АДРЕСАЦИЯ ПОЛЕЙ
При изучении полей, составляющих структуру словаря, важно понять различие между адресами этих полей и их содержимым. По соглашению адрес, по которому содержится указатель кода, называется адресом поля кода (cfa). Следовательно, cfa слов содержат указатель кода периода их выполнения.
Адрес первой ячейки, в которой хранится параметр, называется адресом поля параметров (pfa).
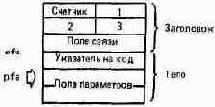
Адрес, помещаемый в стек апострофом, в одних реализациях является cfa, в других - pfa. Стандарт предусматривает слово >BODY, осуществляющее переход от cfa к pfa.
Таким образом, имеется возможность (хотя это далеко не «стандарт» и не может быть рекомендовано к применению) изменять значение существующей константы, например: n ' ПРЕДЕЛ >BODY !
Если ваша система отличается от той, с которой мы работаем, обращайтесь к столбцу 4 приведенной ранее таблицы, где излагаются правила вычисления адреса для EXECUTE.
Между прочим поля имени и связи часто называют заголовком элемента, а поля указателя кода и параметров - его телом.
АЛЬТЕРНАТИВНАЯ ВЕТВЬ УСЛОВНОГО ОПЕРАТОРА
Форт позволяет вам написать в рамках оператора IF с помощью слова ELSE (ИНАЧЕ) альтернативное выражение, В приведенном ниже примере дается определение, которое проверяет, является ли заданное число правильной календарной датой: : ?ДЕНЬ ( день) 32 < IF ." Путь открыт " ELSE ." Объезд " THEN ;
Если число в стеке меньше 32, то будет выдано сообщение «ПУТЬ ОТКРЫТ». В противном случае выдается сообщение «ОБЪЕЗД».
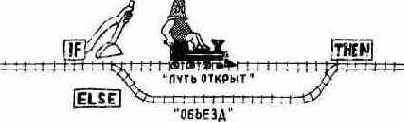
Представьте себе, что IF переключает стрелку железнодорожной колеи в зависимости от результатов проверки условия, после чего выполнение пойдет по одному из двух маршрутов, но в любом случае рельсы сойдутся у слова THEN. В компьютерной терминологии изменение путей выполнения операторов называется ветвлением 1.
Рассмотрим еще один пример. Как известно, деление любого числа на нуль невозможно, поэтому если вы попытаетесь выполнить эту операцию на каком-нибудь компьютере, то получите неправильный ответ.
Можно определить некоторое слово, выполняющее деление в том случае, если делитель не равен нулю2:: /ПРОВЕРКА ( числитель знаменатель -- результат ) DUP 0= IF ." Знаменатель нуль " DROP ELSE / THEN ;
Заметим, что сначала вы должны с помощью DUP создать копию знаменателя, так как выражение 0= IF
в процессе своего выполнения уничтожит его. Кроме того, слово DROP удаляет знаменатель, если деление не выполняется, так что независимо от того, будет ли выполняться деление, состояние стека в обоих случаях окажется одинаковым, т. е. независимо от того, выполнялась ли часть IF или ELSE, в стеке будет оставлен один аргумент. (Случай, когда указанные две части оставляют в стеке различное число аргументов, являются источником самых коварных ошибок: иногда при этом ваша программа работает, а иногда — нет.)
АПОСТРОФ В ОПРЕДЕЛЕНИИ
Согласно Стандарту-83 апостроф всегда пытается найти следующее слово во входном потоке. Что произойдет, если мы поместим апостроф внутрь какого-либо определения? При исполнении такого определения апостроф будет искать следующее слово из входного потока. Таким образом, мы можем определить: : СКАЖИ ( имя ( -- ) ' 'ФРАЗА ! ;
(Если у вас иная система, обратитесь к столбцу 2 вышеприведенной таблицы.) Необычный стековый комментарий означает, что слово СКАЖИ будет «заглядывать» вперед по входному потоку в поисках очередного слова.
Теперь можно ввести:СКАЖИ ПРИВЕТ ok ФРАЗА Привет ok
или
СКАЖИ ДО-СВИДАНИЯ ok
ФРАЗА До свидания ok
Апостроф в слове СКАЖИ осуществляет поиск имени определенных слов ПРИВЕТ и ДО-СВИДАНИЯ во входном потоке во время выполнения слова СКАЖИ. Во время определения этого слова апостроф ничего не делает (разве что позволяет себя компилировать).
А как быть, если нужно специфицировать посредством апострофа адрес следующего слова в определении? Для этого имеется слово ['], которое применяется вместо слова ', например1:: ПРИХОДЯ ['] ПРИВЕТ 'ФРАЗА ! ; : УХОДЯ ['] ДО-СВИДАНИЯ 'ФРАЗА ! ;
Введите следующий текст: ПРИХОДЯ ok ФРАЗА Привет ok УХОДЯ ok ФРАЗА До свидания ok
1 Для пользователей небольших систем. Если на вашей клавиатуре нет клавиши «[» или «]», то в документации по Форт-системе должна быть указана замена.
В столбце 3 приведенной выше таблицы изложены правила выполнения этих действий на каждом из диалектов Форта. Далее дается список команд, которые мы уже рассмотрели.
| ' xхх | ( -- а) | Осуществляется поиск в словаре адреса слова ххх (следующего слова во входном потоке). |
| ['] | период-компиляции: ( -- ) период-выполнения: ( -- а) | Используется только в определении через двоеточие. Компиляция адреса следующего слова в определении как литерала. |
| EXECUTE | ( а -- ) | Исполнение элемента словаря, адрес поля параметров которого находится на стеке. |
| @EXECUTE | ( а -- ) | Исполнение элемента словаря, адрес которого является содержимым а. Если по адресу a находится нуль, @ЕХЕCUТЕ ничего не выполняет. |
АППРОКСИМАЦИЯ ВЕЩЕСТВЕННЫХ ЧИСЕЛ
До сих пор мы применяли масштабирование для выполнения операции над вещественными числами. Масштабирование также может использоваться для представления иррациональных констант вещественными значениями, например числа
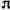
С помощью определения вычислим площадь круга с радиусом 10 дюймов: 10 ПЛОЩАДЬ . 314 ok
Для получения еще большей точности мы могли бы поискать другую пару чисел, которая давала бы лучшее приближение. Как ни странно, такая пара есть. Это дробь 355 113 */
обеспечивающая точность, большую, чем шесть знаков после запятой, в то время как 31416 - обеспечивает менее четырех знаков
Следовательно, наше новое, улучшенное определение будет иметь вид: : PI ( n -- n') 355 113 */ ;
Оказывается, вы можете хорошо аппроксимировать любую константу посредством множества различных пар целых чисел, значения которых меньше, чем 32768, с погрешностью менее 10-8'.
АРИФМЕТИЧЕСКИЕ ОПЕРАЦИИ НАД ЧИСЛАМИ С ПЛАВАЮЩЕЙ ТОЧКОЙ
Вокруг Форта ведется много споров. Некоторые принципы, которых фанатически придерживаются программирующие на Форте, считаются неразумными в среде сторонников традиционных языков. Одним из предметов спора является вопрос выбора между представлениями числа «с фиксированной точкой» и «с плавающей точкой». Если вы уже поняли смысл этих терминов, то можете опустить данный материал и познакомиться с высказанной ниже нашей точкой зрения. Начинающим же полезно прочитать следующее объяснение.
Во-первых, что такое плавающая точка? Возьмем, к примеру, карманный калькулятор и посмотрим, как высвечивается результат на его индикаторе после ввода очередного значения:

Десятичная точка «плавает» по индикатору по мере необходимости. Такой индикатор называется индикатором с плавающей точкой. Представление с плавающей точкой - это способ записи чисел в компьютере в виде мантиссы и порядка. Например, 12 млн. можно записать как 12x106, поскольку 106 равно 1 млн. Во многих компьютерах 12 млн. должно быть записано в виде двух чисел 12 и 6, что воспринимается как 106, умноженное на 12. Число 3.345 будет записано так: 3345 и -3.
Идея представления чисел в форме с плавающей точкой состоит в том, чтобы компьютер мог представить необозримо большой диапазон чисел - от мизерных до астрономических - двумя сравнительно небольшими числами.
Представление с фиксированной точкой - другой способ записи чисел в память, при котором положение десятичной точки числа не запоминается. Например, при вводе суммы в долларах и центах все значения должны запоминаться в центах, а расположение десятичной точки должно «помнить» не само число, а программа.
Сравним для иллюстрации три представления чисел: общепринятое, с фиксированной точкой и с плавающей точкой:ОБЩЕПРИНЯТОЕ С ФИКСИРОВАННОЙ С ПЛАВАЮЩЕЙ ПРЕДСТАВЛЕНИЕ ТОЧКОЙ ТОЧКОЙ
1.23 123 123(-2) 10.98 1098 1098(-2) 100.00 10000 1( 2) 58.60 5860 586(-1)
Как видите, в представлении с фиксированной точкой все значения следуют одному шаблону. Компьютер в этом случае интерпретирует все числа как целые. Программа, прежде чем выдать ответ на экран терминала или алфавитно-цифровое печатающее устройство, вставляет десятичную точку после двух цифр справа
АРИФМЕТИЧЕСКИЙ СДВИГ
Когда мы рассматривали в гл. 5 выполнение компьютером некоторых арифметических операций, нам встретились две «таинственные» фразы: «арифметический сдвиг влево» и «арифметический сдвиг вправо». Теперь настала пора объяснить их.
От чего зависит быстрота ответа Форт-системы. 2* ( n -- n*2) Умножение на два ( арифметический сдвиг влево). 2/ ( n -- n/2) Деление на два ( арифметический сдвиг вправо).
Для иллюстрации представим какое-нибудь число, скажем шесть, в двоичном виде:
0000000000000110
(4 + 2). Сдвинем каждую цифру этого числа на один разряд влево, а освободившийся бит заполним нулем:
0000000000001100
Мы получили двоичное представление числа 12 (8 + 4), что ровно в два раза больше первоначального числа. Такой способ применим во всех случаях. Если вы переместите каждую цифру числа на одну позицию вправо и заполните освободившийся бит нулем, то в результате всегда получите половину первоначального числа.
При арифметическом сдвиге знаковый разряд не смещается. Иными словами, положительное число остается положительным, а отрицательное - отрицательным при выполнении операций деления и умножения на два. (Сдвиг, при котором вместе с остальными битами сдвигается и старший по порядку бит, называется логическим сдвигом.) Вы должны знать, что компьютер выполняет сдвиг цифр намного быстрее, чем операции обычного деления или умножения. Когда скорость критична, то лучше написать 2*, чем 2 *, и даже может быть лучше написать 2* 2* 2*, чем 8 * - все зависит от конкретной модели вашего компьютера.
БЕЗ ВЗВЕШИВАНИЯ
В качестве второго примера приведем математическую задачу, решение которой, по мнению многих, невозможно без привлечения операций над числами с плавающей точкой. Мы покажем вам, как арифметика с фиксированной точкой позволяет решать довольно сложные уравнения, и при этом ни диапазон, ни точность представления чисел не ухудшаются.
Вычислим вес конусообразной «кучи» некоторого материала, зная ее высоту и угол откоса, а также плотность материала. Чтобы сделать нашу задачу более конкретной, давайте взвесим кучи песка, гравия и цемента. Крутизна каждой кучи, называется углом естественного откоса, зависит от вида материала. Например, песчаные кучи более крутые, чем из гравия.

(На самом деле эти величины колеблются в большом диапазоне в зависимости от разных факторов. Для иллюстрации мы выбрали приблизительные значения угла откоса и плотности.)
Существует формула вычисления массы конусообразной кучи высотой h (в футах), углом естественного откоса 9 (в градусах) и плотностью материала D (в фунтах на кубический фут)1:
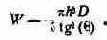
Запишем эту формулу на Форте. Условимся считать, что аргументы нашей программы будут вводиться в такой последовательности: название материала, например ПЕСОК, а затем высота кучи. В результате выполнения программы мы должны получить массу кучи сухого песка. Допустим, что для любого материала его плот-
1 Для скептиков. Объем конуса V вычисляется по формуле

где b - радиус основания; h - высота. Мы можем найти радиус основания, зная угол откоса, или, более точно, тангенс этого угла. Тангенсом некоторого угла называется отношение катета противолежащего (на рисунке h) к катету прилежащему (на рисунке b):
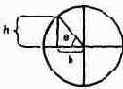
Если обозначить этот угол через


ность и угол естественного откоса остаются неизменными. Поэтому можно записать указанные две величины для каждого вида материала в некоторую таблицу.
Так как в конечном итоге нам потребуется тангенс угла, а не его величина в градусах, будем хранить значение тангенса. Например, угол естественного откоса для цемента составляет 35°, а его тангенс равен .700. Мы будем хранить это значение в виде целого 700.

