R ( НОВОЕ ЗНАЧЕНИЕ СЧЕТЧИКА) @ ( АДРЕС НАЧАЛА ТЕЛА ЦИКЛА) THEN >R ;
Определение (+LOOP) выглядит аналогично.
Во всех приведенных примерах доступ к адресу возврата в шитом коде осуществляется через стек возвратов из данного определения. Этот адрес модифицируется словами 2+ или @, тем самым обеспечивая обход скомпилированной ссылки или переход по ее значению. Слова I и LEAVE, которые используются внутри тела цикла для получения текущего значения счетчика и немедленного выхода из цикла, можно задать так:
: I ( ---> A ) R> R@ SWAP >R ; : LEAVE ( ---> ) R> DROP R> DROP R> DROP ;
Для повышения быстродействия практические реализации языка Форт обычно определяют все эти слова, как и BRANCH, в виде подпрограмм нижнего уровня в машинном коде. В этом случае, например, слово I полностью эквивалентно слову R@.
Описанная реализация циклов со счетчиком через использование стека возвратов накладывает ограничения при программировании. Неосмотрительное включение слов >R, R>, R@ и EXIT в тело цикла со счетчиком может привести к непредсказуемому результату.
Вместе с тем отстутствие какого-либо контроля является еще одной характерной чертой языка Форт. Благодаря этому программист может реализовать любые конструкции (включая и средства контроля).
Структура словарной статьи
Каждое слово-команда, известное форт-системе, хранится в оперативной памяти (в словаре) в виде специальной структуры данных — словарной статьи, состоящей из поля имени, поля связи, поля кода и поля параметров. Стандарт не фиксирует порядок взаимного расположения этих полей, оставляя его на усмотрение разработчиков реализации. Как правило, поля располагаются подряд в том порядке, как они перечислены выше.
Поля имени и связи вместе образуют заголовок словарной статьи, который нужен для поиска статьи по имени слова. Результатом поиска являются поля кода и параметров, которые вместе образуют собственно тело словарной статьи, определяющее действие, связанное с данным словом, т.е. его семантику. Согласно стандарту словарную статью представляет адрес ее поля кода, исходя из которого можно получить адреса всех других ее полей. Поскольку именно этот адрес компилируется в шитый код, то он также называется адресом компиляции.
Поле имени содержит имя слова в виде строки со счетчиком. Стандарт ограничивает максимальную длину имени 31 литерой (5 двоичными разрядами), чтобы остающиеся разряды в байте счетчика можно было использовать под специальные признаки. Важнейший из них — признак немедленного исполнения, который обычно занимает старший разряд байта-счетчика. Таким образом, поле имени имеет переменную длину, которая определяется значением счетчика.
Поле связи занимает 2 байта и содержит адрес заголовка предыдущей словарной статьи. Через это поле словарные статьи связаны в цепные списки, в которых можно вести поиск статьи по имени слова. Поле связи первой статьи в списке содержит некоторое специальное значение, обычно нуль. Новые слова добавляются в конец списка, и поиск слов ведется от конца списка к началу.
Тело словарной статьи реализуется через шитый код в одной из его разновидностей. Для определенности примем за основу косвенный шитый код. В этом случае интерпретатор шитого кода называется адресным интерпретатором форт-системы, поскольку интерпретирует последовательность адресов, каждый из которых является адресом компиляции некоторой словарной статьи (адресом ее поля кода).
В качестве собственных данных адресный интерпретатор использует стек возвратов и указатель на текущее место в интерпретируемой последовательности адресов.
Поле кода словарной статьи в случае косвенного шитого кода занимает 2 байта и содержит адрес машинной программы, которая и выполняет действие, связанное с данным словом. Точка NEXT адресного интерпретатора обеспечивает этой программе доступ к полю параметров данной словарной статьи. Для статей, соответствующих определению через двоеточие, поле кода содержит адрес точки CALL адресного интерпретатора, а поле параметров представляет собой последовательность адресов словарных статей, входящих в данное определение. Завершается такая последовательность адресом словарной статьи EXIT (выход), который компилируется завершающей данное определение точкой с запятой. Для словарных статей нижнего уровня, т.е. реализованных непосредственно в машинном коде, поле кода содержит адрес соответствующей машинной программы, которая обычно располагается в поле параметров этой статьи. Таким образом, можно сказать, что поле кода словарной статьи содержит адрес машинной программы-интерпретатора поля параметров. Все слова, определенные через двоеточие, имеют в качестве интерпретатора действие CALL адресного интерпретатора, слова нижнего уровня наоборот имеют каждое свой отдельный интерпретатор в виде машинной программы, размещенной в поле параметров. В частности, такой программой для слова EXIT является действие RETURN адресного интерпретатора.