Помните, что наша цель заключается не в том, чтобы просто получить результат. Мы составляем такую программу, по которой компьютер или иное вычислительное устройство выдает ответ самым быстрым, самым эффективным и самым точным способом. Как уже отмечалось в гл. 5, для записи математических выражений посредством арифметики с фиксированной точкой вам придется приложить немало усилий. Но вы будете вознаграждены за свои страдания. Во-первых, значительно увеличится скорость выполнения, что очень важно в тех случаях, когда какой-нибудь процесс разбивается на миллионы шагов или когда ежеминутно приходится производить несколько тысяч операций. Во-вторых, уменьшится размер программы и вы сможете, например, выполнить ее с помощью калькулятора, специально предназначенного для вычисления веса материала. Форт часто применяется в такого рода машинках.
Начнем решение задачи с установления порядка величин. Высота всех трех куч лежит в пределах от 5 до 50 футов. Вычислив массу кучи цемента, мы получим 35 000 000 фунтов. Но так как кучи не имеют форму правильного конуса, а мы берем средние зна чения величин, точность вычислений не может превышать четырех или пяти порядков1. Если перевести наш результат в тонны, то получим 17 500 т. Это значение вполне удовлетворяет представлению числа одинарной длины, так что в нашей программе условимся применять арифметические операции только над значениями одинарной длины.
Те программы, в которых требуется большая точность, могут быть написаны с использованием представления чисел двойной длины. Как вы увидите позднее, для сравнения мы даже создадим второй вариант нашей программы, где будут задействованы арифметические операции над 32-разрядными числами. Пока же мы хотим показать, что требуемую точность можно обеспечить, применяя операции Форта только с 16-разрядными значениями.
Выполнив вычисления для кучи высотой 40 футов, мы обнаружили, что изменение высоты на одну десятую может привести к изменению ее массы на 25 тонн. Поэтому входные данные будем исчислять не в целых футах, а в десятых долях фута. Желательно, чтобы пользователь имел возможность вводить следующее выражение: 15 ФУТОВ 2 ДЮЙМОВ КУЧА
где слова ФУТОВ и ДЮЙМОВ представляли бы футы и дюймы с точностью до десятых долей дюйма, а слово КУЧА производило бы необходимые вычисления. Слова ФУТОВ и ДЮЙМОВ можно было бы определить так:: ФУТОВ ( футы -- вес-в-масштабе) 10 * ; : ДЮЙМОВ { вес-в-масштайе -- вес-в-масштабе' ) 100 12 */ 5 + 10 / + ;
использование слова ДЮЙМОВ не обязательно. Таким образом, выражение 23 ФУТОВ поместит в вершину стека число 230, выражение 15 ФУТОВ 4 ДЮЙМОВ - число 153 и т. д. (Между прочим довольно легко организовать ввод данных и в десятых долях дюйма с десятичной точкой, например: 15.2. В таком случае слово NUMBER переводит вводимое число в значение двойной длины. Так как мы имеем дело только с числами одинарной длины, для того чтобы удалить старший байт, достаточно просто применить слово DROP.)
При написании определения КУЧА нужно попытаться обеспечить максимальную точность, не выходя за границы 15 разрядов. По нашей формуле первое, что требуется сделать, - возвести аргумент в куб. Однако напомним, что аргументом может служить
1 Для специалистов-математиков. На самом деле, так как высота в нашем примере выражается тремя цифрами, мы не можем ожидать точности большей, чем три порядка. Однако в учебных целях мы выберем точность, превышающую четыре порядка.
значение высоты вплоть до 50 футов, т. е. при выбранном масштабе 500. Даже если мы возведем это значение лишь в квадрат, то получим 250 000, что уже превышает возможности представления одинарной точности. Но для того чтобы выразить ответ в тоннах, рано или поздно в ходе вычислений нам придется выполнить деление на 2000, поэтому выражениеDUP DUP 2000 */
будет одновременно возводить аргумент в квадрат и переводить в тонны, так как под промежуточный результат в операции */ отводится слово двойной длины.
Если наш аргумент равен 500, то в результате получится 125.
Высота кучи может оказаться равной всего лишь пяти футам. Возведение этого значения в квадрат дает 25, а при делении последнего числа на 2000 средствами целочисленной арифметики мы получим нуль, что свидетельствует о неудачном выборе масштаба с небольшими значениями аргумента. Для обеспечения максимальной точности мы не должны при масштабировании получать меньшие значения, чем требуется. Число 250 000 вполне представимо средствами арифметики одинарных чисел, если его предварительно разделить на 10, поэтому мы начнем наше определение КУЧА следующим выражением:DUP DUP 10 */
На данном этапе результат с учетом масштабирования окажется в десять раз большим (25000 вместо 2500.0), чем требуется.
Далее необходимо возвести аргумент в куб. Непосредственное умножение опять приведет к результату двойной длины и, значит, масштабирование должно производиться с применением операции */. Как видите, выбрав в качестве делителя 1000, мы продолжаем оставаться в пределах одинарной длины. Теперь наш результат будет в десять раз меньшим (12 500 вместо 125 000), чем требуется, и все еще сохраняется точность в пять знаков. Согласно приведенной выше формуле нужно умножить аргумент на pi. Вы знаете, что на Форте это можно сделать с помощью следующего выражения: 355 113 */
Кроме того, мы должны разделить наш аргумент на три. Оба указанных действия можно осуществить посредством выражения 355 339 */
что не вызывает никаких проблем с масштабированием. Затем полученное выражение делим на квадрат тангенса (путем последовательного двойного деления на значение тангенса). Поскольку значение тангенса, хранимое в таблице, увеличено в 1000 раз, чтобы выполнить деление, нужно делимое умножить на 1000 и разделить на табличное значение тангенса:1000 ТЕТА @ */
Такое действие мы должны произвести дважды, поэтому оформим его в виде определения с именем /TAN (для деления-на-тангенс) и применим это определение дважды в определении слова КУЧА.
Наш результат пока еще будет в десять раз меньше, чем на самом деле (26711 вместо 267110 при максимальных значениях аргументов).
Нам остается лишь умножить полученное значение на величину плотности материала, максимальное значение которой равно 131 фунт на кубический фут. Во избежание переполнения уменьшаем плотность в 100 раз, применяя выражение ПЛОТНОСТЬ @ 100 */
Проверив выполнение программы в этой точке с данными о куче цемента высотой 50 футов, получим число 34991, что превышает 15 разрядов. Теперь пора принять во внимание значение 2000. Вместо ПЛОТНОСТЬ @ 100 */
мы можем написать: ПЛОТНОСТЬ @ 200 */
и наш ответ будет приведен к целому числу тонн.
Этот вариант программы вы найдете на распечатке блока 246, которая приводится ниже. Как уже упоминалось ранее, в блоке 248 находится вариант той же программы с использованием арифметических операций над данными двойной длины. Здесь вы вводите высоту в виде числа двойной точности с одним знаком после точки, представляющим десятые доли фута, например 50.0 футов, а далее следует слово ФУТЫ.
Выполняя целочисленные арифметические операции над числами двойной длины, мы в состоянии округлять полученный вес кучи до ближайшего целого фунта. В нашем случае применение целочисленной арифметики двойной длины открывает не меньшие
возможности, чем те, которые предоставляет более мощная арифметика с плавающей точкой. Ниже для сравнения приводятся результаты, полученные с помощью калькулятора, имеющего диапазон представления чисел в 10 десятичных цифр, средств Форта одинарной длины и средств Форта двойной длины. Результаты представлены для кучи цемента высотой 50 футов с использованием табличных значений: В ФУНТАХ В ТОННАХ --------------------------------------------- калькулятор 34.995.634 17,497.817 16-разрядный форт - 17.495 32-разрядный форт 34.995.634 17.497.817 ---------------------------------------------
Результаты же работы нашей программы таковы:246 LOAD ok ( компиляция варианта с одинарной длиной) ЦЕМЕНТ ok 10 ФУТОВ КУЧА = 138 тонн цемента ok 10 ФУТОВ 3 ДЮЙМОВ КУЧA = 1S1 тонн цемента ok СУХОЙ-ПЕСОК 10 ФУТОВ КУЧА = 81 тонн песка ok 248 LOAD ok ( компиляция варианта с двойной длиной) ЦЕМЕНТ ok 10.0 ФУТОВ = 279939 фунтов цемента или 139.969 тонн ok
Замечание по поводу компиляции строк. Определение слова МАТЕРИАЛ требует трех аргументов для каждого материала, одним из которых является адрес некоторой строки. Слово .МАТЕРИАЛ с помощью этого адреса выводит название рассматриваемого материала. Для помещения этой строки в словарь и передачи адреса слову МАТЕРИАЛ мы определили слово с именем ," (запятая-кавычки).
В первую очередь оно вносит в вершину стека значение HERE для слова МАТЕРИАЛ, так как именно по данному адресу будет компилироваться строка, а затем инициирует слово STRING для компиляции строкового литерала, ограниченного двойной кавычкой. В некоторых системах это слово можно определить следующим образом: : STRING ( с) WORD С@ 1 + ALLOT ;
Block # 246 0 \ Определение массы конической кучи - одинарная длина 1 VARIABLE ПЛОТНОСТЬ VARIABLE ТЕТА VARIABLE Н.М. 2 : ," ( --a) HERE ASCII " STRING ; 3 : .МАТЕРИАЛ Н.М. @ COUNT TYPE SPACE ; 4 : МАТЕРИАЛ ( 'строка плотность тета -- ) CREATE , , , 5 DOES> DUP @ ТЕТА ! 2+ DUP @ ПЛОТНОСТЬ ! 2+ @ Н.М. ! ; 6 7 : ФУТОВ ( футы -- вec-в-масштабе) 10 * ; 8 : ДЮЙМОВ ( вес-в-масштабе -- вес-в-масштабе') 9 100 12 */ 5 + 10 / + ; 10 11 : /TAN ( n - n') 1000 TETA @ */ ; 12 : КУЧА ( вес-в-масштабе -- ) 13 DUP DUP 10 */ 1000 */ 355 339 */ /TAN /TAN 14 ПЛОТНОСТЬ @ 200 */ ." = " . ." тонн " .МАТЕРИАЛ ; 15 247 LOAD
Block # 247 0 \ Таблица материалов 1 \ адрес-строки плотность тета 2 ," цемента" 131 700 МАТЕРИАЛ ЦЕМЕНТ 3 ," рыхлого гравия" 93 649 МАТЕРИАЛ РЫХЛЫЙ-ГРАВИЙ 4 ," плотного гравия" 100 700 МАТЕРИАЛ ПЛОТНЫЙ-ГРАВИЯ 5 ," сухого песка" 90 734 МАТЕРИАЛ СУХОЙ-ПЕСОК 6 ," мокрого песка" 118 900 МАТЕРИАЛ МОКРЫЙ-ПЕСОК 7 ," глины" 120 727 МАТЕРИАЛ ГЛИНА 8 9 10 11 12 ЦЕМЕНТ 13 14 15
Block # 248 0 \ Масса конической кучи - двойная длина 1 VARIABLE ПЛОТНОСТЬ VARIABLE TETA VARIABLE H.М. 2 : ," ( -- a) HERE ASCII " STRING ; 3 : .МАТЕРИАЛ Н.М. @ COUNT TYPE SPACE ; 4 : DU.3 ( du -- ) <# # # # ASCII .HOLD #S #> TYPE SPACE ; 5 : МАТЕРИАЛ ( 'строка плотность тета -- ) CREATE 6 DOES> DUP @ TETA ! 2+ DUP @ ПЛОТНОСТЬ ! 2+ @ Н.М. ! ; 7 : КУБ ( d -- d') 2DUP OVER 10 M*/ DROP 10 M*/ 8 : /TAN ( d -- d') 1000 TETA @ М*/ ; 9 : ФУТОВ ( d -- ) КУБ 355 339 M*/ ПЛОТНОСТЬ @ 1 М*/ 10 /TAN /TAN 5 M+ 1 I0 M*/ 11 2DUP ." = " D. ." фунтов " .МАТЕРИАЛ 12 1 2 M*/ ." или " DU.3 ." тонн " ; 13 247 LOAD 14 15
БЛОЧНЫЕ БУФЕРЫ
Форт-система построена таким образом, чтобы вы не задумывались о том, как организованы блочные буферы. Однако ничего сложного в этом нет, так что вы всегда сможете в них разобраться, применить и (при необходимости) исправить их. Поэтому мы опишем здесь механизм работы блочных буферов.
Как уже упоминалось ранее, каждый буфер имеет достаточные размеры для размещения содержимого одного блока (1024 байта) в памяти с произвольной выборкой (ОЗУ), поэтому он может редактироваться и загружаться или к нему просто может быть осуществлен доступ любыми иными средствами. Мы думаем, что непосредственно взаимодействуем с диском, хотя на самом деле система перекачивает данные с диска в буфер, откуда их можно считывать. Можно также записать данные в буфер с тем, чтобы система переслала их дальше, на диск.
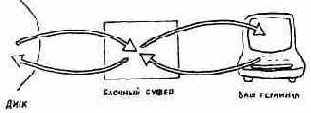
Здесь мы имеем дело с так называемой виртуальной памятью, т.е. работаем с памятью большой емкости, как с памятью компьютера.
Во многих Форт-системах (даже если они являются мультипрограммными) используются всего лишь два блочных буфера. Давайте выясним, почему это возможно.
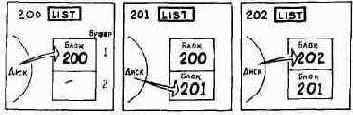
Допустим, в вашей системе имеются два буфера и вы выполняете следующие действия. Сначала вы распечатываете блок 200. Система считывает его с диска и пересылает в буфер 0, откуда слово LIST выводит этот блок на печать. Далее вы распечатываете блок 201. Система копирует блок 201 с диска в другой буфер. И наконец, вы распечатываете блок 202. Система копирует данный блок с диска в буфер, который применялся в первую очередь, а именно в буфер 0.
Что случилось с бывшим содержимым буфера 0? Оно просто было замещено (затерто) новым содержимым. Старая информация для нас не потеряна, так как блок 200 все еще остается на диске. Но если бы вы отредактировали блок 200, были бы утеряны ваши исправления? Нет, конечно. При распечатке блока 202 сначала измененное содержимое блока 200 посылается на диск с тем, чтобы обновить прежнее содержимое этого блока, а затем в буфер помещается содержимое блока 202.
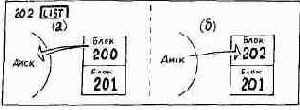
Волшебное слово UPDATE устанавливает (обновляет) флаг, связанный с каждым буфером.
Этот флаг указывает, что содержимое текущего блока (к которому осуществлялся самый последний доступ) после прочтения с диска подвергалось изменениям. Все команды редактора, изменяющие содержимое блоков, - будь то занесение или удаление - имеют слово UPDATE в своих определениях. Если в некоторый буфер требуется поместить содержимое другого блока и флаг обновления данного буфера установлен, прежнее содержимое не исчезает, а копируется снова на диск.
Основным словом, которое считывает содержимое какого-либо блока с диска, является BLOCK. Например, если вы введете205 BLOCK
то система скопирует блок 205 в один из буферов. Кроме того, BLOCK оставляет в вершине стека адрес начала этого буфера. Используя адрес начала буфера как базу, вы можете получить доступ к любому байту блока1. Слово BLOCK получает управление всякий раз, когда вы распечатываете содержимое блока посредством LIST или загружаете его с помощью LOAD.
Рассмотрим выполнение слова BLOCK более подробно. В первую очередь BLOCK проверяет, не находится ли уже содержимое нужного блока в некотором буфере, и если оно там находится, то помещает в вершину стека адрес данного буфера, а если нет - выбирает буфер (в большинстве систем буфер с самым давним доступом). В том случае, когда буфер подвергался изменениям, система копирует его содержимое на диск, а затем копирует содержимое нужного блока в этот буфер.
Такая организация позволяет многократно модифицировать содержимое блока, не обращаясь всякий раз к дисководу. Поскольку обращение к диску занимает больше времени, чем к памяти с произвольной выборкой, при этом экономится масса времени.
С другой стороны, когда в одной системе работают несколько пользователей, подобная организация дает им возможность обходиться всего лишь двумя буферами (2К памяти) даже в том случае, если каждый из них осуществляет доступ к различным блокам.
Многие Форт-системы предоставляют своим пользователям право задавать число блочных буферов, обеспечивая им тем самым возможность выбора между размером доступной оперативной памяти и частотой обращения к дискам.
Слово FLUSH (ВЫБРОС) инициирует немедленную запись всех обновленных буферов на диск. (Так как вы теперь имеете представление о буферах, можно объяснить, для чего нужно слово FLUSH: обновление буфера не означает записи его содержимого на диск.) Помимо прочего после употребления слова FLUSH система «забывает», что в буферах хранилось содержимое блоков (она освобождает все буферы). Если вам понадобится распечатать или загрузить один из таких блоков, то придется считать его содержимое посредством BLOCK с диска снова.
1 Для пользователей некоторых систем фиг-Форта. Блоки, занимающие 1024 байта, могут быть считаны в нескольких несмежных буферов, что затрудняет индексирование блоков (см. листинги системы фиг-Форта).
Определенное Стандартом-83 слово SAVE-BUFFERS (СОХРАНИТЬ-БУФЕРЫ) по своим возможностям беднее слова FLUSH: оно сохраняет на диске содержимое обновленных буферов, но не освобождает их. Если вам снова потребовался некоторый блок, то его содержимое уже находится в одном из буферов, и Форт-система в этом случае не обращается к диску.
Как правило, вам нет необходимости пользоваться приведенными выше словами, поскольку слово BLOCK гарантирует, что перед повторным применением буферов их содержимое будет сохранено на диске. Однако во время отладки новой программы вам эти слова могут пригодиться (прежде чем система выйдет из строя, исправления все же должны попасть на диск). SAVE-BUFFERS переписывает хранящиеся в буферах блоки на диск, но с содержимым буферов можно работать и в дальнейшем. Это сокращает число обращений к диску (что экономит время и позволяет избежать многих неприятностей). Слово FLUSH необходимо при смене дисков, так как оно эффективно освобождает буферы от их прежнего содержимого, или в тех случаях, когда вы хотите убедиться в том, что информация действительно была записана на диск.
К сожалению, перечисленные слова и их функции изменяются от диалекта к диалекту до неузнаваемости. Ниже приводятся описания этих слов для различных систем.
| Фиг-Форт | FLUSH Копирование всех обновленных буферов во внешнюю память и их освобождение | SAVE-BUFFERS (Не определено) |
| Стандарт-79 | (Не определено: переименованное слово SAVE-BUFFERS) | Копирование всех обновленных буферов во внешнюю память и их освобождение |
| Стандарт-83 | Копирование всех обновленных буферов и их освобождение | Копирование всех обновленных буферов во внешнюю память, сброс флагов обновления этих буферов без их освобождения |
1 Для начинающих. Испорченные, бессмысленные или не имеющие отношения к обработке, ради которой были введены, данные программисты называют «мусором».
пример, удалили несколько нужных строк, а их текст забыт или просто что-нибудь напутали) и не хотите, чтобы оно попало на диск. Когда вы после выполнения этого слова снова читаете свой блок, система не выясняет, есть ли содержимое вашего блока в памяти, а просто считывает его с диска1.
Согласно Стандарту-83 слово FLUSH можно определить следующим образом:
: FLUSH SAVE-BUFFERS EMPTY-BUFFERS ;
Слово BUFFER заносит информацию на диск без учета прежнего содержимого диска (например, при инициализации диска, записи потока информации, копировании ленты на диск и т. д.). BUFFER используется словом BLOCK для назначения номера блока следующему доступному буферу. Само слово BUFFER содержимое с диска в буфер не считывает (хотя в некоторых системах считывает). К тому же оно не проверяет, был ли номер блока присвоен какому-либо буферу, и может случиться так, что один и тот же номер будут иметь два буфера. Такую ситуацию вы обязаны контролировать сами.
|
UPDATE |
( -- ) |
Блок, доступ к которому осуществлялся в последнюю очередь, отмечается как модифицируемый. Этот блок будет впоследствии переписан во внешнюю память, если его буфер потребуется для размещения другого блока или в результате выполнения слова FLUSH. |
|
SAVE-BUFFERS |
( -- ) |
Запись содержимого всех обновленных буферов в соответствующие блоки внешней памяти. У всех буферов погашается признак обновления, но они продолжают оставаться распределенными . |
|
FLUSH |
( -- ) |
Осуществляется SAVE-BUFFERS, затем происходит погашение признака обновления всех буферов. Используется при установке или смене накопителей внешней памяти. |
|
EMPTY-BUFFERS |
( -- ) |
Все блочные буфера отмечаются как пустые независимо от им содержания. Обновленные блоки во внешнюю память не записываются. |
|
BLOCK |
( u -- ) |
Занесение в стек адреса первого байта в блоке u. Если данного блока еще в памяти нет, то происходит его пересылка из внешней памяти в тот буфер, к которому дольше всех не было доступа. Если блок, занимающий данный буфер, обновлялся (то есть был модифицирован) , то перед считыванием блока u в буфер содержимое последнего будет переписано во внешнюю память. |
|
BUFFER |
( u -- a) |
Функции те же, что и у BLOCK, за исключением того, что сам блок из внешней памяти не считывается. |
БОЛЕЕ ПОДРОБНО О ПЕРЕМЕННЫХ
Создавая некоторую переменную, например ДАТА, с помощью выражения VARIABLE ДАТА, вы фактически компилируете новое слово с именем ДАТА в словарь. Упрощенно это выглядит так2:

1 Для специалистов. Трехбуквенный код, например, имя терминала некоего аэропорта, можно запомнить как число одинарной длины без знака в системе счисления с основанием 36. Например:
: АЛЬФА 36 BASE ! ; АЛЬФА ok
ZAP U. ZAP ok
2 Для специалистов. Как на самом деле выглядит в памяти элемент словаря, мы покажем в следующей главе.
Слово ДАТА аналогично любому другому слову в вашем словаре, за исключением того, что оно определено с помощью слова VARIABLE, а не :, поэтому вы не должны специфицировать функции своего определения. Само имя слова VARIABLE предопределяет, что должно произойти. А происходит следующее.
Когда вы вводите 12 ДАТА !
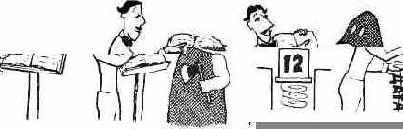
число 12 поступает в стек, после чего интерпретатор текста ищет слово ДАТА в словаре и, найдя его, передает на исполнение EXECUTE.
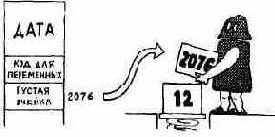
EXECUTE выполняет переменную путем копирования адреса «пустой» ячейки этой переменной (куда будет послано значение) в стек':

1 Для начинающих. В программировании адресом называется число, которое определяет участок машинной памяти. Например, по адресу 2076 (адреса, как правило, выражаются шестнадцатиричными числами без знака) может содержаться 16-разрядное представление значения 12. Здесь 2076 — адрес, 12 — содержимое.
Слово ! выбирает адрес (из вершины) и значение (под ним) и запоминает это значение по выбранному адресу. Новое число замещает любое другое число, находившееся прежде по данному адресу.
(Чтобы запомнить порядок аргументов, можно провести такую аналогию: думайте о том, что сначала нужно положить посылку, а уже потом сверху приклеить адресную бирку.)
Для слов @ требуется только один аргумент: адрес, который в данном случае обеспечивается именем переменной, например ДАТА @.

Используя выбранное из стека значение в качестве адреса, слово (3) помещает содержимое, находящееся по данному адресу, в стек, предварительно сняв с последнего адрес. (Содержимое участка памяти остается прежним.)
БОЛЕЕ ПОДРОБНО ОБ ОПЕРАТОРЕ IF
В результате выполнения операции сравнения флаг1 на самом деле вверх не выбрасывается, как это показано на рисунках, а его значение заносится в стек, подобно любому другому аргументу. Истина представляется -1 (отрицательной единицей), а ложь - 0 (нулем)2. Слово IF берет флаг из стека и использует его.
Попытайтесь ввести следующую фазу с терминала и пусть слово . выведет значение; представляющее флаг: 12 12 = . -1 ok Да, 12 равно 12 11 12 = . 0 ok Нет, 11 не равно 12
Можно вводить знаки операций сравнения непосредственно с вашего терминала, как в приведенном выше примере, но помните, что оператор IF ... THEN должен целиком находиться в пределах одного определения, поскольку его выполнение сопряжено с ветвлением программы. Слово IF будет воспринимать -1 как значение флага «истина», а 0 — как «ложь». Перед IF может стоять еще одно слово NOT3, которое меняет значение флага в стеке на противоположное: О NOT .-1 ok -1 NOT . 0 ok
Слово NOT позволяет изменить условие IF на обратное. Таким образом, мы можем записать : ?ДВЕНАДЦАТЬ ( n -- ) 12 = NOT IF . " Не двенадцать. " THEN ;
1 Для начинающих. На компьютерном жаргоне значение, которое один фрагмент программы оставляет другому в качестве сигнала, называется флагом.
2 Для пользователей систем, созданных до введения Стандарта-83. В более ранних системах истина представлялась как 1.
3
Для систем фаг-Форт. Используйте в этих целях 0 = .
и если параметр n не будет равен 12, на печать будет выводиться фраза «Не двенадцать».
Использование стека в Форт-системе для передачи значений флага — одно из наиболее удачных решений, привлекательных прежде всего своей простотой. Вы можете, например, передать флаг в качестве аргумента другому слову (если нужно, то за пределы определения):: .ДА? ( ? — ) IF ." Да " THEN ; 12 12 = .ДА? Да ok
(Знак вопроса в стековом комментарии означает флаг.) Можете ли вы назвать еще такой язык, который дает возможность записывать условие в одной процедуре, а оператор IF — в другой?
БУФЕР ПОИСКА И БУФЕР ВСТАВОК
Для того чтобы использовать редактор эффективно, вы должны разобраться в том, как работают его буферы поиска и вставок. Вы можете и не знать, что когда вы набираете на клавиатуре F KOМПЬЮTEP<return>
то по команде F фрагмент КОМПЬЮТЕР прежде всего помещается в так называемый буфер поиска. С точки зрения компьютерной терминологий буфер — это участок памяти для временного размещения данных. Буфер поиска находится в оперативной памяти компьютера (ОЗУ).
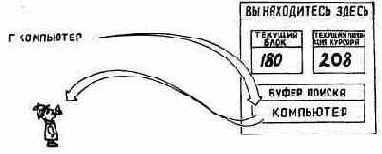
Команда F инициирует поиск такого фрагмента в строке, который соответствует содержимому буфера поиска.
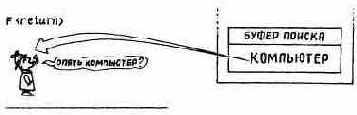
Теперь вам понятно, что происходит, когда вы используете команду F следующим образом: F<return>
т. е. в том случае, когда за F непосредственно следует символ возврата каретки. В строке осуществляется поиск такого фрагмента, который уже находится в буфере поиска как результат последнего выполнения команды F
Это позволяет находить многочисленные «вхождения» одного и того же фрагмента текста без его повторного набора. Например, предположим, что в строке 8 содержится следующее утверждение:

Курсор указывает начало строки, и вы хотите удалить последний союз И. Введите следующую фразу:

Теперь фрагмент И находится в буфере поиска и вы можете просто несколько раз подряд набрать команду F: F<return> F<return>
и т. д. до тех пор, пока не доберетесь до того вхождения И, которое вам нужно и вы можете его удалить с помощью команды Е. (По команде Е подсчитывается число символов, находящихся в буфере поисками удаляется такое же число символов, предшествующих курсору.) Между прочим если вы попытались ввести команду F еще раз, то вы бы получили следующий ответ: F И none
что означает: «В данной строке вхождений И нет». Иными, словами, команда F не нашла в строке фрагмента, соответствующего содержимому буфера поиска и поэтому возвратила вам слово И с сообщением об ошибке NONE.
Как уже отмечалось выше, команда D сочетает в себе две команды F и Е, поэтому она также использует буфер поиска.
Поместив курсор в начало строки

и фрагмент И в буфер поиска, вы можете удалить все вхождения И, введя несколько раз команду D:

Буфер вставок используется командой I. Для того чтобы вставить содержимое этого буфера в то место, куда указывает курсор, достаточно просто набрать на клавиатуре I<return>
Рассмотрим пример, в котором показано, как можно одновременно применять буфер поиска и буфер вставок. Предположим, в какой-то строке содержится следующая информация: Я ЖИВУ, Я ЛЮБЛЮ, Я СТРАДАЮ
Теперь подведем курсор

и осуществим вставку

1 Для любознательных. Редактору достаточно хранить только позицию курсора, а не указатель текущей строки. Так как в строке помещается 64 символа, редактор с помощью слова /MOD всегда сможет вычислить положение курсора, скажем, для 16-го символа в строке 3:
208 64 /MOD . . 3 16 ok
В результате получим
Наберите на клавиатуре

Часть 2 ДЛЯ ВСЕХ ДВОИЧНАЯ ЛОГИКА
Слова AND и OR (введенные в гл. 4) используют «двоичную логику», т. е. каждый бит проверяется независимо, и перенос единицы в старший разряд не производится. Выполним, например, операцию AND над следующими двумя двоичными числами: 0000000011111111 0110010110100010 AND ---------------- 0000000010100010
Для того чтобы результирующий бит был равен единице, соответствующие биты-аргументы должны быть оба равными единице. Заметьте, что в этом примере первый аргумент содержит все нули в старшем байте и все единицы в младшем. Действие второго операнда здесь заключается в том, что младшие восемь битов сохраняются неизменными, а старшие восемь битов сбрасываются в нуль. Первый операнд служит «маской» для маскирования старшего байта второго операнда.
Слово OR также применяет двоичную логику. В примере1000100100001001 0000001111001000 OR ---------------- 1000101111001001
единицу получается в тех битах, где хотя бы один операнд был равен единице. И снова каждый столбец проверяется независимо, без переноса единицы в старший разряд. При умелом использовании масок в одном 16-разрядном значении можно хранить 16 отдельных флагов. Так, мы можем узнать, чему равен соответствующий (скажем, пятый) бит: 1011101010011100 нулю или единице, путем маскирования остальных флагов: 1011101010011100
0000000000010000 AND ---------------- 0000000000010000
Так как значение нашего бита равно единице, результат будет истинным. Если бы значение бита составляло нуль, то результат
оказался бы ложным. Мы можем сбросить определенный флаг в нуль, не трогая остальные, следующим приемом: 1011101010011100 1111111111101111 AND
---------------- 1011101010001100 ^
Мы работали с маской, во всех битах которой, за исключением сбрасываемого в нуль, содержатся единицы. Можно установить тот же самый флаг, т. е. сделать его единицей, таким образом: 1011101010001100
0000000000010000 OR ---------------- 1011101010011100 ^
Ниже приводятся несколько приемов использования операции AND.
Вы могли заметить, что значение строчной буквы в коде ASCII отличается от значения прописной в точности на 32 (в десятичной системе счисления). Мы можем создать определение, которое осуществляло бы перевод строчного символа в прописной:: ПРОПИСНОЙ ( строчный-символ -- прописной-символ ) 32 - ;
Итак, 97 EMIT a ok
97 ПРОПИСНОЙ EMIT A ok
К сожалению, данный вариант слова ПРОПИСНОЙ не будет действовать в том случае, если переводимый символ уже является прописным, поскольку весь процесс перевода сводится к простому вычитанию.
Но код ASCII разработан очень мудро. Число 32 выбрано не случайно, а с учетом его представления в двоичной системе счисления. Посмотрите, как выглядят представления прописной и строчной букв А: A 1000001 a 1100001
Они отличаются только одним битом, который и представляет число 32. Если мы сбросим этот бит в 0, то независимо от того, была ли буква прописной или строчной, она станет прописной: : ПРОПИСНОЙ ( строчный-символ -- прописной-символ ) 95 AND ;
Число 95 является десятичным эквивалентом двоичного числа 1011111
и совпадает с маской для двоичного представления числа 32. Следовательно, 97 ПРОПИСНОЙ EMIT A ok
65 ПРОПИСНОЙ EMIT A ok
(Однако поведение рассматриваемого варианта слова ПРОПИСНОЙ оказывается несколько странным по отношению к небуквенным символам. Попытайтесь, к примеру, перевести цифры.)
Слово XOR также предназначено для работы с битами. Как отмечалось в гл. 4, при выполнении этой операции истина получается только тогда, когда один из аргументов (но не оба сразу) истинен. Сравним результат выполнения операций XOR и OR:1000100100001001 1000100100001001
0000001111001000 OR 0000001111001000 XOR ---------------- ---------------- 1000101111001001 1000101011000001
Если вы применяете операцию XOR с аргументом, все биты которого равны единице, то тем самым инвертируете биты второго аргумента. 1111111111111111 1000100100001001 XOR ---------------- 0111011011110110
Таким образом, выражение -1 XOR
является двоичной маской или шаблоном инвертирования. (Существует математический термин дополнение числа до единицы.)
Стандарт-83 и операция NOT Стандарт 83 изменил первоначальный смысл операции NOT В системах, разработанных до принятия этого Стандарта, слово NOT заменяло значение логического аргумента оператора IF противоположным, т е не нуль (истина) становился нулем (ложью) Оно было синонимом слова О.= , созданным для улучшения читабельности программы. В Стандарте-83 слово NOT эквивалентно выражению "-1 XOR" и не сработает в том случае, если значение исходного флага «истина» не представлено как -1.
Обязательно убедитесь в том, что инвертируемое значение является логическим, а не арифметическим. Выражение "0= NOT" вырабатывает из ненулевого значения правильное логическое значение «истина».
ЧЕМ ОТЛИЧАЮТСЯ ЧИСЛА СО ЗНАКОМ И БЕЗ ЗНАКА
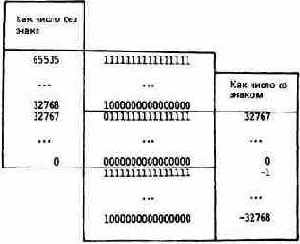
Все цифровые компьютеры хранят числа в двоичной форме1. Элемент стека Форт-системы состоит из 16 разрядов2, или битов (бит - двоичная цифра). Ниже показана структура из 16 битов, где приводятся значения всех битов:

Если в каждом бите хранится единица, то это число составит 65535. Таким образом, 16 битами можно представить любое значение от 0 до 65535. Поскольку такой способ представления не позволяет нам изображать отрицательные числа, мы называем их числами без знака. В наших таблицах и стековой нотации числа без знака обозначаются буквой и.
1 Для тех, кто не знаком с двоичной системой счисления. Попросите кого-нибудь из ваших друзей (увлекающегося математикой) рассказать вам об этой системе или поищите учебное пособие по ЭВМ для начинающих.
2 Для пользователей 32-разрядных компьютеров. В таких процессорах, как 68000, стек Форта обычно 32-разрядный. Поэтому термин, число одинарной длины в данном случае означает 32-разрядное число.
Но как же быть с отрицательными числами? Чтобы иметь возможность изображать как положительные, так и отрицательные числа, необходимо пожертвовать одним битом, задействовав его под знак. Для этой цели мы отведем самый левый «старший по порядку» бит. 15 оставшихся бит позволят нам представить любое число вплоть до 32767. Если знаковый бит содержит единицу, то нужно отложить изображаемое значение по оси влево от нуля, т. е. в области отрицательных чисел. Таким образом, с помощью 16 бит можно представить число в диапазоне от -32768 до +32767. Вы уже знаете, что этот диапазон составляют числа одинарной длины, обозначаемые буквой п.
Мы столь подробно останавливаемся на представлении отрицательных чисел, чтобы у вас была полная ясность по всем излагаемым здесь вопросам. У вас может сложиться впечатление, что достаточно просто ввести знаковый разряд, и вы сможете различить отрицательное и положительное числа, однако на самом деле это далеко не так.
Чтобы понять, как представляются отрицательные числа, вернемся снова к десятичной системе счисления и понаблюдаем за показаниями счетчика, устанавливаемого на магнитофонах многих типов.
Допустим, что счетчик высвечивает три цифры (трехзначное число). По мере перемотки ленты это число увеличивается. Установим счетчик на нуль и начнем перематывать ленту в обратном направлении. Первое число, которое вы увидите на индикаторе, будет 999. Его мы воспринимаем как - 1. Следующим числом окажется 998, что соответствует -2, и т. д.
Аналогично представляются числа со знаком и в компьютере. Если мы начнем с нуля:
0000000000000000
и вернемся назад на одно число, то будем иметь
1111111111111111 (16 единиц)
что означает 65535 при изображении чисел без знака и -1 при изображении чисел со знаком. Число 1111111111111110
соответствует 65534 при изображении чисел без знака и -2 при изображении чисел со знаком.
(Традиционно числа -1 и 0 применяются в качестве значений «истина» и «ложь» потому, что в представлении -1 все биты установлены, а в представлении 0 - сброшены.)
Ниже приводится схема, в которой показано, каким образом двоичное число в стеке может использоваться как число без знака или как число со знаком.
Такой странный на первый взгляд способ представления отрицательных чисел дает возможность компьютеру использовать одни и те же процедуры для выполнения как вычитания, так и сложения.
Продемонстрируем изложенное на примере простой задачи: 2 - 1 ---
Эта задача эквивалентна задаче сложения 2+ (-1). При двоичном представлении чисел одинарной длины двойка выглядит следующим образом:
0000000000000010
а отрицательная единица - так:
1111111111111111
Компьютер складывает их таким же образом, как мы это делаем на бумаге. Если сумма в какой-то колонке превышает единицу, то в следующую колонку (старший двоичный разряд) переносится 1. В результате получается: 0000000000000010 + 1111111111111111 ----------------- 1000000000000001
Как видите, компьютеру потребовалось выполнить перенос единицы в старший разряд во всех колонках, а последняя единица была вынесена в 17-й разряд. Но так как элемент стека состоит только из 16 битов, будет выведено число 0000000000000001 т.е. единица, что является правильным ответом.
Мы не объясняем здесь, каким образом компьютер переводит положительное число в отрицательное. При желании вы можете найти описание этого процесса, который называется «дополнением до двух», в литературе.
ЧИСЛА ДВОЙНОЙ ДЛИНЫ
Вы, вероятно, уже знаете, что такое число двойной длины. Это число, представление которого занимает 32 бита вместо 16. Двойная длина допускает представление чисел в диапазоне ±2 147 483 647 (т. е. свыше четырех биллионов).
В Форте число двойной длины занимает1 в стеке место двух чисел одинарной длины. Такие операции, как 2SWAP и 2DUP, применимы и для чисел двойной длины, и для пары чисел одинарной длины.
Обращаем ваше внимание на то, что в программировании термином «слово» принято обозначать 16-разрядное число, или два байта. В Форте же под словом понимают некоторым образом определенную команду. Поэтому, чтобы избежать коллизий, программирующие на Форте 16-разрядное значение называют ячейкой. Число двойной длины требует для своего представления двух ячеек.
Числа двойной длины составляют диапазон ±2147483647. Большинство Форт-систем до некоторой степени поддерживают работу с числами двойной длины. Для того чтобы вводимое вами (с клавиатуры или из блока) число воспринималось в стеке как число двойной длины, проще всего включить в состав этого числа десятичную точку. Например, когда вы вводите: 200000.<return>

NUMBER воспринимает запятую как признак того, что данное значение должно быть представлено числом двойной длины и помещает это значение в стек в виде двух последовательных ячеек (ячейкой в Форте называется структура из 16 битов), причем старшая по порядку ячейка помещается над младшей1.
Слово D. выводит число двойной длины без всяких знаков пунктуации: D. ( d - ) Печать числа двойной длины со знаком.
Здесь d - целое число двойной длины со знаком. Например, если вы введете число двойной длины, а затем выполните операцию D., то компьютер вам ответит: D. 200000 ok
В некоторых Форт-системах для выделения дробной части применяются еще четыре знака пунктуации: , / - :
В таких системах все перечисленные ниже числа переводятся в одно и то же представление:12345. D. 12345 ok 123.45 D. 12345 ok 1-2345 D. 12345 ok 1/23/45 D. 12345 ok 1:23:45 D. 12345 ok
1 Для специалистов. В большинстве Форт-систем положение десятичной точки запоминается в некоторой переменной, и вы можете это использовать в своих целях. Более подробную информацию вы найдете в документации по вашей системе. Мы продолжим обсуждение данного вопроса в гл. 10 (см. «Преобразование чисел при вводе»).
Кроме того, в некоторых системах, где применяются арифметические сопроцессоры, на расширенное представление целого числа указывает не десятичная точка, а символ X, например:
123456789X
а число -12345 - нет, потому что оно будет представлено как отрицательное число одинарной длины. (Это единственный случай, когда дефис интерпретируется как минус, а не как знак пунктуации.)
Далее мы покажем, как вы можете определить свой собственный эквивалент операции D., чтобы выводить вместе с числом любой знак пунктуации.
ЧИСЛА СО ЗНАКОМ И БЕЗ ЗНАКА
В первой главе мы ввели слово NUMBER (ЧИСЛО).

Если слово INTERPRET (ИНТЕРПРЕТАТОР) не может найти введенную строку символов в словаре, то оно передает ее слову NUMBER, после чего NUMBER пытается прочесть всю совокупность символов как двоичное число. Когда NUMBER это удается, прочитанное число помещается в двоичной форме в стек NUMBER не проверяет числа на принадлежность их какому-либо диапазону1, поэтому может представлять вводимые числа либо как числа со знаком, либо как числа без знака. Например, при вводе любого числа в диапазоне от 32768 до 65535 NUMBER представит его в виде числа без знака, а любого значения в диапазоне от -32768 до -1 - как целое в двоичном дополнительном коде. Это важный момент: стек может быть использован для хранения целых чисел со знаком или целых чисел без знака. Будет ли некоторое двоичное значение интерпретироваться как целое со знаком или как целое без знака, зависит от выполняемых над ним операций. Вы выбираете то, что вам больше подходит в данной ситуации, а затем твердо придерживаетесь выбранного варианта.
1 Для начинающих. NUMBER не проверяет, выходит ли введенное вами в качестве числа одинарной длины значение за рамки соответствующего диапазона. Если вы ввели слишком большое число, то NUMBER преобразует его, но сохранит только 16 последних значащих цифр.
Ранее мы ввели слово ., которое выводит на печать из стека значение в виде целого со знаком:
65535 .-1 ok
Слово U. печатает то же самое двоичное представление как число без знака:
6S535 U. 65535 ok
U. ( u -- ) Вывод числа одинарной длины без знака с одним пробелом после него.
Напоминаем, что буквой n обозначаются числа одинарной длины со знаком, а буквой u - числа одинарной длины без знака.
Ниже приводятся еще два слова, использующие числа без знака:U.R ( u ширина -- ) Вывод числа без знака. Число выровнено по правой границе поля заданной ширины.
U< ( u1 u2 -- ? ) Помещение на стек истины в том случае, если u1<u2. Оба аргумента рассматриваются как числа одинарной длины без знака.
ЧТО ТАКОЕ КОМПИЛИРУЮЩЕЕ СЛОВО?
Если обычные слова Форта появляются внутри определения через двоеточие, то они компилируются в словарь. Эти слова во время компиляции ведут себя пассивно. Компилирующие слова также появляются внутри определения через двоеточие, но в противоположность первым активно влияют на процесс компиляции. Такие слова, как IF, THEN, BEGIN, REPEAT и ." являются компилирующими.
Создатели Форта проявили последовательность и в данном случае. Коль уж существует тенденция не включать в язык все возможные определяющие слова, то компилирующих операторов в самом языке немного. Возможность управлять компиляцией путем образования собственных компилирующих слов предоставляет вам такую свободу, какую не может обеспечить ни один из известных языков программирования. Это средство позволяет локализовать информацию внутри соответствующих определений (не рассредоточивая ее по всей программе), что упрощает написание программы, облегчает ее чтение, восприятие и сопровождение. Вероятно, ваша программа будет выглядеть более привлекательной, если в язык включить оператор выбора вариантов, который сравнивает текстовые фрагменты. А, может быть, вы хотели бы добавить к вашим операторам управления средства жесткого аварийного контроля? Не исключено, что вам захочется иметь оператор цикла DO, использующий 32-разрядный индекс. Все это в ваших силах.
По мере дальнейшего изложения материала мы будем приводить примеры применения компилирующих слов. Некоторые из них уже есть в вашей системе. Даже если у вас нет намерения создавать свои компилирующие слова, поняв механизм их создания, вы разберетесь и в том, как образуются собственные компилирующие слова Форта. Форт-система написана на Форте, так что все, что может делать она, можете делать и вы!
Прежде чем перейти к примерам, рассмотрим механизм создания компилирующих слов. Как уже отмечалось, компилирующие слова, когда до них доходит очередь компилятора внутри определения через двоеточие, не компилируются, а выполняются. Это ключ к механизму создания компилирующих слов.
Чтобы понять, как он действует, изучим компилятор двоеточия.
Компилятор двоеточия функционирует аналогично текстовому интерпретатору. Он выбирает из входного потока слова и пытается отыскать их в словаре. Однако, вместо того чтобы (как ИНТЕРПРЕТАТОР) исполнять эти слова немедленно, он, как правило, компилирует их адреса в словарь. Но компилятор распознает компилирующие слова и только их исполняет сразу, подобно текстовому интерпретатору.
Каким образом компилятор двоеточия отличает компилирующие слова? По биту немедленного исполнения данного определения (гл. 9 «Структура словарной статьи»): если бит сброшен, то компилируется адрес слова, если установлен, что слово немедленно исполняется. Такие слова называются словами немедленного исполнения (immediate).
Слово IMMEDIATE делает слово немедленно исполняемым. Его формат: : имя определение ; IMMEDIATE
т. е. это слово выполняется сразу после компиляции определения. Допустим, у нас есть определение: : ТЕСТ ; IMMEDIATE
Это слово немедленного исполнения которое ничего не выполняет. Если мы обратимся к нему из определения другого слова, например: : 2CRS CR ТЕСТ CR ;
то будет скомпилирован следующий фрагмент словаря:

Как видите, определение скомпилировано без слова ТЕСТ. На самом деле оно выполнено во время компиляции слова 2CRS. Поскольку слово ТЕСТ ничего не выполняет, оно бесполезно. Приведем другой пример. Предположим, что у нас есть слово с именем ТЮЛЬПАН и определение: : ТЕСТ COMPILE ТЮЛЬПАН ; IMMEDIATE
Теперь переопределим слово 2CRS точно так же, как и ранее: : 2CRS CR ТЕСТ CR ;
и получим следующий результат:

На сей раз слово ТЕСТ во время компиляции определения 2CRS скомпилировало адрес слова ТЮЛЬПАН. На самом деле мы нашим определением как бы сказали: : 2CRS CR ТЮЛЬПАН CR ;
и что компилировать, а что нет, определяет ТЕСТ, потому что это слово немедленного исполнения. Обратите внимание на слово COMPILE (КОМПИЛЯЦИЯ). Мы ввели его как бы между прочим, поскольку его функции проще понять в контексте.