На рис. 2.4. приведены адресный интерпретатор и структура словарной статьи для определения
: F ( A ---> A*[A+1]/2 ) DUP 1+ 2 */ ;
вычисляющего сумму натуральных чисел от 1 до A по известной формуле. В качестве языка нижнего уровня для записи действий адресного интерпретатора применяется очевидная нотация. Переменная RI обозначает указатель текущего места в интерпретируемом коде, процедура MEM дает значение, находящееся по заданному адресу в памяти форт-системы. Процедуры RPUSH и RPOP используются для обращения к стеку возвратов с тем, чтобы положить значение на его вершину и снять верхнее значение.
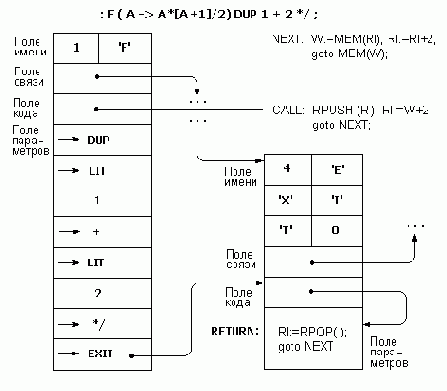
Рис. 2.4. Адресный интерпретатор и структура словарной статьи для косвенного шитого кода
На рис. 2.4 изображены две словарные статьи: верхнего уровня для слова F, определенного через двоеточие, и нижнего уровня для слова EXIT, являющаяся к тому же частью адресного интерпретатора.
Поле имени каждой статьи начинается байтом-счетчиком, в котором записано число литер в имени слова. Далее располагаются коды самих этих литер.
Вслед за полем имени идет поле связи, содержащее адрес поля имени предыдущей словарной статьи. В тех реализациях, где двухбайтные значения должны располагаться с четного адреса, поле имени тоже располагают с четного адреса, дополняя его (как в случае слова EXIT) до четного числа байт специальным кодом (обычно пробелом или нулем).
Поле кода словарной статьи содержит адрес машинной программы. Для слова F это адрес точки CALL адресного интерпретатора, для слова EXIT — адрес его поля параметров, где и располагается соответствующая программа.
Наконец, в соответствии с техникой шитого кода в поле параметров статьи для слова F располагается последовательность адресов полей кода словарных статей тех слов, из которых составлено его определение. В этих адресах перед именем слова стоит знак ->. Скомпилированное число занимает две ячейки: в первой находится адрес специального служебного слова LIT (от LITERAL — литерал), а во второй — значение данного числа. Действие слова LIT состоит в том, что значение числа кладется на стек данных, а указатель интерпретации передвигается дальше, обходя это значение в шитом коде:
LIT: W:=MEM(RI); PUSH(W); RI:=RI+2; goto NEXT;
Здесь используется тот факт, что в момент перехода на очередную машинную программу в действие NEXT указатель текущего места RI уже установлен на следующий элемент интерпретируемой последовательности адресов.
Адреса полей словарной статьи имеют традиционные обозначения, которые представляют аббревиатуры их английских названий:
NFA - Name Field Address - адрес поля имени LFA - Link Field Address - адрес поля связи CFA - Code Field Address - адрес поля кода PFA - Parameter Field Address - адрес поля параметров
Представлением словарной статьи считается адрес ее поля кода. Стандартное слово >BODY (от body — тело) CFA --> PFA преобразует его в адрес поля параметров. По аналогии во многих реализациях введен следующий ряд слов для переходов между остальными полями статьи:
BODY> PFA ---> CFA >NAME CFA ---> NFA NAME> NFA ---> CFA N>LINK NFA ---> LFA L>NAME LFA ---> NFA
Их реализация определяется принятой структурой словарной статьи.