: ТЕСТ COMPILE ТЮЛЬПАН ; IMMEDIATE
COMPILE вычисляет адрес следующего слова определения и запоминает его в виде числа:

: 2CRS CR ТЕСТ CR ;
Когда исполняется слово немедленного выполнения, в котором появилось COMPILE, оно компилирует запомненный адрес в создаваемое определение. Этот процесс можно трактовать как отсроченную компиляцию. Приведем теперь очень полезный пример. Допустим, вы написали отладочное средство с именем ОТЛАДКА, которое хотите использовать в любом месте своей программы. Так как желательно иметь возможность при необходимости включать и отключать это средство, воспользуемся словом ТЕСТ, определенным следующим образом: : ТЕСТ ПРОВЕРКА? IF ОТЛАДКА THEN ;
Слово ТЕСТ при выполнении проверяет флаг и определяет, обращаться к слову ОТЛАДКА или нет. Казалось бы, все хорошо, однако много времени уходит на остановку для проверки флага на каждом шаге цикла. Если вы не работаете в отладочном режиме, вам вряд ли нужно всякий раз проверять режим. Проблема решается путем переопределения слова ТЕСТ: : ТЕСТ ПРОВЕРКА? IF COMPILE ОТЛАДКА THEN ; IMMEDIATE
В такой ситуации для включения отладочного средства придется перекомпилировать программу, но это займет немного времени. В отладочном режиме слово ТЕСТ скомпилирует ОТЛАДКА в соответствующие места программы. В противном случае оно вообще ничего компилировать не будет. Проверка IF будет осуществляться в период компиляции. Рассмотрим более сложное, но уже знакомое вам компилирующее слово .", которое не выводит строку на экран, как вы, возможно, склонны думать. На самом деле это слово компилирует строку в словарь с тем, чтобы выдать ее позднее. А какое слово нашу строку затем выводит? Примитив, названный в одних системах (."), в других - dot". Проследим шаг за шагом выполнение данного слова точно так же, как мы это делали применительно к определяющим словам. Приведенное ниже определение слова .", имеется в большинстве Форт-систем, но нам интересен принцип, а не детали.

: dot" R> COUNT 2DUP + >R TYPE ; : ." COMPILE dot" ASCII " STRING ; IMMEDIATE
Определение dot" и ."

: ВСТРЕЧА ." Эй, ты " ;
Исполнение .", которое является словом немедленного выполнения (и поэтому исполняется во время компиляции слова ВСТРЕЧА). Оно в свою очередь осуществляет компиляцию:
адреса слова dot" в определение слова ВСТРЕЧА:

строки, ограниченной двойной кавычкой как строки со счетчиком:


ВСТРЕЧА
Выполнение слова ВСТРЕЧА, которое вызывает слово dot", а оно уже выводит строку на экран1.
Следующие два слова применяются при создании новых компилирующих слов:
IMMEDIATE | ( - ) | Последнее определенное слово становится немедленно исполняемым, то есть во время компиляции оно будет не компилироваться, а выполняться. |
C0MPILE xxx | ( - ) | Применяется при определении компилируйте-то слова. Когда это компилируйте* слово будет в свою очередь использоваться в исходном определении, адрес поля кода ххх будет скомпилирован в словарную статью, так что когда вновь созданное определение выполняется, выполняется и ххх. |
ЧТО ТАКОЕ МАШИННЫЙ ЯЗЫК? (ВВЕДЕНИЕ ДЛЯ НАЧИНАЮЩИХ)
Новичок, впервые столкнувшийся с термином «машинный язык», может подумать: «На каком же таком языке разговаривает компьютер? Наверное, человеку чрезвычайно трудно его понять. Выглядит этот язык, вероятно, как-нибудь так:
976#!@NX714&+
если он вообще как-то выглядит». На самом деле машинный язык не должен быть трудным для понимания. Его назначение — служить удобным средством связи между человеком и компьютером.
Здесь уместно провести аналогию с марионеткой. Вы можете заставить марионетку «ходить», манипулируя деревянным приспособлением, даже не касаясь нитей, приводящих ее в движение. Эти манипуляции означают «ходьбу» на языке марионетки. Кукольник управляет марионеткой таким способом, который понятен марионетке и легко осуществим кукольником.
Компьютеры — это машины, подобные марионеткам. Ими нужно управлять, пользуясь специальным языком. И поэтому нам необходим язык, обладающий двумя на первый взгляд противоположными свойствами. С одной стороны, он должен точно выражать смысл приказа компьютеру, передавая последнему всю требуемую для выполнения операции информацию, а с другой — быть предельно простым.
| Со временем появления компьютеров было разработано множество языков: Фортран, который считается старейшиной среди них, Кобол - образец языка для обработки коммерческой информации, Бейсик, предназначенный для тех, кто делает первые шаги на пути изучения таких языков, как Фортран и Кобол. Предметом нашей книги является язык, совершенно не похожий на другие: Форт. Популярность Форта непрерывно возрастает в течение последних нескольких лет; причем во всех областях программирования. Упомянутые выше языки, включая Форт, относятся к языкам высокого уровня. Начинающему важно понять разницу между языком высокого уровня и языком, понятным компьютеру. Все языки высокого уровня выглядят для программиста одинаково, независимо от того, на компьютере какой марки или модели будет выполняться соответствующая программа. Но каждый компьютер имеет свой внутренний, или «машинный», язык. Что же представляет собой машинный язык? Обратимся снова к примеру с марионеткой. Вообразите, что деревянное приспособление для управления марионеткой отсутствует, и кукольник непосредственно держит в руках нити, каждая из которых связана с одной частью тела марионетки. Согласованная комбинация движения отдельных нитей может считаться «машинным языком» нашей марионетки. Теперь представьте себе, что нити привязаны к деревянному приспособлению. Это приспособление соответствует языку высокого уровня. Простым поворотом запястья кукольник может управлять одновременно множеством нитей. Точно так же в языке высокого уровня знакомый вам знак «+» инициирует выполнение множества внутренних функций, в результате чего производится суммирование. Компьютер может быть запрограммирован на перевод символов языка высокого уровня (таких, как «+») в свой собственный машинный язык, после чего он может выполнить полученные машинные команды. Итак, язык высокого уровня — это средство записи программы символами и словами, понимаемыми человеком, которые затем переводятся на машинный язык компьютера конкретной марки или модели. |   |
В чем же состоит отличие Форта от других языков высокого уровня? Это отличие в том, как он разрешает противоречие между человеком и машиной. Язык должен быть удобным для человека, но в то же время соответствовать операциям, выполняемым компьютером. Форт — единственный в своем роде язык, где данная проблема решена уникально. Каким образом она решена, будет показано в дальнейшем.
ОБЛАСТИ ПРИМЕНЕНИЯ ФОРТА (ВВЕДЕНИЕ ДЛЯ ПРОФЕССИОНАЛОВ)
Особенно популярен Форт стал с 1978 г., хотя применялся в основных областях науки, экономики и производства с начала 70-х годов. Где бы вы ни работали, скорее всего, ваша прикладная программа, написанная на Форте, будет выполняться более эффективно, чем на том языке, который вы применяете сейчас. Для того чтобы это понять, вы должны прочитать настоящую книгу, по возможности найти Форт-систему и попытаться с ней поэкспериментировать. В данном разделе вы найдете для себя ответы на два вопроса: «Что такое Форт?» и «Где он может использоваться?».
Форт многогранен. Его можно рассматривать как
• язык высокого уровня;
• язык Ассемблера;
• операционную систему;
• инструментарий для создания программ;
• некоторую концепцию разработки программного обеспечения.
Форт как язык начинается с мощного набора стандартных команд, образующих механизм, с помощью которого вы можете формировать свои собственные команды. Процесс построения определений по модульному принципу — черта, объединяющая Форт с языками высокого уровня. С другой стороны, команды Форта могут быть определены непосредственно на уровне мнемоники ассемблера с помощью ассемблера Форта. Все команды интерпретируются одним и тем же интерпретатором и компилируются одним и тем же компилятором, что придает языку поразительную гибкость. Кодирование вашей программы на самом высоком уровне будет подобно записи этой программы на некотором подмножестве естественного языка. Форт получил название «метаприкладного» языка, так как он позволяет создавать проблемно-ориентированные языки.
Вы можете разбивать задачу на небольшие фрагменты, создавать слова с небольшими определениями, реализующие эти фрагменты, а затем объединять созданные слова небольшими порциями в другие слова. Именно такой подход присущ человеку
в его деятельности. На каждом этапе своей работы программист оперирует лишь несколькими понятиями, соответствующими возможностям кратковременной памяти человека. При использовании этих понятий на последующих этапах мы обращаемся к ним по имени, что соответствует образу мышления человека.
Диалог — неотъемлемое свойство Форта. Новые слова могут быть скомпилированы таким образом, что программист получит возможность сразу же проверять каждую новую команду и следить за состоянием своей программы посредством немедленной обратной связи. (Во многих языках программирования для этого требуется загрузка текстового редактора, редактирование, выход из текстового редактора, загрузка компилятора, компиляция, выход из компилятора, загрузка редактора связей и т. д.) Итерационный подход, при котором оптимальное решение находится в процессе тестирования программных моделей, наиболее приспособлен к интегрированной среде с небольшим временем реагирования на запросы, а именно такую среду и обеспечивает Форт.
Структурные операторы управления Форта вынуждают создавать программу с вложенными структурами, что уменьшает сложность программы. А поскольку реализация Форта ориентирована на вызов слов, то пользователю предпочтительнее работать с небольшими подпрограммами (словами), причем даже с меньшими, чем это позволяют делать традиционные «модульные» языки программирования. Практически без потери эффективности Форт способствует «упрятыванию» информации, что в свою очередь упрощает модернизацию программы. Вследствие этого по имеющимся данным сокращается время разработки Форт-программ: по сравнению с Ассемблер-программами на порядок, а по сравнению с программами на языках высокого уровня — в два раза.
Форт не только увеличивает производительность программирования, но и повышает скорость работы ваших программ. Форт гарантирует быстродействие. Программа, написанная на Форте высокого уровня, выполняется быстрее, чем большинство программ, написанных на других языках высокого уровня; ее производительность составляет почти половину производительности программ, написанных на языке Ассемблера. Критичные по времени фрагменты программ вы можете писать на ассемблере Форта, и они будут выполняться со скоростью, обеспечиваемой процессором.
Помимо всего код Форта компактен. Прикладные программы, написанные на Форте, занимают меньший объем памяти, чем аналогичные программы, созданные с помощью традиционного Ассемблера! Написанная на Форте операционная система вместе со стандартным набором слов занимает менее 8К байт. Вся среда Форта спокойно умещается в пространстве, составляющем 16-32К.
Динамическая среда для объектной прикладной программы может потребовать объем памяти менее 1К байт.
Форт мобилен. Виртуальная Форт-машина реализована почти на всех известных мини- и микрокомпьютерах. На самом деле Форт-архитектура уже воплощена в кремнии.
Ниже приводится несколько примеров применения Форта.
Искусство. Форт используется для управления оборудованием при съемках видеоклипов некоторых рок-групп, а также бегущей строкой рекламы шоу Била Косби. В музыкальной студии электронных инструментов Государственного университета Сан-Хосе язык MASC, являющийся расширением Форта, позволяет композиторам писать музыку для аналоговых синтезаторов.
Программное обеспечение для персональных компьютеров и бизнеса. Форт применялся при разработке учетных программ «Назад к Бейсику» фирмы Peachtree, пакета СУБД фирмы Savvy, системы Симплекс фирмы Quest Research (интегрированная база данных со средствами текстовой обработки и передачи сообщений, макинтошеподобными окнами и графикой) и комплексов Дэйта Эйс и Мастер Тайп. Фирма Bell Canada выбрала Форт для реализации программ аварийной диагностики телефонной связи и сети баз данных, где единственный процессор 68000 обслуживает 32 терминала и базу данных объемом 200 МБ. Фирма Cycledata использует Форт для создания и сопровождения базы данных курса акций с выдачей информации клиентам в реальном времени.
Сбор и анализ данных. Форт применяется во многих крупных обсерваториях планеты. Например, компьютер PDP-11/34 с Форт-системой полностью управляет обсерваторией, в том числе телескопом, куполом, несколькими электронно-лучевыми трубками, строчно-печатающим устройством, дисководами с гибкими дисками, и в то же время обеспечивает сбор данных по инфракрасному излучению из космоса, анализ этих данных и выдачу результатов на графический монитор. Лесная служба США с помощью системы распознавания образов, написанной на Форте, производит анализ и переработку контурных карт. Фирма Dysan применяет написанную на Форте инструментальную систему управления качеством, которая в среде IBM PC работает с битовыми шаблонами, хранящимися на гибких дисках. Устройства измерения глубины, управляемые Фортом, используются на буксирах Миссисипи. NASA, Центр систем океана ВМС США и Центр вооружений ВМС США применяют Форт для различных видов сложного анализа данных. В прикладные программы такого рода часто включаются написанные на Форте программы быстрого преобразования Фурье и Уол-ша, численного интегрирования, а также Форт-программы, реализующие другие математические методы.
Экспертные системы. Для компании General Electric Corporate Research and Development на Форте была создана экспертная система диагностики дизель-электровозов. Форт также использовался компанией Applied Intelligence Systems and IRI, Inc. для промышленного прогнозирования. Центр исследований проблем сна Станфордского университета применяет созданную на Форте экспертную систему в целях идентификации моделей сна.
Графика. Программа Изель и ее приемник Люмена, созданные фирмой Time Arts, Inc., — программы-художники. Обе написаны на Форте и продаются в сочетании с известными графическими системами и системами автоматизированного проектирования.
Медицина. Единственный в Главном госпитале компьютер PDP 11 дает возможность одновременно обслуживать большую базу данных, где хранится информация о пациентах, управлять 32 терминалами и оптическим считывателем, делать анализ крови и измерять пульс больного в реальном времени, осуществлять статистический анализ информации из базы данных для установления соответствия между физическими симптомами заболевания, правильностью диагноза и результатами лечения. Отдел медицинских систем NCR в своей системе 9300, применяемой в больничном обслуживании, также используют Форт. Административный центр по исследованию и совершенствованию реабилитации ветеранов применяет Форт для создания устройств обслуживания инвалидов, включая ультразвуковой детектор, который переводит команды, посылаемые человеком (кивок, поворот головы), в сигналы управления устройством, например креслом на колесах с электроприводом.
Переносные «разумные» устройства. Существует множество разных приборов с встроенными Форт программами: прибор для диагностики заболеваний сердечно-сосудистой системы, самоходный датчик воспламенения, созданный двумя компаниями, прибор для определения относительной влажности различных сортов зерна, транслятор с языка Craig и т. д.
Управление процессами. Лаборатория Jet Propulsion и компания McDonnel Douglas Astronoutics независимо друг от друга выбрали Форт для разработки приборов, применяющихся при создании промышленных материалов в условиях невесомости. Lockheed California и TRW каждая по-своему используют Форт при создании радарных антенн. Фирма Northrup применяет Форт в качестве стандартного языка тестирования. С помощью Форта фирма Johnson Filaments управляет лазерным микроизмерительным роботом при измерении диаметра пластиковых волокон. На предприятиях Union Carbide Форт используется при разработке лабораторных средств автоматизации и создании автоматизированных систем управления процессами.
Роботы. Управляемая голосом сервосистема, применяемая на TRW, написана на Форте. С помощью подвесной автоматической видеокамеры Скайкэм осуществляется трансляция футбольных матчей, а камера фирмы Elicon создает фрагменты для повторного показа. Диапазон других применений Форта —- от управления разгрузкой и погрузкой багажа на главной авиалинии США до сортировки персиков на Калифорнийском консервном заводе.
Форт-процессоры. R65F11 и R65F12, созданные Rockwell International Corp., представляют собой восьмиразрядные процессоры, размещающие 133 Форт-слова на одном кристалле ПЗУ. Вспомогательные кристаллы ПЗУ содержат дополнительные слова Форта, полезные для создания программного обеспечения. Семейство МА2000 National Semiconductor Corp. состоит из набора модулей с интерфейсом через стек, формирующих в совокупности полный автономный Форт-компьютер. Семейство высокоскоростных процессоров Novix NC4000 представляет собой Форт-кристаллы, в которых команды Форта высокого уровня выполняются за один такт.
Завершая введение, хотелось бы обратить ваше внимание на одну особенность Форта. Дело в том, что ответственность за производительность центрального процессора (ЦП) возлагается на вас. Можно провести следующую аналогию. Водителю автомашины ручное управление труднее освоить, чем автоматическое, но все-таки ручное управление позволяет вести автомашину Лучше. Точно так же специалисту труднее изучить Форт, чем традиционные языки высокого уровня, похожие друг на друга (освоив один из них, вы легко можете выучить другой). Но уж если вы однажды выучили Форт, то это даст вам возможность экономно расходовать машинное время и память, а также внедрить новую технологию, с помощью которой вы сможете значительно сократить сроки разработки проекта. И помните, что все компоненты Форта, включая операционную систему, компилятор, интерпретаторы, текстовый редактор, виртуальную память, ассемблер и средства мультипрограммирования, следуют одному и тому же протоколу. Путь к Форту короче, чем изучение по отдельности перечисленных выше компонент.
Если все изложенное здесь вас заинтересовало, значит, вы уже готовы приступить к изучению Форта.
Про ошибки на сайте обязательно сообщите .
ЧТО ТАКОЕ ОПРЕДЕЛЯЮЩЕЕ СЛОВО?
Любое слово, которое создает новый заголовок в словаре, является определяющим. Некоторые из определяющих слов вы уже знаете, в частности : VARIABLE CONSTANT CREATE
Все они обладают одним общим свойством: «определять» слова и добавляют новые имена к словарю. В отличие от других языков Форт позволяет создавать свои собственные определяющие слова. Для чего это нужно? Вообще говоря, определяющие слова способствуют хорошему разбиению программы. Мы уже неоднократно излагали вам концепцию разбиения (см. гл. 8). Такая программа легко читается, легко воспринимается и легко исправляется.
Использование определяющих слов способствует хорошему разбиению, потому что дает возможность создавать целые классы, или семейства, слов с похожими свойствами. Признаки, объединяющие члены некоторого семейства, задаются не в определении каждого члена, а в определяющем слове.
Прежде чем предложить вам пример, рассмотрим, как специфицируются определяющие слова. Основой всех определяющих слов является простейшее из них - слово CREATE. Это слово выбирает из входного потока имя и создает для него в словаре заголовок.
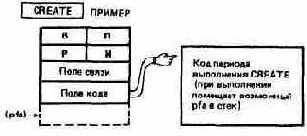
Слово CREATE считается родителем, а слово ПРИМЕР - ребенком. Что делает ребенок в период выполнения? Он помещает свой собственный pfa в стек. А откуда он знает, что нужно делать именно это? Мы не задавали непосредственно ему никакой программы для выполнения. Ответ прост - ПРИМЕР вообще не содержит кода периода выполнения. Его указатель кода указывает на родителя (CREATE), у которого код периода выполнения есть.
Предположим, что в Форте нет слова VARIABLE. Мы можем его определить: : VARIABLE CREATE 0 , ;
Мы обратились к слову CREATE внутри определения через двоеточие. Что при этом произойдет? Давайте проследим за выполнением в хронологическом порядке:

: VARIABLE CREATE 0 , ;
1 Для пользователей систем фиг-Форта. Не забудьте переопределить слово CREATE следующим образом:
: CREATE <BUILDS DOES> ;
Определяется определяющее слово VARIABLE

VARIABLE АПЕЛЬСИНЫ
Исполняется слово VARIABLE, в свою очередь выполняя две функции:
CREATE. Создает с помощью CREATE заголовок в словаре с именем АПЕЛЬСИНЫ и указателем кода, который ссылается на код периода выполнения слова CREATE;
0, Засылает 16-разрядный нуль в поле параметров вновь созданной переменной и выделяет ячейку памяти.