Стандарт предусматривает слово EXECUTE (исполнить) CFA -->, которое снимает со стека адрес поля кода словарной статьи и исполняет ее. Непосредственно под этим значением в стеке должны находиться параметры, необходимые данному слову. Такой механизм открывает широкие возможности для передачи слов-команд в качестве параметров.
Управление поиском слов
Множество слов, «известных» форт-системе, хранится в словаре в виде одного или более цепных списков словарных статей, соединенных через поле связи. Порядок поиска статей в этих списках обратен порядку их включения в словарь по времени определения: статья последнего определенного слова находится в начале списка. Такой порядок делает естественным исключение слов из словаря с помощью слова FORGET: нужный список просто усекается до соответствующего места.
Являясь самостоятельной структурой данных, список слов имеет и соответствующее определяющее слово — VOCABULARY (словарик, список слов) -->, аналогичное слову VARIABLE. Оно выделяет из входной строки очередное слово и определяет его как новый список слов, например, VOCABULARY A.
Со списками слов тесно связаны две стандартные переменные CONTEXT (контекст) и CURRENT (текущий) и слово FORTH (Форт), обозначающее список, который состоит из всех стандартных слов и включает, в частности, само это слово.
Поиск каждого введенного слова начинается в списке, на который указывает переменная CONTEXT, затем в случае неудачи просматривается список — текущее значение переменной CURRENT. Стандарт требует, чтобы последним просмотренным списком всегда был список FORTH. Исполнение слова, обозначающего список, делает его текущим значением переменной CONTEXT, т.е. первым списком, который просматривается при поиске слов.
Стандартное слово DEFINITIONS (определения)
: DEFINITIONS ( ---> ) CONTEXT @ CURRENT ! ;
устанавливает переменную CURRENT по текущему значению переменной CONTEXT, т.е. соответствующий список становится вторым на очереди для просмотра и одновременно тем списком, куда добавляются новые словарные статьи. Первоначально обе эти переменные установлены на один и тот же список FORTH. К этому состоянию приводит исполнение текста FORTH DEFINITIONS. Разумеется, в этом случае поиск слов будет состоять в одноoкрaтнoм просмотре списка слов FORTH.
Приведенное выше описание определяет порядок поиска лишь в общих чертах.
Детали стандарт оставляет на усмотрение разработчиков реализации. Обычно используется схема, приведенная на рис. 2.7. Для каждого списка в поле параметров его статьи строится заголовок «фиктивной» статьи для невозможного слова (например, состоящего из одного пробела), и представлением списка (значением переменных CONTEXT и CURRENT) служит адрес поля связи этого заголовка, т.е. адрес второго элемента в поле параметров. Сам этот элемент является входом в цепной список словарных статей, принадлежащих данному списку слов. В качестве его начального значения в момент создания списка словом VOCABULARY используется адрес поля параметров словарной статьи другого списка, который таким образом является базовым для данного (обычно это текущее значение переменной CONTEXT).
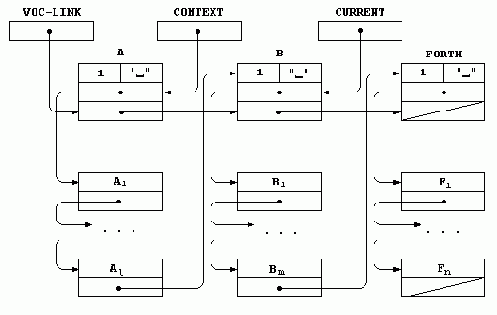
Рис. 2.7. Структура списков словарных статей
Таким образом, новый список через заголовок фиктивной статьи присоединяет к себе все слова базового списка.
В конечном счете любой список заканчивается словами списка FORTH, который уже не имеет базового. На рис. 2.7 показаны поля параметров списков A, B и FORTH. Список B является базовым для A и, в свою очередь, базируется на списке FORTH. Слова A1, ... , Al входят в список A, B1, ... , Bm — в B и F1, ... , Fn — в FORTH.
Показанный на рисунке порядок поиска слов соответствует исполнению текста B DEFINITIONS A, в результате чего сначала будут просмотрены списки A, B, FORTH, а затем B, FORTH.
Чтобы обеспечить большую гибкость в управлении порядком поиска слов и иметь возможность переопределять стандартные слова, в некоторых реализациях предусмотрено создание безбазовых списков. Это списки, создаваемые в контексте списка FORTH, для которых FORTH был бы базовым. Наличие безбазовых списков компенсируется тем, что в алгоритме поиска последним действием после просмотра списков, определяемых переменными CONTEXT и CURRENT, просматривается список FORTH, если он еще не был просмотрен через эти переменные.
Для учета всех существующих списков (что необходимо для реализации слова FORGET) в их поле параметров резервируется еще одна ячейка: через которую все эти структуры связаны в единый цепной список, начинающийся в служебной переменной VOC-LINK.
Определение слова VOCABULARY с учетом перечисленных соглашений может выглядеть так:
: VOCABULARY ( ---> ) CREATE 256 BL + , CONTEXT @ 2- , HERE VOC-LINK @ , VOC-LINK ! DOES> ( A ---> ) 2+ CONTEXT ! ;
Когда в список включается новая словарная статья, то в поле связи ее заголовка копируется значение из поля связи фиктивной статьи в поле параметров данного списка, а туда заносится адрес нового заголовка. Таким образом, можно определить слово LATEST (последний):
: LATEST ( ---> NFA ) CURRENT @ @ ;
которое возвращает адрес заголовка последней созданной словарной статьи (обычно это адрес поля имени). Через это слово становится очевидной, например, реализация слова IMMEDIATE:
: IMMEDIATE ( ---> ) LATEST C@ 128 OR LATEST С! ;
которое устанавливает в единицу признак немедленного исполнения в байте-счетчике последней созданной словарной статьи.
В соответствии с общими принципами языка Форт сам процесс поиска слова в словаре доступен программисту. Стандарт предусматривает для этого следующие слова:
' ---> CFA ['] ---> CFA (испонение) [COMPILE] ---> (КОМПИЛЯЦИЯ) FIND A ---> CFA,N / A,0
Слово ' (апостроф, читается «штрих») вводит очередное слово и ищет его в словаре, возвращая адрес поля кода найденной статьи (если слово не найдено, то это считается ошибкой).
Слово ['] имеет признак немедленного исполнения и используется внутри определений через двоеточие, образуя вместе со следующим словом единую пару: во время исполнения адрес поля кода этого слова будет положен на стек данных.
Слово [COMPILE], уже встретившееся ранее, вводит и компилирует следующее слово независимо от признака немедленного исполнения.
Наконец, слово FIND (найти) позволяет формировать образец для поиска программным путем: его параметром является адрес строки со счетчиком, которая рассматривается как имя слова. В случае успеха FIND возвращает адрес поля кода его словарной статьи и значение N, характеризующее признак немедленного исполнения: 1, если признак установлен, и -1, если отсутствует.
В случае неудачи слово FIND возвращает прежний адрес строки со счетчиком и значение 0 — сигнал о неудаче.
Разумеется, слова ' и ['] используют слово FIND :
: ' ( ---> A ) BL WORD FIND IF EXIT THEN COUNT TYPE -1 ABORT" ?" ; : ['] ( ---> ) ' COMPILE LIT , ; IMMEDIATE : [COMPILE] ( ---> ) ' , ; IMMEDIATE
которое, таким образом, является основным в определении порядка поиска слов.
В заключение рассмотрим определение стандартного слова FORGET, которое вводит очередное слово, ищет его в словаре и исключает из словаря вместе со всеми словами, определенными после него.