АПЕЛЬСИНЫ
Исполняется слово АПЕЛЬСИНЫ. Так как указатель кода слова АПЕЛЬСИНЫ ссылается на код периода выполнения CREATE, pfa этого слова помещается в вершину стека. Конечно, мы могли бы обойтись без слова VARIABLE. Вполне достаточно ввести следующее: CREATE ПРИМЕР 0 ,
Однако такая запись менее изящна, поскольку здесь разбиты на отдельные действия создание заголовка и выделение памяти. Пример с определением слова VARIABLE демонстрирует лишь половину возможностей механизма определяющих слов. Если бы мы вместо VARIABLE воспользовались словом CREATE, то нам пришлось бы подкорректировать единственное место - в фазе 1, где происходит определение слова АПЕЛЬСИНЫ. И напротив, в фазе 3 слово АПЕЛЬСИНЫ вело бы себя одинаково при определении посредством как CREATE, так и VARIABLE.
Кроме того, Форт дает возможность создавать определяющие слова-родители, задающие поведение своих детей во время исполнения. Ниже в качестве примера приводится правильное определение слова CONSTANT (хотя на самом деле слова, подобные VARIABLE и CONSTANT, обычно определяются с помощью машинных кодов):: CONSTANT CREATE , DOES> @ ;
Здесь «собака зарыта» в выполнении слова DOES>, которое отмечает начало кода периода выполнения для всех своих детей. Как вы знаете, константы (т.е. дети определяющего слова CONSTANT) засылают в стек свои значения, которые хранятся в их поле параметров. Поэтому слово @, которое следует за DOES>, выбирает значение константы из ее собственного pfa.
В любом определяющем слове CREATE отмечает начало действий, выполняемых в период компиляции (фаза 2), a DOES> - конец действий периода компиляции и начало операций периода выполнения (фаза 3).
Проследим еще раз все наши действия:

: CONSTANT CREATE , DOES> @ ;
Определение определяющего слова CONSTANT.

76 CONSTANT ТРОМБОНЫ
Исполнение слова CONSTANT, которое в свою очередь выполняет следующие три действия:

Создает с помощью CREATE заголовок словарной статьи с именем ТРОМБОНЫ. Выбирает из стека значение (например, 76) и заносит его в поле параметров константы. Устанавливает указатель поля кода слова ТРОМБОНЫ на код, следующий за словом DOES.

ТРОМБОНЫ
Выполнение слова ТРОМБОНЫ. Поскольку указатель поля кода слова ТРОМБОНЫ теперь указывает код, следующий за DOES>, выбирается значение (76) и помещается в вершину стека. Обратите внимание на то, что в фазе 3 слово DOES> сначала помещает в вершину стека pfa ребенка. Иными словами, определение : VARIABLE CREATE 0 , ;
эквивалентно следующему: : VARIABLE CREATE 0 , DOES> ;
Последнее в период выполнения помещает в вершину стека pfa, а в период компиляции ничего не выполняет.
Так как определяющее слово задает поведение в двух различных фазах (периодах компиляции и выполнения), нужно соответствующим образом отразить это в стековой нотации. В частности, стековый комментарий определения слова CONSTANT имеет вид: : CONSTANT ( n -- ) CREATE , DOES> ( -- n) @ ;
Верхняя строка стекового комментария описывает поведение родителя во время компиляции, а нижняя, после DOES>, задает поведение ребенка.
DOES> | период-выполнения : ( - a) | Используется при создании определяющих слов. Отмечается конец участка периода компиляции и начала участка периода выполнения. Операции периода выполнения определены на высокоуровневом форте. Во время выполнения на стеке будет находиться pfa определенного слова. |
ЦИКЛЫ С УСЛОВИЕМ
Наряду с циклами DO, которые называются циклами со счетчиком, Форт поддерживает циклы с условием. Цикл такого рода выполняется либо неопределенно долго, либо до тех пор, пока не произойдет некоторое событие. Один из видов цикла с условием — BEGIN ... UNTIL
Этот цикл выполняется до тех пор, пока некоторое условие истинно. Форма его применения: BESIN xxx ? UNTIL
Здесь ххх обозначает слова, которые должны повторяться в рамках цикла, а ? — некоторый флаг. Пока флаг принимает значение «ложь», цикл будет повторяться, но как только флаг примет значение «истина», цикл завершится.
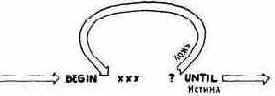
Оператор цикла BEGIN ... UNTIL используется в одном из определений в примере со стиральной машиной, который рассматривался ранее: : ДО-НАПОЛНЕНИЯ BEGIN ?ПОЛОН UNTIL ;
где данное определение применяется в другом определении более высокого уровня: : НАЛИТЬ-ВОДУ КРАНЫ ОТКРЫТЬ ДО-НАПОЛНЕНИЯ КРАНЫ ЗАКРЫТЬ ;
Слово ?ПОЛОН будет определено таким образом, чтобы осуществлять с помощью электронной схемы проверку индикатора уровня воды в емкости машины, который сигнализирует о заполнении емкости, выдавая значение «истина» в стеке. Слово ДО-НАПОЛНЕНИЯ периодически осуществляет проверку снова и снова (тысячи раз в секунду) до тех пор, пока индикатор, наконец, не подаст свой сигнал, после чего цикл завершится. Затем слово ; в ДО-НАПОЛНЕНИЯ направит на выполнение оставшиеся слова в НАЛИТЬ-ВОДУ, и вода будет перекрыта.
Иногда программист вынужден создавать бесконечный цикл. На Форте это лучше всего сделать следующим образом: ВЕGIN xxx FALSE UNTIL
(Слово FALSE выполняет те же функции, что и число 0, поэтому, если в вашей системе нет этого слова, используйте вместо него 0) Так как флаг, относящийся к UNTIL, всегда имеет значение
«ложь», цикл будет повторяться бесконечно. В некоторых системах слово AGAIN заменяет выражение FALSE UNTIL.
Новички обычно стараются избегать бесконечных циклов, поскольку вход в такой цикл означает, что они потеряли управление над компьютером (в том смысле, что при этом выполняются только слова, заключенные внутри цикла).
Но бесконечные циклы имеют право на существование. Например, интерпретатор текста является частью бесконечного цикла под названием QUIT. Он ожидает поступления входных данных, интерпретирует и обрабатывает их, выводит "ok", а затем ожидает ввода следующей порции входных данных. В большинстве устройств, управляемых с помощью микропроцессоров, определения самого высокого уровня содержат бесконечный цикл, описывающий работу данного устройства.
Известна еще одна форма организации цикла с условием1: BEGIN xxx ? WHILE yyy REPEAT
В таком варианте проверка на выход из цикла осуществляется в теле цикла, а не в его конце. Если условие проверки истинно, то оставшаяся часть цикла выполняется, а затем происходит возврат в начало цикла. Если же результат проверки ложный, цикл заканчивается.
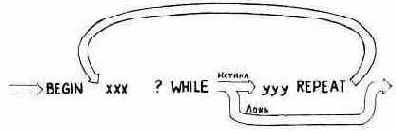
Заметьте, что результат проверки условия в цикле описываемой конструкции противоположен результату проверки в цикле BEGIN ... UNTIL. В первом случае цикл повторяется до тех пор, пока некоторое условие истинно (а не до тех пор, пока оно не станет истинным).
Предположим, у нас имеется некоторая база данных, заполненная именами. Мы уже определили слово НОМЕР-ИМЕНИ, помещающее в стек либо номер следующего имени из списка, либо
1 REPEAT — ПОВТОРЯТЬ, WHILE — ПОКА. — Примеч. пер.
значение «ложь», если список исчерпан. Кроме того, у нас есть слово .ИМЯ, которое выводит само имя по его номеру в стеке. : НОМЕР-ИМЕНИ ( -- номер-имени-или-ложь ) ... ; : .ИМЯ ( номер-имени -- ) ... ;
Допустим, нам нужно вывести список всех имен. До тех пор, пока не распечатан список, мы не знаем, сколько там имен, и поэтому не можем воспользоваться конструкцией DO LOOP, но можем написать определение:: .ВСЕ-ИМЕНА BEGIN НОМЕР-ИМЕНИ DUP WHILE CR .ИМЯ REPEAT PROP ;
А что произойдет, если список окажется пустым? На первом шаге выполнения цикла НОМЕР-ИМЕНИ поместит в стек нуль и вторая часть цикла никогда не будет исполнена. Слова WHILE исключает необходимость в специальной проверке.
ЦИКЛЫ СО СЧЕТЧИКОМ
Одна из циклических структур называется циклом со счетчиком. Здесь вы сами определяете число повторений цикла. На Форте для этого нужно задать начальное и конечное числа перед словом DO (в обратном порядке), а затем поместить слова, выполнение которых вы хотите повторять, между словами DO (ВЫПОЛНИТЬ) и LOOP (ЦИКЛ). Например:
: ТЕСТ 10 0 DO CR ." ПРИВЕТ " LOOP ;
будет осуществлять возврат каретки и выводить слово ПРИВЕТ десять раз, потому что, если вычесть нуль из 10, вы получите 10.
ТЕСТ ПРИВЕТ ПРИВЕТ ПРИВЕТ ПРИВЕТ ПРИВЕТ ПРИВЕТ ПРИВЕТ ПРИВЕТ ПРИВЕТ ПРИВЕТ
Как и оператор IF ... THEN, относящийся к операторам управления, оператор DO ... LOOP должен размещаться в пределах (одного) определения. Число 10 в приведенном примере называется границей цикла (limit), а нуль — индексом (index). Общий вид оператора цикла со счетчиком: граница индекс DO ... LOOP
Теперь посмотрим, что происходит внутри цикла DO ... LOOP:
Слово DO1 берет из стека данных границу и индекс и подготавливает их для слова LOOP, которое по этим данным будет управлять циклическим процессом.
Далее выполняются слова, находящиеся внутри цикла.
1 Единоутробный братец птички ДОДО.
Получив управление, LOOP продвигается на единицу, после чего управление возвращается к DO. Когда LOOP «пересекает» финишную черту, электронный глаз переключает стрелку, разрешая тем самым выполняться операторам, следующим за словом LOOP.
Слово I помещает в стек данных текущее значение индекса (значение, на котором в этот момент стоит LOOP) на каждом шаге циклического процесса. Рассмотрим определение : ДЕКАДА 10 0 DO I . LOOP ;
которое выполняется так, как показано ниже: ДЕКАДА 0 1 2 3 4 8 6 7 8 9 ok
Заметьте, что цикл выполняется всего 10 раз — от 0 до 9. Мы не добираемся до 10, потому что LOOP пересекает границу в тот момент, когда 9 сменяется числом 10.
Вы можете выбрать любые числа, но так, чтобы значение границы превышало значение индекса: : ПРИМЕР -243 -250 DO I . LOOP ; ПРИМЕР -250 -249 -24B -247 -246 -245 -244 ok
И в этом примере значение границы (-243) больше, чем начальный индекс (-250).
ДИАЛОГ
Одно из специфических свойств Форта состоит в том, что он дает возможность «выполнить» слово, просто написав его. Достаточно просто набрать это слово на клавиатуре и нажать клавишу RETURN (возврат каретки или ввод). Конечно, можно применять данное слово в определении других слов, помещая его в соответствующее определение.
Форт называется диалоговым языком, потому что его команды выполняются сразу, как только вы их вводите. В качестве примера (вы можете его выполнить самостоятельно) рассмотрим процесс объединения простых команд в более сложные. Мы будем использовать некоторые слова Форта для управления экраном дисплея или печатающим устройством. Но прежде познакомимся с механизмом «диалога» посредством клавиатуры терминала.
Займите место за своим терминалом (для некоторых он будет воображаемым). Возможно, кто-нибудь великодушно предоставит вам условия для занятий, в противном случае вам придется внимательно интерпретировать самому все команды, предназначенные вашему компьютеру. Нажмите клавишу RETURN. Компьютер ответит: ok («все в порядке»), что означает приглашение к работе. С помощью клавиши RETURN вы передаете компьютеру свой запрос. Ответ jak свидетельствует о том, что ваш запрос выполнен, причем без единой ошибки. Мы пока ни о чем не просили, поэтому компьютер послушно ничего не выполнил и выдал приглашение ok.
Теперь введите 15 SPACES
что означает 15 ПРОБЕЛОВ.
Для многих Форт-систем имеет значение, на каком регистре — верхнем или нижнем — вы набираете текст, поэтому, вводя SPACES, убедитесь в том, что набираете эту строку на верхнем регистре. Если во время набора была допущена ошибка, вы можете исправить ее, нажав клавишу backspace (возврат на одну позицию). Вернитесь к тому месту, где сделана ошибка, введите нужный символ и продолжайте набор. Набрав строку правильно, нажмите клавишу RETURN. (После нажатия клавиши RETURN исправлять ошибку уже поздно.)
В дальнейшем мы будем использовать обозначение <return> в тех местах, где вы должны нажимать клавишу RETURN, и подчеркивать ответы компьютера, чтобы отличать их от других символов (даже если сам компьютер и не подчеркивает свои ответы ).
Что произойдет в такой ситуации:15 SPACES<return> ok
Как только вы нажали клавишу ввода, компьютер выведет 15 пробелов и затем, выполнив ваш запрос, выдает: ok (после 15-го пробела).
Наберите на клавиатуре следующее:42 EMIT<return> *ok
Фраза «42 EMIT» приказывает компьютеру вывести символ * (мы обсудим эту команду позднее). Компьютер выводит требуемый символ, а затем ok
На одной строке мы можем помещать несколько команд. Например:15 SPACES 42 EMIT 42 EMIT<return> **ok
На этот раз компьютер выводит 15 пробелов и две звездочки. Отметим, что при вводе слов и/или чисел их можно разделять любым количеством пробелов (как вам удобно), но между ними должен быть хотя бы один пробел, чтобы компьютер мог различать слова и/или числа.
Вместо того чтобы всякий раз вводить фразу 42 EMIT
давайте определим ее как слово STAR (ЗВЕЗДОЧКА). Итак, введите: : STAR 42 EMIT ;<return> ok
Здесь STAR — имя, а 42 EMIT — определение. Заметьте, что мы отделили двоеточие и точку с запятой от соседних с ними слов одним пробелом. Чтобы определения Форта легче воспринимались, условимся отделять имя определения от собственно определения тремя пробелами.
После того как вы наберете на клавиатуре приведенное выше определение и нажмете клавишу RETURN, компьютер ответит вам: ok, т. е. он распознал ваше определение и запомнил его. Введите далее:STAR<return> *ok
Как видите, компьютер выполнил ваш приказ и выдал звездочку. Определенное вами слово STAR ничем не отличается от определенного ранее EMIT. Поэтому чтобы вам легче было ориентироваться, ранее определенные слова мы будем выделять полужирным шрифтом.
Другим определенным системой словом является CR, которое обеспечивает возврат каретки и перевод строки на вашем терминале. Обязательно почувствуйте разницу в использовании клавиши RETURN и словом Форта CR. В качестве примера наберите на клавиатуре CR<return> ok
Компьютер осуществил возврат каретки, а затем вывел ok (на следующей строке).
Введите такой текст: CR STAR CR STAR CR STAR<return>
* *ok
Поместим CR в определение слова MARGIN (ПОЛЕ ПРОБЕЛОВ): : MARGIN CR 30 SPACES ;<return> ok
Теперь вы можете ввести следующее: MARGIN STAR MARGIN STAR MARGIN STAR<return>
и получите три вертикально расположенные звездочки, дополненные слева 30 пробелами.
Комбинация слов MARGIN STAR пригодится нам в дальнейшем, поэтому введем определение BLIP (ТОЧКА): : BLIP MARGIN STAR ;<return> ok
Нам также предстоит выводить горизонтальные последовательности звездочек. Для этой цели введем следующее определение (его назначение мы объясним позднее): : STARS 0 DO STAR LOOP ;<return> ok
Итак, мы можем ввести: 5 STARS<return> *****ok
или 35 STARS<return> ***********************************ok
или любое представимое число звездочек! Однако нельзя задавать сочетание "0 STARS", в особенности для систем Форта-83. Подробнее об этом речь пойдет в гл. 6.
Нам необходимо слово, которое выполняет команду MARGIN, а затем выводит пять звездочек. Определим слово BAR (ПО-ЛОСКА): : BAR MAR6IN 5 STARS ;<return> ok
после чего можно ввести строку: 3AR BLIP BAR BLIP BLIP CR
В результате вы получите букву F, составленную из звездочек:
*****
*
*****
*
*
В заключение определим слово для этой новой процедуры. Назовем его F: : F BAR BLIP BAR BLIP BLIP CR ;<return> ok
В этом примере показано, каким образом простые команды Форта могут становиться основой для образования более сложных команд. Программа на Форте выглядит скорее как ряд нарастаю-щих по мощности определений, чем как последовательность команд, задающая порядок их выполнения. Чтобы вы имели представление о реальной Форт-программе, мы приводим здесь распечатку нашей учебной программы: 0 ( Большая буква F ) 1 : STAR 42 EMIT ; 2 : STARS 0 DO STAR LOOP ; 3 : MARGIN CR 30 SPACES; 4 : BLIP MARGIN STAR ; 5 : BAR MARGIN 5 STARS; 6 : F BAR BLIP BAR BLIP BLIP CR ; 7 8
ДЛЯ НАЧИНАЮЩИХ
7.1. Вероника Вэйнрайт не могла вспомнить верхнее значение для чисел одинарной длины со знаком. У нее не было книги, по которой она могла бы справиться, а была только Форт-система, поэтому она написала определение N-MAX с использованием цикла BEGIN ... UNTIL. После выполнения этого определения у нее получилось следующее: 32767 ok
Восстановите написанное ею определение.
7.2. (Данное упражнение позволит вам приобрести навыки работы с битами.) Прежде всего, если вы не сделали этого ранее, определите слово BINARY.
а) Разряды внутри 16-разрядной ячейки нумеруются с 0 до 15 справа налево, так что нулевым разрядом является самый младший бит, а 15-м - самый старший.
Определите слово с именем БИТ, которое переводило бы номер разряда (от 0 до 15) в маску, соответствующую этому разряду, например 0 бит соответствует маске 1, бит 1 - маске 2, бит 3 - маске 4 и т. д. (Совет: проще всего использовать цикл DO.)
б) Пусть в стеке находится значение, представляющее некоторый массив из 16разрядов (назовем его «битовый!»). Определите слово с именем УСТАНОВИТЬ-БИТ, которое устанавливало бы в единицу заданный бит в массиве «битовый!» при следующей стековой нотации: (битовый! номер-бита - битовый2). Например, если в стеке находится битовый шаблон, равный двоичному числу 1000, и вы выполняете последовательность команд 1 УСТАНОВИТЬ-БИТ (в десятичной системе), то получите в результате 1010.
в) Определите слово ОЧИСТИТЬ-БИТ, которое сбрасывает заданный бит. Стековая нотация та же, что и для слова УСТАНОВИТЬ-БИТ. Например: BINARY 11111111 DECIMAL 5 ОЧИСТИТЬ-БИТ 7 ОЧИСТИТЬ-БИТ BINARY U. 101011111
г) Определите слово ДАЙ-БИТ, вносящее в стек указанный бит (выбранный посредством маски из массива «битовый»), который мог бы служить аргументом оператору IF (т. е. если бит установлен в единицу, то в стек помещается значение «истина», если нет, - «ложь»). Стековая нотация выглядит следующим образом: (битовый номер-бита - бит).
Например:BINARY 1001 DECIMAL DUP 0 ДАЙ-БИТ . 1 ok DUP 1 ДАЙ-БИТ . 0 ok 3 ДАЙ-БИТ . 8 ok
д) Определите слово с именем ПЕРЕКЛЮЧИТЬ-БИТ с той же стековой нотацией, что и для слов УСТАНОВИТЬ-БИТ и ОЧИСТИТЬ-БИТ, которое переключало бы заданный бит (устанавливало бы его в единицу, если бы он был сброшен, и наоборот).
е) Пусть заданы две битовые последовательности, причем вторая получена путем изменения значений нескольких битов первой. Определите слово с именем ИЗМЕНЕНИЕ, которое воспроизводило бы битовую маску с измененными битами.
7.3. Напишите определение, которое заставило бы зазвонить колокольчик на вашем терминале три раза Убедитесь в том, что перерыв в звучании достаточен для того, чтобы отдельные звонки не слились в один длинный звонок. Всякий раз при звучании колокольчика на экране терминала должно появляться слово БИП.
Упражнения 7.4 и 7.5 посвящены выполнению операций над числами двойной длины.
7.4 а) Перепишите созданные в гл. 5 определения перевода значений температур из одной шкалы в другую в предположении, что вводимые в результирующие значения температур должны быть представлены целыми числами двойной длины со знаком с коэффициентом масштабирования 10 (т. е. должны быть умножены на 10). Например, если вы вводите фактическое значение 10.5°, то оно будет представлено 32-разрядным целым числом со значением 105.
б) Напишите слово для форматного вывода с именем .ГРАДУСЫ, которое будет выдавать 32-разрядное целое с коэффициентом масштабирования 10 как строку цифр с десятичной точкой и одной дробной цифрой. Например:12.3 .ГРАДУСЫ<return> 12.3 ok
в) Преобразуйте следующие значения температур:0.0 °F в °С 212.0 °F в °С 20.5 °F в °С 16.0 °С в °F -40.0 °С в °F 100.0 °К в °С 100.0 °К в °F 233.0 °К в °С 233.0 °К в °F
7.5, а) Напишите программу, которая вычисляет значение полинома 7х2 + 20х + 5 при заданном х и выводит результат в виде числа двойной длины.
б) Какое максимальное значение может принимать х, чтобы при вычислении результата как 32-разрядного числа со знаком не произошло переполнения?
ДЛЯ ВСЕХ
7.6. Неопытный пользователь экспериментирует с шестнадцатиричными числами и пытается вернуться снова к десятичной форме, вводя команду DEC. Несмотря на то что Форт-система выводит ok, пользователю кажется, что перевод из одной системы счисления в другую не происходит. Что случилось?
7.7. Напишите слово, которое бы выводило числа от 0 до 16 (десятичных) в десятичной, шестнадцатиричной и двоимой системах счисления в три столбца, т. е.DECIMAL 0 HEX 0 BINARY 0 DECIMAL 1 HEX 1 ВINARY 1 DECIMAL 2 HEX 2 BINARY 10 ... DECIMAL 16 HEX 10 BINARY 10000
7.8. Введите число 37 и дважды выполните команду . (точка). Объясните, что вы получили и почему. Введите число Ь5536. и дважды выполните команду . . Объясните результат. Попытайтесь ввести число 65538. (с десятичной точкой).
7.9. Если вы вводите ..<return>
(две точки, не разделенные пробелом) и система отвечает вам ok, что это означает? 7.10. Напишите определение для форматного вывода номера телефона, которое одновременно выводит через слэш номер района тогда и только тогда, когда в этот номер включен номер района, т. е. 555-1234 .ТЕЛЕФОН 555-1234 ok 213/372-8493 .ТЕЛЕФОН 213/372-6493 ok
(В некоторых системах вместо слэша и дефиса может быть выведена десятичная точка )
Про ошибки на сайте обязательно сообщите .
DROP (ИСКЛЮЧИТЬ/УДАЛИТЬ)
Последняя в нашем списке операция со стеком — DROP. Ее назначение состоит в том, чтобы удалить верхний элемент из стека
Просто, не правда ли? Позднее мы найдем для этой операции несколько хороших применений.
DUP (дублирование)
При выполнении следующей в списке операции над стеком, DUP, просто создается второй экземпляр верхнего элемента стека. Например, если у вас в стеке есть элемент а, то вы можете вычислить а2:

DUP *
При этом выполняются следующие действия:
| ОПЕРАЦИЯ | СОДЕРЖИМОЕ СТЕКА |
| a | |
| DUP | a a |
| * | a2 |
ДВА СЛОВА С ВСТРОЕННЫМИ ОПЕРАТОРАМИ IF
DUP
Слово ?DUP дублирует вершину стека только в том случае, если там находится нулевое значение. Это помогает избавиться от лишних слов. Например, определение : ?EMIT ( с -- ) DUP IF EMIT ELSE BROP THEN ;
выдает на печать символ с любым кодом (кроме 0) Применяя ?DUP, можно сократить наше определение:: ?EMIT ( с -- ) ?DUP IF EMIT THEN ;
ABORT"
В каком-то месте сложной прикладной программы может быть обнаружена ошибка (например, деление на нуль), которая проявляется в одном из слов низкого уровня. Когда это происходит, вы, естественно, хотите, чтобы компьютер прекратил вычисления и чтобы из стека были удалены все данные.
Если вы предполагаете, что подобная ошибка может произойти, можно воспользоваться оператором аварийного прекращения выполнения задачи ABORT". Этот оператор проверяет значение флага я вершине стека и в случае его истинности прерывает вычисления. Оператор очищает стек и возвращает управление на терминал до поступления какого-либо сообщения. Оператор ABORT" также выводит имя последнего слова, обработанного текстовым интерпретатором, и предусмотренное вами для такой ситуации сообщение1.
Проиллюстрируем изложенное примером:: /ПРОВЕРКА ( числитель -знаменатель — результат) DUP 0= ABORT" Знаменатель нуль " / ;
Р этом определении, если знаменатель равен нулю, то любое оказавшееся в вершине стека, удаляется из последнего, а на терминал выводится сообщение:8 0 /ПРОВЕРКА /ПРОВЕРКА Знаменатель нуль
Теперь в порядке эксперимента попытайтесь поместить слово /ПРОВЕРКА внутрь другого определения: : ОБОЛОЧКА /ПРОВЕРКА ." Ответ равен " . ;
1 Для профессионалов. В Форте, кроме того, имеются слова. QUIT (ОКОНЧИТЬ), которое вызывает прекращение работы программы, но не очищает стек, и ABORT (ПРЕРВАТЬ), которое выполняет те же действия, что и QUIT, очищает стек но не выводит сообщение Мы рассмотрим эти слова в гл 9
и введите 8 4 ОБОЛОЧКА Ответ равен 2 Ок 8 0 ОБОЛОЧКА ОБОЛОЧКИ Знаменатель нуль
Обратите внимание на то, что когда слово /ПРОВЕРКА аварийно прерывает работу с помощью оператора ABORT", оставшаяся часть ОБОЛОЧКА пропускается.
Заметьте также, что выводится имя ОБОЛОЧКА, а не /ПРОВЕРКА.
Ниже приводится перечень слов Форта, рассмотренных в настоящей главе.IF xxx IF: ( ? -- ) Выполнение ххх, вели ? истинно (не EL5E yyy нулевое значение) , и yyy, - если ? THEN zzz ложно, zzz выполняется независимо от выбранного варианта. Выражение ууу является необязательным.
== ( n1 n2 -— ? ) Занесение в стек истины если n1 и n2 равны.
<> ( n1 n2 -- ? ) Занесение в стек истины, если n1 и п2 не равны.
< ( n1 n2 -- ? ) Занесение в стек истины, если n1 меньше n2.
> ( n1 n2 -- ? ) Занесение в стек истины, если n1 больше n2.
0= ( n -- ? ) Занесение в стек истины, если n является нулем (то есть истина меняется на ложь и наоборот).
0< ( n -- ? ) Занесение в стек истины, если n отрицательно.
0> ( n -- ? ) Занесение в стек истины, если n положительно.
NOT ( ? -- ? ) Изменение значения флага на противоположное.
AND ( n1 n2 -- И ) Доставление логического значения, согласно таблице операции AND.
OR ( n1 n2 -- ИЛИ) Занесению в стек логического значения, согласно таблице операции OR.
XOR ( n1 n2 -- Занесение в стек логического знамения, ИСКЛЮЧ-ИЛИ ) согласно таблице операции XOR.
?DUP ( n -- n n ) или Дублирование вершины стека только в том слу- ( 0 -- 0 ) чае, если n является ненулевым значением.
ABORT" ххх" ( ? -- ) Если значение флага истинно, то вывод последнего проинтерпретированного слова и за ним заданного текста. Кроме этого очищает стеки пользователя и возвращается управление на терминал. Если в стеке ложь, то не предпринимается никаких действий.
Обозначения: n,n1 ... 16-раэрядные числа со знаком. ? - логическое значение (флаг)
Следующие четыре операции должны вам
Следующие четыре операции должны вам показаться знакомыми:
| 2SWAP | ( dl d2 -- d2 dl ) | Перестановка двух верхних пар элементов стека |
| 2DUP | ( d -- d d ) | Дублирование верхней пары элементов стека. |
| 2OVER | ( d1 d2 -- dl d2 d1 ) | Копирование второй пары элементов стека и размещение копии в вершине стека. |
| 2ROT | ( dl d2 d3 -- d2 d3 d1 ) | Размещение третьего элемента в вершине стека. |
| 2DROP | ( d -- ) | Удаление верхней пары элементов из стека. |
2 Для специалистов. Эти операции также могут выполняться над числами двойной длины (32 бита, или разряда).
Это понятие имеет вполне конкретный смысл, который объясняется в гл. 7. Операции над двойными числами настолько очевидны, что нет необходимости приводить примеры на их выполнение. Заметим лишь, что. кроме перечисленных существуют еще несколько операций, о которых здесь еще не упоминалось, поэтому не пытайтесь самостоятельно работать со стеком, так как вы будете выполнять много ненужных действий, в чем и убедитесь впоследствии. Ниже приводится перечень слов Форта, которые были введены в данной главе:
|
+ |
( nl n2 — сумма) |
Сложение. |
|
- |
( n1 n2 — разность) |
вычитание (nl-n2) . |
|
* |
( n1 л2 — произвел) |
Умножение. |
|
/ |
( n1 n2 — частное) |
Деление (nl/n2) . |
|
MOD |
( nl n2 — n-остаток) |
Деление. В стек заносится остаток от деления. |
| /MOD | ( u1 u2 — n-остаток n— частное) |
Деление, В стек заносятся остаток и частное» |
|
SWAP |
() n1 n2 — n2 n1) |
Перестановка двух верхних элементов стека. |
|
BUP |
{ n — n n) |
Дублирование верхнего элемента стека. |
|
OVER |
( nl n2 — nl n2 nl) |
Копирование второго элемента и размещение копии в вершине стека. |
|
ROT |
( ni n2 n3 — n2 n3 nl) |
Размещение третьего элемента в вершине стека. |
|
DROP |
( n — ) |
Удаление из стека верхнего элемента. |
|
2SWAP |
( dl d2 — d2 dl) |
Перестановка двух верхних пар чисел. |
|
2DUP |
( d — d d) |
Дублирование пары чисел, находящейся в вершине стека. |
|
20VER |
( d1 d2 -- dl d2 dl) |
Копирование второй пары чисел и размещение копии в вершине стека. |
|
2DROP |
( d — ) |
Удаление из стека верхней пары элементов. |
ЕЩЕ ОДИН ВАРИАНТ ИСПОЛЬЗОВАНИЯ СТЕКА ВОЗВРАТОВ
Итак, вы уже знаете, каким образом Форт-система хранит адреса возврата в стеке возвратов, и вам понятно, почему при хранении в этом стеке временных переменных нужна особая осторожность. При выполнении следующего определения : ТЕСТ 3 >R CR CR CR ;
в стек возвратов помещается значение 3, затем три раза осуществляется возврат каретки и происходит возврат, но куда? По адресу 3 нет никакого слова, поэтому скорее всего вероятно разрушение системы.
В большинстве Форт-систем во время выполнения цикла DO информация об индексе и границе хранится в стеке возвратов (и
не всегда в том виде, в котором вы ожидаете). Именно поэтому в пределах цикла DO LOOP использование операций >R и R> должно быть симметричным. Другими словами, вы имеете право писать так: ... >R ... DO ... LOOP ... R> ... ;
и не должны писать иначе, например: ... >R ... DO ... R> ... LOOP ... ;
Кроме того, если вы внутри тела цикла поместите в стек возвратов временное значение, то слово выборки индекса цикла I не будет выполняться правильно: ... DO ... >R ... I ... R> ... LOOP 5
ЕЩЕ РАЗ О СЛОВАРЕ
Поработав с настоящим компьютером, вы, возможно, сделали бы для себя кое-какие открытия, о которых еще не упоминалось.
Открытие первое: вы можете дать одному и тому же слову несколько определений, приписывая ему всякий раз новый смысл, но выполняться будет только последнее определение.
Например, если вы определили слово ВСТРЕЧА:: ВСТРЕЧА . " Привет. Я говорию на форте. " ; _ок
то при его выполнении получите следующий результат:ВСТРЕЧА привет. Я говорю на Форте. ок
Но если вы переопределите это слово: : ВСТРЕЧА ." Алло, я слушаю вас! " ; ок
то при его выполнении сработает более позднее определение: ВСТРЕЧА Алло, я слушаю вас. ок
Исчезло ли первое определение ВСТРЕЧА? Нет, оно сохранилось, но текстовый интерпретатор всегда начинает просмотр словаря с конца — с элемента, занесенного в словарь последним. Из нескольких определений с одним и тем же именем интерпретатор передает слову EXECUTE первое встретившееся. Вы можете убедиться в том, что прежнее определение ВСТРЕЧА все еще находится в словаре. Для этого наберите на клавиатуре FORGET ВСТРЕЧА ок
и ВСТРЕЧИ Привет. Я говорю на Форте, ок
(Действует снова старое определение!)