Служебная переменная FENCE (забор) защищает начальную часть словаря от случайного уничтожения. Она содержит адрес, отмечающий границу защищенной части (чтобы исключить слова из защищенной области нужно сначала понизить это значение):
: FORGET ( ---> ) >NAME ( NFA) DUP FENCE @ U< ABORT" ЗАЩИТА ПО FENCE" >R VOC-LINK ! ( NO:ВХОД В СПИСОК СПИСКОВ) BEGIN R@ OVER U< WHILE ( N:ЗВЕНО СВЯЗИ СПИСКА) FORTH DEFINITIONS @ DUP VOC-LINK ! ( N1:ЗВЕНО СЛЕДУЩЕГО) REPEAT ( N1:ЗВЕНО ОСТАВШЕГОСЯ СПИСКА) BEGIN DUP 4 - ( N:ЗВЕНО СВЯЗИ,L:ВХОД В СЛОВА) BEGIN N>LINK @ ( N,NFA:ОЧЕРЕДНОЕ СЛОВО) DUP R@ U< UNTIL ( N,NFA:ОСТАЮЩЕЕСЯ СЛОВО) OVER 2- ( N,NFA1,L:АДРЕС СВЯЗИ ФИКТИВНОЙ СТАТЬИ) ! @ ?DUP 0= UNTIL R> ( NFA0 ) HERE - ALLOT ;
Сначала определяется адрес статьи исключаемого слова, проверяется, что она расположена выше границы защиты, и этот адрес сохраняется на стеке возвратов. В ходе исполнения первого цикла перебираются все существующие статьи для списков слов и исключаются те, адреса которых оказались больше данного (в силу монотонного убывания адресов в цепном списке VOC-LINK цикл прекращается, как только адрес очередной статьи оказывается меньше данного). Во время исполнения второго цикла продолжается перебор оставшихся статей для списков слов, при этом в каждом списке отсекаются статьи, адреса которых больше данного (здесь опять используется монотонное убывание адресов словарных статей в пределах одного списка).В заключение указатель вершины словаря понижается до заданного адреса, тем самым освобождая память в словаре. Перед началом описанных действий переменные CONTEXT и CURRENT устанавливаются на список FORTH, чтобы их значение было осмыслено во все время дальнейшей работы.
Встроенный ассемблер
Встроенный ассемблер позволяет программисту задавать реализацию слов непосредственно в машинном коде данной ЭВМ. Это дает ему возможность, с одной стороны, повышать быстродействие программы до максимально возможного уровня за счет перевода интенсивно используемых слов непосредственно в машинный код, а с другой — использовать особенности архитектуры данной ЭВМ и «напрямик» связываться с операционной системой и внешним окружением.
Примеры обоих случаев дает сама форт-система. Очевидно, что слова, выполняющие арифметические операции или действия с вершиной стека, естественно реализовывать непосредственно в машинном коде, поскольку скорость их исполнения в значительной степени определяет быстродействие системы. Вместе с тем слово 1+, увеличивающее на единицу значение на вершине стека, можно определить как в машинном коде (особенно если в данной ЭВМ есть специальная команда увеличения значения на единицу), так и через двоеточие:
: 1+ ( A ---> A+1 ) 1 + ;
В последнем случае, если к тому же слово 1 реализовано в виде отдельной словарной статьи 1 CONSTANT 1, шитый код займет всего три ячейки, что может быть короче аналогичной программы в машинном коде. Разумеется, при этом исполнение будет дольше за счет интерпретации последовательности из трех ссылок вместо прямого исполнения соответствующих машинных команд. Также очевидно, что, например, форт-слова для обмена с терминалом естественно задать на машинном уровне через обращения к соответствующим функциям операционной системы или непосредственно к аппаратуре.
Для определения слов непосредственно в машинном коде стандарт языка Форт предусматривает следующие слова:
ASSEMBLER ---> CODE ---> END-CODE ---> ;CODE ---> (компиляция)
составляющие стандартное ассемблерное расширение обязательного набора слов.
Слово ASSEMBLER (ассемблер) является именем списка слов, содержащего слова, с помощью которых строится машинный код (мнемоники машинных команд, обозначения регистров, способы адресации и т.д.).
Слово CODE (код) является определяющим для слов нижнего уровня и обычно определяется так:
: CODE ( ---> ) CREATE HERE LATEST NAME> ! ASSEMBLER ;
Оно используется в сочетании со словом END-CODE (конец кода): CODE <имя> <машинный-код> END-CODE, где «имя» является именем определяемого слова, а «машинный-код» — записью его реализации в машинном коде в соответствии с принятыми соглашениями.
Поле кода такой словарной статьи содержит адрес ее поля параметров, в котором располагается данный машинный код.
Наконец, слово ;CODE, имеющее признак немедленного исполнения, позволяет задавать исполняющую часть определяющих слов непосредственно в машинном коде:
: ;CODE ( ---> ) COMPILE (;CODE) [COMPILE] [ ASSEMBLER ; IMMEDIATE
Оно используется внутри определения через двоеточие для определяющего слова аналогично слову DOES>:
: <имя> <создающая-часть> ;CODE <машинный-код> END-CODE
и отделяет высокоуровневую создающую часть от исполняющей части, заданной в машинном коде. Во время исполнения скомпилированного словом ;CODE слова (;CODE) адрес машинной программы, составляющей исполняющую часть, будет заслан в поле кода определяемого слова, которое таким образом получит интерпретатор, реализованный в машинном коде. На практике именно таким способом задают стандартные определяющие слова — :, CONSTANT и VARIABLE.
Конкретный вид машинной программы зависит от архитектуры данной ЭВМ. Общим правилом является то, что этот текст представляет собой последовательность слов, которые исполняются текстовым интерпретатором, в результате чего на вершине словаря формируется соответствующий двоичный машинный код. Машинные команды записываются в естественной для Форта обратной польской форме: сначала операнды, а затем слово, обозначающее мнемонику команды.
Операнды — это слова, вычисляющие на стеке размещения операндов: номера регистров, адреса в памяти и их модификации, значения непосредственных операндов и т.д.
Мнемоника команды, обычно состоящая из традиционного обозначения данной команды и запятой, снимает со стека размещения своих операндов и компилирует соответствующий двоичный код.
Включение запятой в имя слова для кода команды, с одной стороны, подчеркивает тот факт, что данное слово компилирует команду, а с другой стороны, позволяет отличать, например, часто встречающиеся мнемоники ADD, СН и т.д. от чисел, заданных в шестнадцатиричной системе.
В табл. 2.1 приведена запись одних и тех же машинных команд в традиционном ассемблере и встроенном ассемблере разных форт-систем для нескольких распространенных типов ЭВМ. Как и в случае реализации структур управления, во встроенный ассемблер можно включить дополнительные средства контроля, которые, учитывая формат машинных команд, проверяют правильность задания их операндов.
Таблица 2.1. Сравнительная запись машинных команд в традиционном ассемблере и встроенном ассемблере форт-системы
| СМ-4 | CMPB #12, (R1)+ JMP NEXT RTS |
12 # R1 )+ CMPB, NEXT JMP, RTS, |
| ЕС ЭВМ | STM 14,12,12(13) BALR 15,0 B NEXT |
14 12 12 (, 13 STM, 15 0 BALR, NEXT B, |
| К580 | MOV A,B LXI H,15 POP H |
A B MOV, H 15 LXI, H POP, |
| БЭСМ-6 | , UTC, =I5 , XTA, 3, UTC, 777 |
0 0 5 # # UTC, 0 0 XTA, 3 777 UTC, |
Встроенный ассемблер форт-систем часто делают «структурным», т.е. включают в него операторы ветвления и циклы, выполняющие переходы по значению управляющих разрядов в специальном регистре. По аналогии с такими же средствами языка Форт эти структуры задают с помощью тех же слов с добавлением запятой: IF, THEN, ELSE, BEGIN, UNTIL, и т.д. При этом вводят слова, обозначающие различные состояния управляющих сигналов, а слова, реализующие структурные операторы компилируют команды переходов, соответствующие указанным состояниям.
Такой подход позволяет во многих случаях избежать введения сложного механизма переходов на метку, поскольку ассемблерные вставки, для трансляции которых и существует встроенный ассемблер, состоят, как правило, из нескольких команд.
Программа в машинном коде, заданная через слова CODE или ;CODE, получает управление от адресного интерпретатора и после ее завершения возвращает управление интерпретатору на точку NEXT. Для связи с адресным интерпретатором в списке слов ASSEMBLER обычно предусматривается ряд констант, обозначающих точки входа, номера регистров и другие ресурсы адресного интерпретатора. Аналогичным образом предусматривается связь с операционной системой, встроенным постоянным программным обеспечением и аппаратурой.
В общем объеме больших программ на Форте ассемблерные коды составляют незначительную часть (в реализации самой форт-системы, например, 10-30%), но вместе с тем такая возможность делает программиста максимально свободным в выборе средств для реализации своих идей.