Слово FORGET (ЗАБЫТЬ) ищет указанное слово в словаре и удаляет из словаря (это его основная функция) само слово, а также все то, что вы успели определить после него. FORGET, как и интерпретатор, начинает свой поиск с конца: он удаляет только последний вариант определения данного слова (вместе со всеми словами, специфицированными после него). Поэтому теперь, если вы наберете на клавиатуре слово ВСТРЕЧА, интерпретатор найдет первоначальное слово ВСТРЕЧА. FORGET — очень полезное слово. Оно помогает вам очищать ваш словарь во избежание его переполнения. (Словарь занимает память, а мы должны ее экономить.)
Открытие второе: если вы вводите определение с помощью клавиатуры (как вы сейчас это делаете), то исходный текст1 его не сохраняется.
1 Для начинающих. Исходным текстом называется текстовый вариант определения, например:
: ПЛЮС-ЧЕТЫРЕ ( n — n+4) 4 + ;
Этот первоначальный, исходный, вариант преобразуется в словарную форму и становится элементом словаря.
В словаре запоминается только скомпилированная форма вашего определения. А как быть, если вы захотите внести изменение в уже определенное слово? Вы должны повторно набрать полностью все определение, внеся в него соответствующие изменения. Это может показаться вам достаточно утомительным, не так ли? И даже хуже:
Открытие третье: если вы выключите компьютер, а затем снова включите его, то все набранные вами определения исчезнут.
Очевидно, что необходим какой-то способ запоминания исходного текста с тем, чтобы его можно было изменять и перекомпилировать в любое время. Здесь-то и приходит вам на помощь редактор. Он позволяет запомнить ваш исходный текст на диске. Поэтому давайте выясним, что представляет собой диск и как Форт-система работает с ним.
ФЛАГ СОСТОЯНИЯ
Введем последний термин, имеющий отношение к процессу компиляции, - состояние. В большинстве Форт-систем есть переменная с именем STATE (СОСТОЯНИЕ), в которой содержится «истина», если вы работаете в режиме компиляции, и «ложь», если вы работаете в режиме интерпретации. Покажем способ вывода значения переменной STATE: : .СОСТОЯНИЕ STATE ? ; IMMEDIATE
Введите: .СОСТОЯНИЕ 0 ok
В момент вызова .СОСТОЯНИЕ Форт-система находилась в режиме интерпретации (то, что .СОСТОЯНИЕ является словом немедленного исполнения, не играет роли. Интерпретатор не проверяет бит немедленного исполнения).
Теперь вызовите слово .СОСТОЯНИЕ из нового определения: : ТЕСТ .СОСТОЯНИЕ ; -1 ok
На сей раз значение STATE равно «истине», поскольку .СОСТОЯНИЕ было инициировано компилятором.
В каких случаях возникает необходимость знать состояние? Всегда, когда вы хотите создать слово, которое должно «делать вид», что его поведение одинаково как внутри определения, так и вне его, а на самом деле оно проявляет себя по-разному. В качестве примера можно привести слово ASCII. При обычном использовании это слово появляется внутри определения через двоеточие: : ТЕСТ ( -- ascii-a) ASCII A ;
При исполнении слова ТЕСТ в вершину стека вносится число 65. ASCII осуществляет преобразование во время компиляции, Оно должно быть компилирующим словом: выбирать из входного потока символ, компилировать его как литерал, чтобы последний мог быть занесен в стек во время выполнения слова ТЕСТ. Вы можете создать компилирующий вариант слова ASCII следующим образом:: ASCII ( -- с ) \ Компиляция: с ( -- ) BL WORD 1+ С@ [COMPILE] LITERAL ; IMMEDIATE
(Примечание. Стековый комментарий в первой строке определяет поведение слова во время выполнения - это синтаксис использования слова. Комментарий во второй строке показывает, что должно произойти во время компиляции, в частности должно быть выполнено считывание символа из входного потока и ничего не оставлено в стеке.)
В приведенном выше определении слово WORD выбирает из входного потока текст, ограниченный пробелом, и вносит в вершину стека адрес участка памяти, где будет храниться строка со счетчиком.
Мы считаем, что такой текст содержит только один символ, поэтому пропускаем счетчик байтов посредством 1+ и выбираем значение с помощью С@ . Затем инициируем слово LITERAL, компилирующее код периода выполнения для литерала, за которым следует само значение. Это все, что нам требуется.
Попытаемся заставить ASCII выполняться вне определения. Например, выражение ASCII A
внесет в вершину стека значение 65 (что может оказаться полезным при составлении таблиц и т. д.). Далее «попросим» ASCII выполнить что-нибудь такое, что оно еще не делало. Создадим следующий вариант определения: : ASCII ( -- с) BL WORD 1+ C@ ;
Для того чтобы одно и то же слово ASCII могло выполняться в обоих вариантах, оно должно реагировать на состояние: ASCII ( -- c) \ КОМПИЛЯЦИЯ: c ( -- ) \ Интерпретация: с ( -- с) BL WORD 1+ С@ STATE @ IF [COMPILE] LITERAL THEN ; IMMEDIATE
Такое слово называется зависимым от состояния. На первый взгляд зависимость от состояния кажется свойством разумным и даже желательным, особенно для слова ASCII, которое используется только при компиляции. Однако когда программист пытается повторно применять зависимые слова в другом определении и хочет, чтобы они выполнялись обычным образом, возникают трудности. Приведем пример использования компилирующего слова, зависимого от состояния, в определении другого компилирующего слова. По мере того как растет глубина вложенности слова, зависимого от состояния, программисту приходится затрачивать все больше усилий на то, чтобы держать под контролем, что и где должно выполняться.
Применение простых слов безопаснее, чем зависимых от состояния, так как их поведение предсказуемо. В некоторых ранее созданных системах слово ." зависело от состояния. С введением Стандарта-83 оно было разделено на два отдельных слова, управляющих использованием во время компиляции (.") и в период выполнения во время интерпретации блоков при их загрузке (.().
Слово ' постигла участь описанных выше слов и теперь это простое слово.Его функции внутри определения аналогичны функциям, выполняемым во время интерпретации: оно выявляет определение, имя которого находится во входном потоке во время исполнения. Вариант апострофа, функционирующего как компилирующее слово, называется ['].
Некоторые разработчики Форта считают, что зависимость от состояния не имеет права на существование. Применительно к ASCII возможны два решения: 1) разрешить его использование только внутри определения и, если возникает необходимость, создать слово с другими функциями, скажем ascii (на нижнем регистре), для режима интерпретации; 2) сделать его пригодным только для интерпретации: : ТЕСТ [ ASCII A ] LITERAL ;
Можно договориться и ввести другое слово: : [ASCII] ASCII [COMPILE] LITERAL ; IMMEDIATE
которое рекомендуется применять следующим образом: : ТЕСТ [ASCII] A ;
ФОРМАТИРОВАНИЕ ЧИСЕЛ ОДИНАРНОЙ ДЛИНЫ СО ЗНАКОМ
До сих пор мы форматировали только числа двойной длины без знака Xoтя структура <#...#> применима именно к таким числам, попробуем воспользоваться ею и для других типов чисел, выполнив определенные манипуляции со стеком. Например, рассмотрим простейший вариант системного определения D. (оно выводит число двойной длины со знаком):
: D. ( d -- ) DUP >R DABS <# #S R> SIGN #> TYPE SPACE ;
Слово SIGN, которое должно располагаться внутри выражения форматного вывода, вставляет знак "-" в строку символов лишь в том случае, если верхний символ в стеке является отрицательным. Следовательно, мы должны сохранить копию верхней ячейки (содержащей знак) в стеке возвратов для дальнейшего использования.
Так как <# требует наличия лишь чисел двойной длины без знака, мы должны взять абсолютное значение нашего числа двойной длины со знаком с помощью слова DABS. Теперь расположение аргументов в стеке соответствует выражению форматного вывода. Затем #S осуществляет перевод цифр справа налево, после чего мы заносим в стек знак. Если этот знак отрицательный, то SIGN добавляет к форматированной строке минус1. Так как нам нужно, чтобы знак минус располагался слева, включаем SIGN справа в структуру <;#..#!>. В некоторых случаях, например в бухгалтерских расчетах, может потребоваться вывод отрицательных чисел в виде 12345-. В подобной ситуации мы должны поместить слово SIGN слева в выражение <# ...#:>, как показано ниже:<# SIGN #S #>
1 Для пользователей более ранних систем. Слово SIGN имеет свою историю. Первоначально в качестве аргумента этого слова выступал третий элемент стека. Таким образом, для того чтобы определить слово D., нужно было писать
: D. ( d -- ) SWAP OVER DABS <# #S SIGN #> TYPE SPACE ;
Выражение "SWAP OVER" помещает копию верхней ячейки (той, что со знаком) на дно стека. Чтобы упростить выражение форматного вывода, операцию ROT решено было перенести в определение слова SIGN.
Данное соглашение действовало в системах фиг-Форт и системах полиФорт, разработанных до введения Стандарта-83.
В системах Форт-79 и Форт-83, а также Форт-системах МУР и MMS используется соглашение о передаче знака через вершину стека, что в большей степени соответствует механизму передачи данных через стек.
Если вы располагаете старой версией, определите SIGN следующим образом:
: SIGN ( n -- ) 0< IF ASCII - HOLD THEN ;
Определим слово, которое выводило бы число двойной длины со знаком с десятичной точкой и двумя десятичными значениями после точки. Поскольку такая форма часто используется для представления какой-либо суммы в долларах и центах, назовем это cлово .$ и определим его следующим образом:: .$ ( d -- ) DUP >R DABS <# # # ASCII . HOLD #S R> SIGN ASCII S HOLD #> TYPE SPACE ;
Проверим его: 2000.00 .$ $2000.00
или даже так:2,000.00 .$ $2000.00
Рекомендуем вам сохранить определение .$, которое пригодится нам в дальнейшем в некоторых примерах.
Вы можете также описать форматы чисел одинарной длины. Например, если вы хотите использовать число одинарной длины без знака, то просто поместите в стеке перед словом <# нуль. Такое число одинарной длины легко превратить в число двойной длины, которое настолько мало, что его часть, содержащаяся в верхней по порядку ячейке, равна нулю,
Для представления числа одинарной длины со знаком вам достаточно поместить нуль в старшую по порядку ячейку. Но вы также должны сохранить копию числа со знаком для SIGN и, кроме того, оставить абсолютное значение этого числа во втором элементе стека. Все необходимые действия выполняет следующее выражение: ( n -- ) DUP >R ABS 0 <# #S R> SIGN #>
Ниже приводятся «стандартные» выражения, которые применяются для вывода различных видов чисел: СЛОВУ <# ПРЕДШЕСТВУЕТ ВЫВОДИМОЕ ЧИСЛО ВЫРАЖЕНИЕ 32-разрядное без знака (ничего) 31-разрядное плюс знак DUP >R DABS (чтобы сохранить знак в третьем элементе стека для SIGN) 16-разрядное без знака 0 (чтобы получить фиктивную, старшую по порядку, часть) 15-разрядное плюс знак DUP >R ABS 0 (чтобы сохранить знак)
ФОРМИРОВАНИЕ ЧИСЕЛ ДВОЙНОЙ ДЛИНЫ БЕЗ ЗНАКА
Приведенные ниже слова: 8200.00 12/31/86 372-8493 6:32:59 98.6
иллюстрируют типы форматов вывода, которые вы можете создать, определив ваши собственные слова «форматного вывода» Форта. Рассмотрим этот вопрос подробнее.
Самое простое определение форматного вывода вы можете написать следующим образом: : UD. ( ud -- ) <# #S #> TYPE ;
UD. предназначено для вывода числа двойной длины без знака. Слова <# и #> (СКОБКА-ЧИСЛО и ЧИСЛО-СКОБКА) означают начало и конец процесса преобразования числа. В данном определении весь перевод осуществляется единственным словом #S (ЧИСЛА). #S преобразует значение из стека в символы кода ASCII. По этой команде формируется столько цифр, сколько их необходимо для представления числа: незначащие нули она не выводит. Однако всегда выводится по крайней мере одна цифра: если значение равно нулю, то выводится нуль, например: 12,345 UD. 12345ok
12, UD. 12ok 0. UD. 0ok
Слово TYPE (ПЕЧАТЬ) выводит символы, которые составляют число. Заметьте, что между числом и приглашением ok нет пробела. Для того чтобы вывести пробел, вы должны просто добавить слово SPASE, как это сделано в приведенном ниже примере:: UD. ( ud -- ) <# #S #> TYPE SPACE ;
Предположим, что у вас в стеке имеется номер телефона, выраженный 32-разрядным целым числом, скажем 372-8493 (помните, что дефис указывает NUMBER на то, что число нужно воспринимать как значение двойной длины. В вашей системе это может быть точка). Вы хотите определить некоторое слово, которое будет представлять такое число снова в виде телефонного номера. Назовем его .ТЕЛЕФОН (для вывода номера телефона) и запишем следующее определение:: .ТЕЛЕФОН ( ud - ) <# # # # # 45 HOLD #S #> TYPE SPACE ;
Ваше определение .ТЕЛЕФОН содержит все компоненты слова UD. и некоторые другие. Слово Форта #(ЧИСЛО) выводит только одну цифру. Определение форматного вывода числа берет цифры выводимого числа в обратном порядке, поэтому выражение «# # # #» выводит четыре крайние правые цифры номера телефона.
Определение в данном случае может выглядеть следующим образом1:: SEXTAL 6 BASE ! ; : :00 ( ud -- ud) # SEXTAL # DECIMAL ASCII : HOLD ; : СЕКУНДЫ <# :00 :00 #S #> TYPE SPACE ;
Для форматного вывода секунд и минут вы используйте слово :00. Как секунды, так и минуты вычисляются по модулю 60, значит, правой цифрой может быть любая цифра до девяти, а левой - цифра от нуля до пяти включительно. Поэтому в своем определении :00 вы преобразуете первую цифру (она является правой) как десятичное число, затем переходите по слову SEXTAL в шестиричную систему (с основанием 6) и преобразуете левую цифру, после чего возвращаетесь в десятичную систему и вставляете символ двоеточия. После того как слово :00 преобразует секунды и минуты, #S переведет оставшиеся часы. Так, если у вас в стеке время задано как 4500 с, то в результате вы получите: 4500. .СЕКУНДЫ 1:15:00 ok
1 Для начинающих. См. полезный прием, описанный на с. 164.
(Если продолжительность дня измерять в секундах, то 86400 с - это слишком много для 16-разрядного числа.)
В табл. 7.2 сведены слова Форта, использующиеся при форматизации чисел. (Обратите внимание на условные обозначения в конце таблицы, которые напоминают вам о смысле символов "n", "d" и т. д.)
Таблица 7.2
Форматирование чисел<# Начало процесса преобразования числа. В стеке должно находиться
число двойной длины без знака # Преобразование одной цифры и помещение ее в выходную символьную строку. # доставляет цифру в ЛЮБОМ СЛУЧАЕ - если вы подали этому слову на вход неверное цифровое значение, то и в этом случае вы получите нуль для каждого # #S Преобразование числа (цифры за цифрой) до тех пор, пока в результате не получится нуль. Всегда доставляется по крайней мере одна цифра (нуль, если число равно нулю) с HOLD Вставка в форматируемую символьную строку на текущую позицию символа, значение которого в коде ASCII находится в стеке n SIGN Вставка знака "-" в выходную строку в том случае, если третье число в стеке отрицательное (это число из стека выбирается - см.
сноску в следующем разделе) #> Завершение преобразования числа и помещение в вершине стека счетчика символов и адреса (именно эти аргументы требуются для TYPE)
ВЫРАЖЕНИЕ СОСТОЯНИЕ СТЕКА ТИП АРГУМЕНТОВ <# ... #> ( d -- а u) или 32-разрядный без знака ( u 0 - а и) 16-разрядный без знака
<# ... ( |d| -- а u) 32-разрядный со знаком, n SIGN #> где |d| является абсолют- или мым значением d, a n - верхней ячейкой d ( |n| 0 -- а u) 16-разрядный со знаком, где |n| - абсолютное значение n
Условные обозначения: n, n1 ... - 16-разрядные числа со знаком; а - адрес; d, d1 ... - 32-разрядные числа со знаком; u, u1 ... - 16-разрядные числа без знака; с - значение символа в коде ASCII.
ФОРТ-АССЕМБЛЕР
Форт часто используют в прикладных областях, где от программ требуется высокая скорость выполнения, например, при обработке сигналов информация поступает в реальное время и компьютер должен справляться с ее обработкой. Как правило, вы существенно выигрываете в скорости, если работаете с Фортом, а не с другими языками программирования, но языку Ассемблера он все же в этом отношении уступает. (Вновь создаваемые Форт-процессоры, такие, как NOVIX NC 4000, непосредственно выполняют команды Форта высокого уровня быстрее, чем традиционные процессоры свои машинные команды. Ассемблер, описанный в данном разделе, имеет смысл только для систем, функционирующих на обычных процессорах.)
В прикладной программе почти все время выполнения приходится лишь на ее небольшую часть, а именно на так называемые внутренние циклы. Если ваша программа, написанная на Форте - языке высокого уровня, работает слишком медленно, вы можете значительно ускорить ее выполнение, переписав один или дйй внутренних цикла на языке Ассемблера.
В большинстве языков высокого уровня нет хороших средств автономного создания программ на ассемблере и соединения их с основной программой. На Форте же это обычный процесс. Определения на ассемблере Форта выглядят почти так же, как и определения высокого уровня. Если тело определения через двоеточие содержит код высокого уровня: : НОВОЕ-ИМЯ ( код высокого уровня . . .) ;
то тело ассемблерного определения включает команды на языке Ассемблера: CODE НОВОЕ-ИМЯ ( код на языке ассемблера . . .) END-CODE
(Слово завершения ассемблерного кода варьируется от системы к системе; Стандарт-83 рекомендует END-CODE.)
Слово, которое определяется посредством CODE, хранится в словаре так же, как и все остальные, и выполняется или вызывается подобно любому другому слову. Определенное соответствующим образом это слово будет выполняться со значениями из стека, поэтому вы можете передавать ему аргументы так, как если бы оно было определено через двоеточие. На самом деле, выполняя некоторое слово, вы не в состоянии установить, определено ли оно через двоеточие или через CODE (разве что по скорости выполнения).
Лучше всего писать программу на языке высокого уровня. После того как она начала правильно работать, вы можете выявить те участки, на выполнение которых тратится основное время и переписать их в машинных кодах. Повторно откомпилируйте программу, и она будет работать намного быстрее. Альтернативный способ - заранее фиксировать критичные по времени участки - не столь эффективен.
Рассмотрим создание конкретного ассемблера на примере ассемблера 8080. Очевидно, что для каждого процессора должен существовать свой ассемблер и что ассемблер 8080 подходит только для данного процессора. Если вы введете в ваш компьютер приведенный здесь пример на ассемблере, то получите сгенерированный машинный код для 8080, что, собственно, вам и требуется. Но попытавшись полученный код выполнить, вы потерпите неудачу. Наш пример показывает, как легко писать на Форт-ассемблере, объясняет основные принципы разработки ассемблера и демонстрирует мощь определяющих слов Форта.
Начнем с определяющего слова CODE. Его назначение - создание заголовка словарной статьи, которая при выполнении передаст управление по адресу, содержащему машинный код. Выполнить это проще, чем понять. Вспомните (см. гл. 9), что все определения снабжены полем кода, которое указывает машинный код. В определении CODE такой указатель должен указывать поле параметров данного определения:
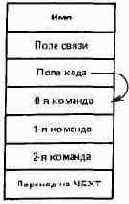
Таким образом, простое определение слова CODE может иметь вид: : CODE CREATE HERE HERE 2- ! ;
Теперь нам нужен набор слов, позволяющий осуществлять трансляцию машинных команд в словарь. Для начала выберем несложное слово. Команда процессора 8080 СМА вычисляет дополнение содержимого регистра А. Код этой операции в двоичной системе счисления выглядит так: 00101111. Чтобы транслировать команду, введем следующее определение:HEX : CMA 2F C, ;
Еще одна простая команда XCHG обеспечивает обмен содержимым между парами регистров D-Е и Н-L. Код такой операции: 11101011. Далее мы можем ввести определение: : XCHG ЕВ С, ;
Подведем предварительные итоги.
Мы задали себе синтаксис написания определений машинных команд и предыдущими действиями создали средства их спецификации. Теперь можно ввести следующий текст:CODE ТЕСТ СМА ХСНG . . .
Получено слово ТЕСТ, выполняющее машинные команды СМА и XCHG. Вы можете для проверки этого слова воспользоваться словом DUMP (но ни в коем случае не инициируйте слово ТЕСТ!).
Как заканчивается CODE-определение, мы покажем позднее, а пока вернемся к определению машинных команд. У нас уже определены две команды, состоящие из восьмиразрядного кода операции. Процессор 8080 имеет довольно много команд такого типа. Поэтому нам необходимо слово для определения всех подобных команд (назовем их командами типа!) 1MI. : 1MI ( код-операции - ) CREATE С, DOES> С@ С, ;
Определим с помощью введенного слова следующие команды (первые два определения по-новому создают уже имеющиеся у нас команды):HEX 2F 1MI СМA ЕВ 1MI XCHG 00 1MI NOP 76 1MI HLT F3 1MI DI FB 1MI EI 07 IMI RLC 0F 1MI RRC 17 1MI RAL 1F IMI RAR Е9 1MI PCHL F9 1MI SPHL E3 1MI XTHL 27 1MI DAA 37 1MI STC 3F 1MI CMC C0 1MI RNZ C8 1MI RZ D0 1MI RNC D8 1MI RC Е0 1MI RPO E8 1MI RPE F0 1MI RP F8 1MI RM C9 1MI RET
Определяющее слово 1MI создает семейство команд, каждую из которых отличает уникальный код операции, но при компиляции все они ведут себя одинаково: их код заносится в словарь. Вновь образованное определение СМА функционально почти не отличается от прежнего определения через двоеточие. Единственное отличие состоит в том, что слово С, заносящее код операции в словарь, находится в части DOES> слова 1MI, а сам код (2F) - в поле параметров слова СМА.
Мы уже определили большую группу команд процессора 8080. Но остальные его команды не так просты. Например, команда ADD дополнительно вносит содержимое заданного регистра в регистр А (сумматор). Для того чтобы на обычном ассемблере 8080 добавить
содержимое регистра В к содержимому регистра А, нужно ввести ADD В
Код операции ADD в двоичной системе имеет вид 10000SSS, где SSS - три бита, используемые для указания задаваемого регистра (S означает источник).
Регистр В задается как 000, отсюда "ADD В" в двоичном коде будет выглядеть следующим образом: 10000000.
Аналогично если регистр L задается как 101 (S), то выражение "ADD L" превратится в 10000101. Иными словами, нужный код операции получается при выполнении команды OR над двоичным значением 10000000 (шестнадцатиричное 80) и числом, обозначающим регистр. Определим операцию ADD так:: ADD ( регистр# - ) 80 OR С, ;
Самый простой способ занесения номера нужного регистра в вершину стека - задать номера регистров в виде констант: 0 CONSTANT В 1 CONSTANT С 2 CONSTANT D 3 CONSTANT E 4 CONSTANT H 5 CONSTANT L 7 CONSTANT A
(Здесь перечислены все регистры, которые можно использовать в команде ADD.) Теперь для занесения в словарь кода операции сложения значений регистра В и сумматора можно написать: В ADD
Постфиксная запись ненамного усложняет дело, но зато ассемблер становится проще и сохраняется свойство расширяемости, присущее Форту (с помощью макроподстановки).
В некоторых командах, аналогичных ADD, значение регистра задается в трех младших битах. Поэтому имеет смысл для данного класса команд специфицировать свое определяющее слово:: 2MI CREATE C, DOES> ( регистр# - ) С@ OR С, ;
С помощью этого слова можно ввести следующие определения:80 2MI ADD 88 2MI ADC 90 2MI SUB 98 2MI SBB А0 2MI ANA AB 2MI XRA В0 2MI ORA B8 2MI CMP
(2MI функционирует аналогично 1MI, т. е. запоминает уникальный код операции определяемой команды (ребенка) в поле параметров последней. Отличие же заключается в том, что 2MI заставляет команду-ребенка при выполнении логически складывать посредством OR код операции ребенка с номером регистра из стека.) Существует еще один класс машинных команд, содержащих номера регистров в коде операции, но в другом месте. Например, код команды 1NR (приращение) имеет вид OODDD100 (шестнадцатиричное число 04), где DDD - регистр, подлежащий приращению (D означает «получатель»). Мы можем воспользоваться константами, обозначающими номера регистров, но при этом необходимо осуществить сдвиг на три бита влево, прежде чем команда OR сложит их с кодом операции (сдвиг на три позиции влево эквивалентен умножению на восемь):: INR ( регистр# -- ) 8 * 04 OR С, ;
Как и в предыдущем случае, введем определяющее слово:: 3MI CREATE С, DOES> ( регистр# -- ) С@ SWAP 8 * OR С, ;
04 3МI INR
Теперь выражение "С INR" занесет в словарь код операции: 00001100.
С помощью слова 3MI можно специфицировать еще один класс команд, в чем вы убедитесь, посмотрев листинг, приведенный в конце раздела.
Для создания команд остальных типов нам достаточно ввести всего два определяющих слова - 4MI и 5М1. Первое применяется для образования кодов тех операций, которые требуют дополнительно восьмиразрядного литерала, например ADI (непосредственное сложение с А). Второе слово определяет коды операций, требующих дополнительно 16-разрядного литерала. В качестве примера можно привести команды CALL, JMP и подобные им. Команды MOV, MVI и LX1 уникальны и поэтому специфицируются индивидуально посредством двоеточия без использования определяющего слова.
Изучая листинг, обратите внимание на то, что в него включены операторы управления, такие, как IF, ELSE,THEN,BEGIN, UNTIL, WHILE и REPEATE. Это не совсем те слова, с определениями которых вы уже познакомились ранее (где передача управления компилируется посредством высокоуровневых слов Форта), а их версии, созданные только для ассемблера, где передача управления и разрешение адресов, как и в традиционном ассемблере, осуществляются на уровне машинных команд. Однако они обеспечивают вам возможность программирования с использованием формата структур высокого уровня.
Но можно ли компилировать в словарь различные варианты слов IF, THEN и т. д., они ведь в нем смешаются? Конечно, так как команды ассемблера хранятся в контекстном словаре ASSEMBLER, а не в словаре FORTH. Определение CODE в нашем листинге инициирует слово ASSEMBLER, что делает этот контекстный словарь текущим всякий раз, когда мы начинаем CODE-определение.
Интересной особенностью Форт-ассемблера является и его расширяемость. Если в вашей программе имеются повторяющиеся фрагменты, то вы можете вместо них использовать макрокоманды. Ниже приводится пример макрокоманды, которая осуществляет «циклический сдвиг содержимого регистра А влево» и затем «добавляет содержимое регистра В»: : SHIFT+ RLC В ADD ;
Заметьте, что, появившись внутри ассемблерного определения, слово SHIFT+ помещает в словарь две команды, составляющие определение этого слова так, как если бы вместо него были введены сами команды: RLC В ADD
Адрес слова SHIFT+ не компилируется, а само оно при выполнении его кода не вызывается в качестве подпрограммы. Использование макросредств во время выполнения не приводит к каким-либо накладным расходам, поскольку машинные команды после макроподстановки в точности такие же, как и без нее.
Слово NEXT представляет собой одну из макрокоманд, написанных на языке Ассемблера. В нашей системе она определена так: : NEXT (NEXT) JMP ;
Иными словами, NEXT - это машинная команда, передающая управление по адресу, который оставляет в вершине стека слово (NEXT). По данному адресу расположен код адресного интерпретатора (о котором речь шла в гл. 9). Адресный интерпретатор является ядром Форта и выполняет поочередно все адреса в скомпилированном Форт-определении. Каждое определение через CODE должно заканчиваться инициированием адресного интерпретатора. Следовательно, любое ассемблерное определение должно завершаться словом NEXT. В нашем ассемблере определения также должны иметь в конце слово END-CODE, которое дополнительно восстанавливает контекст.
Ниже приводятся два примера, где используются команды описанного здесь ассемблера: HEX CODE X ( n -- n') \ Меняются местами старший и младший байты n Н POP L A MOV H L MOV A H MOV H PUSH NEXT END-CODE
(Мы пересылаем п из стека в пару регистров HL, регистр L (младшие байты) в регистр А, регистр Н (старшие байты) в L, а А в Н, помешаем содержимое пары регистров HL в стек, передаем управление NEXT).CODE BP ( a # -- ) \ Перевод из нижнего регистра в верхний D POP H POP BEGIN D A MOV Е ORA 0= NOT WHILE M A MOV 60 CPI CS NOT IF 20 SUI A M MOV THEN D DCX H INX REPEAT NEXT END-CODE
(Пересылаем счетчик в пару регистров DE, а адрес - в пару регистров HL, начинаем цикл, проверяем, выполняя команду OR над содержимым регистров D и Е, не равно ли значение счетчика нулю.
Пока его значение не равно нулю, перемещаем символ из памяти, на которую ссылается указатель, в сумматор. Если код обрабатываемого символа больше 60 (строчная «а» и выше), вычитаем десятичное число 32, преобразуя символ в прописной, и записываем в память. Уменьшаем счетчик и увеличиваем адрес. Повторяем цикл. Передаем управление NEXT).
Преимущество работы на ассемблере такого вида заключается в том, что вы во время ассемблирования «находитесь в Форте». Если вам необходимо идентифицировать некоторое устройство с помощью имени, а не числа, вы можете определить его как обычную константу и присвоить ей имя внутри ассемблерного определения. Можно воспользоваться определением через двоеточие как макрокомандой или даже обратиться к переменной, поскольку она помещает в вершину стека свой адрес и поэтому может быть задействована в команде «непосредственной загрузки». Применение машинных команд раскрывает перед вами всю мощь языка Форт.
В основу описанного здесь ассемблера положен ассемблер 8080, разработанный Дж. Кассэди. Мы внесли в него изменения в соответствии со Стандартом-83 и для простоты изучения убрали некоторые зависимые от системы фрагменты. С оригиналом вы можете познакомиться в [1 ]. Ассемблер для других процессоров описан в [2], [3], [4].\ Ассемблер 8080 \ учебная версия ассемблера 8080,основанная на фигФорте; \ разработана Джоном Кэсседи HEX VOCABULARY ASSEMBLER : CODE CREATE HERE HERE 2- ! ASSEMBLER ; ASSEMBLER DEFINITIONS : END-CODE CURRENT @ CONTEXT ! ; 0 CONSTANT В 1 CONSTANT С 2 CONSTANT D 3 CONSTANT E 4 CONSTANT H 5 CONSTANT L 6 CONSTANT PSW 6 CONSTANT M
6 CONSTANT SP 7 CONSTANT A : 1MI CREATE C, DOES> C@ C, ; : 2MI CREATE C, DOES> C@ OR C, ; : 3MI CREATE C, DOES> С@ SWAP 8 * OR C, ; : 4MI CREATE C, DOES> С@ С, С, ; : 5MI CREATE С, DOES> С@ С, , ;
\ Ассемблер 8080 HEX 00 1MI NOP 76 1MI HLT F3 1MI DI FB 1MI ED 07 1MI RLC 0F 1MI RRC 17 1MI RAL 1F 1MI RAR E9 1MI PCHL F9 1MI SPHL E3 1MI XTHL EB 1MI XCHG 27 1MI DAA 2F 1MI CMA 37 1MI STC 3F 1MI CMC 80 2MI ADD 88 2MI ADC 90 2MI SUB 98 2MI SВВ А0 2MI ANA A8 2MI XRA B0 2MI ORA B8 2MI CMP B9 3MI DAD C1 3MI POP C3 3MI PUSH B2 3MI STAX 0А 3MI LDAX 04 3MI INR 05 3MI DCR 03 3MI INX 0B 3MI DCX C7 3MI RST D3 4MI OUT DB 4MI SBI E6 4MI ANI ЕЕ 4MI XRI F6 4MI ORI FE 4MI CPI 22 5MI SHLD 2A 5MI LHLD 32 5MI STA 3А 5МI LDA CD 5MI CALL
\ Ассемблер 8880 HEX C9 1MI RET C3 5MI JMP C2 CONSTANT 0= D2 CONSTANT CS E2 CONSTANT PE F2 CONSTANT 0< : NOT 8 OR ; : MOV 8 * 40 + + C, ; : MVI 8 * 6 + C, C, ; : LXI 8 * 1+ C, , ; : THEN HERE SWAP ! ; : IF C, HERE 0, ; : ELSE C3 IF SWAP THEN ; : BEGIN HERE ; : UNTIL C, , ; : WHILE IF ; : REPEAT SWAP JMP THEN ; : NEXT (NEXT) JMP ;
ГЕОГРАФИЯ ФОРТА
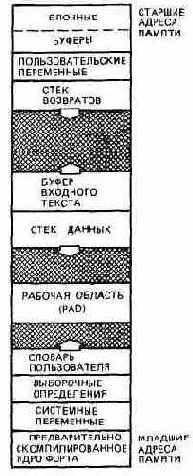 | Вы видите на рисунке карту памяти1 типичной Форт-системы для одного пользователя. Мультипрограммные системы, такие, как полиФорт, устроены намного сложнее, о чем пойдет речь позднее. А пока рассмотрим простой случай и последовательно изучим каждый район нашей карты.
Предварительно скомпилированное ядро Форта. В памяти с младшими адресами расположен единственный предварительно скомпилированный участок системы (уже скомпилированный в словарную форму). В одних системах коды этого участка хранятся на диске (как правило, блоки 1-8) и автоматически загружаются в память с произвольной выборкой во время запуска или восстановления вашего компьютера, в других - такой участок неизменно находится в программируемой постоянной памяти и становится доступным сразу, как только вы включаете компьютер. В предварительно скомпилированном участке обычно хранится большая часть математических операций и слов форматизации чисел одинарной длины, операции преобразования стека одинарной длины, команды редактирования, структуры управления, ассемблер, все определяющие слова, которые вам уже известны, и, конечно, интерпретаторы текста и адреса2. |
1Для начинающих. Здесь показано, каким образом распределяется намять компьютера в конкретной системе в зависимости от ее назначения Память разбита на участки по 1024 байта. Это число называется «К» (от слова «кило», означающего тысячу).
2 Для специалистов. Чтобы получить представление о том, как компактен Форт, вам достаточно знать, что весь предварительно скомпилированный участок полифорта занимает меньше 8К байтов памяти
Системные переменные. Следующий раздел памяти содержит системные переменные, которые созданы предварительно скомпилированным ядром Форта и используются всей системой. Они, как правило, не применяются пользователем.
Выборочные определения. Тот раздел Форт-системы, который не был предварительно скомпилирован, хранится на диске в виде исходного текста. Какую часть определений из этого раздела загружать, а какую - нет, вы можете решить сами, что улучшит управление использованием памяти вашего компьютера.
Блок загрузки для всех выборочных определений называется блоком выбора.
Словарь пользователя. Словарь расширяется в сторону увеличения адресов памяти по мере того, как вы добавляете ваши собственные определения в область памяти, называемую словарем пользователя. Его следующая доступная ячейка в любой момент времени определяется содержимым переменной с именем Н (или DP). Во время компиляции указатель Н, по мере того как очередной элемент добавляется к словарю, переходит с ячейки на ячейку (или с байта на байт). Таким образом, для компилятора указатель Н выступает в качестве закладки; он указывает то место в словаре, куда компилятор может компилировать следующий объект. Этот указатель также используется словом ALLOT, которое передвигает его на заданное число байтов. Например, выражение 10 ALLOT добавляет к нему 10 и, следовательно, компилятор зарезервирует память в словаре для массива, состоящего из 10 байтов (или пяти ячеек).
Родственным словом является и HERE, которое определяется весьма просто: : HERE ( -- текущий-адрес ) H @ ;
Оно помещает значение Н в стек. Слово , (запятая) помещает значение одинарной длины в следующую доступную ячейку словаря: : , ( n -- ) HERE ! 2 ALLOT ;
т. е. запоминает некоторое значение в HERE и продвигает указатель словаря на два байта, закрепляя память под это значение. С помощью HERE вы можете определить, какой объем памяти требуется для любого фрагмента вашей программы, для чего нужно сравнить HERE до компиляции и после нее. Например, выражение HERE 220 LOAD HERE SWAP - . 196 ok
показывает, что определения, загруженные блоком 220, заняли 196 байтов памяти словаря.
Рабочая область (PAD). На некотором удалении от HERE вы обнаружите в своем словаре небольшую область памяти, называемую рабочей областью. Наша рабочая область обычно служит для хранения строк символов в коде ASCII, которые подвергаются обработке перед выводом на терминал. Так, слова, осуществляющие форматирование чисел, используют рабочую область для обработки чисел в коде ASCII во время их перевода, прежде чем вывести эти числа с помощью TYPE,
Размер рабочей области не определен.
В большинстве систем расстояние между началом рабочей области и вершиной стека данных измеряется сотнями и даже тысячами байтов.
Поскольку адрес начала рабочей области определяется относительно последнего элемента словаря, он изменяется всякий раз при добавлении нового определения либо выполнении FORGET или EMPTY.
Подобная организация тем не менее гарантирует безопасность, так как рабочая область никогда не используется при выполнении перечисленных выше действий. Слово PAD вносит в вершину стека текущий адрес начала рабочей области. Оно имеет довольно простое определение:: PAD ( -- a) HERE 34 + ;
т.е. помещает в стек адрес, который отстоит на фиксированное число байтов от HERE (в действительности это число может меняться).
Стек данных. Намного выше рабочей области расположен участок, зарезервированный под стек данных. У вас может создаться впечатление, что значения где-то передвигаются вверх и вниз, как будто их кто-то «вталкивает» и «выталкивает», однако на самом деле ничего подобного не происходит. Единственное, что изменяется, - это указатель вершины стека.
Как вы увидите в дальнейшем, при занесении некоторого числа в стек фактически лишь уменьшается указатель (т. е. указывает на следующий участок в направлении к младшим адресам памяти), а затем число запоминается в том месте, куда показывает указатель. Когда вы удаляете число из стека, оно выбирается из участка, на который показывает указатель, после чего последний увеличивается.
Все числа, расположенные на карте памяти выше указателя стека, не имеют смысла.
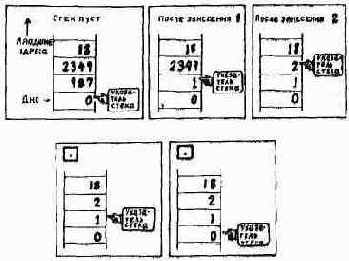
Но мере добавления в стек новых значений он «растет» в направлении младших адресов памяти.
Указатель стека выбирается посредством слова SP@1. Так как это слово доставляет адрес самого верхнего участка стека, выражение SP@ выбирает содержимое вершины стека. Такая операция, конечно, идентична операции DUP. Если у вас в стеке находится пять значений, то пятое значение можно скопировать с помощью выражения: SP@ 8 + @
(но в большинстве случаев это не может считаться хорошим стилем программирования).
На дно стека указывает переменная S0. Она всегда содержит адрес ячейки, расположенной непосредственно под ячейкой, соответствующей «пустому» стеку.
Заметим, что при размещении чисел двойной длины как в стеке, так и в словаре старшая по порядку ячейка размещается по
1 Для пользователей систем полифорта Это слово имеет имя 'S
младшему адресу. При выполнении операций 2! и 2@ (см. рисунок). Этот порядок размещения ячеек сохраняется.
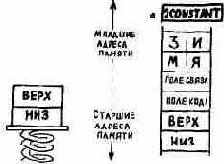
Буфер входного текста. Буфер входного текста представляет собой область памяти длиной, как правило, 80 байт, куда поступают вводимые с клавиатуры символы после нажатия клавиши «возврат каретки». Именно здесь они будут просмотрены текстовым интерпретатором.
Не путайте этот термин с термином входной поток (см. гл. 3), который означает последовательность слов, подлежащих интерпретации. Данная последовательность может быть расположена либо в буфере входного текста (в режиме интерпретации), либо в блоке, содержащем исходный текст (в режиме загрузки).
Буфер входного текста увеличивается в направлении старших адресов памяти (в том же направлении, что и рабочая область (PAD)). Слово TIB выбирает начальный адрес буфера. (На фиг-Форте вы можете ввести "TIB @", на полиФорте - "S0 @".)
Стек возвратов. Выше буфера входного текста расположен стек возвратов, функционирование которого идентично функционированию стека данных.
Пользовательские переменные. Следующий раздел памяти содержит пользовательские переменные. Эти переменные включают в себя слова BASE, S0 и многие другие, которые мы рассмотрели ниже.
Блочные буферы. В самой верхней области памяти расположены буферы блоков. Каждый буфер имеет объем 1024 байта для размещения содержимого дискового блока. Всякий раз, когда вы осуществляете доступ к какому-либо блоку (например, распечатывая или загружая его), система копирует данный блок с диска в такой буфер, где он может изменяться с помощью редактора или интерпретироваться посредством слова LOAD.
Более подробно мы обсудим блочные буферы в гл. 10.
На этом наше путешествие по карте памяти типичной Форт-системы индивидуального пользования завершается. Далее приводится перечень уже знакомых вам слов, которые используются при работе с различными участками памяти.
|
Н или DP |
( -- а) |
Занесение в стек адреса указателя словаря. |
|
HERE |
( -- а) |
Занесение в стек адреса очередного доступного участка словаря. |
|
PAD |
( -- а) |
Занесение в стек адреса начала рабочей области, в которой хранятся строки символов в процессе промежуточной обработки. |
|
SP@ или 'S |
( -- а) |
Занесение в стек адреса вершины стека данных до того, как исполнено само слово SP@. |
|
S0 |
( -- а) |
Содержит адрес дна стека данных. |
|
TIB |
( -- a) |
Занесение в стек адреса начала буфера входного текста. |
ОСНОВЫ ФОРТА
В настоящей главе вы познакомитесь с некоторыми особенностями Форта. Прочитав несколько вводных страниц, вы уже сможете сесть за терминал. Если же у вас нет терминала, не огорчайтесь — в процессе изложения мы шаг за шагом будем выдавать вам результат.
ОПЕРАЦИИ НАД ЦЕЛЫМИ ЧИСЛАМИ
В этой главе мы введем несколько новых арифметических операций и в процессе изложения решим задачу по управлению положением десятичной точки, используя только целочисленную арифметику.
ЦИКЛИЧЕСКИЕ СТРУКТУРЫ
В гл. 4 мы обсуждали вопрос о том, как нужно составлять программы, чтобы компьютер «принимал решения», выбирая одну из альтернатив определения в зависимости от результата проверки конкретного условия. Условный переход является одним из тех достоинств, которые делают компьютер незаменимым.
Теперь вы должны научиться писать определения, позволяющие повторять тот или иной фрагмент несколько раз в зависимости от заданных условий. Такой вид структуры управления называется циклом. Способность выполнять циклы — это второе и, вероятно, наиболее важное достоинство компьютеров. Если вы можете составить программу проверки одной платежной ведомости, то вы можете составить программу проверки и тысячи подобных ведомостей.
В настоящей главе мы рассмотрим циклы, в которых выполняются простые действия, например вывод чисел на вашем терминале,
ЧИСЛО ТИПОВ ЧИСЕЛ
До сих пор речь шла только о числах одинарной длины со знаком. В настоящей главе мы введем числа без знака и числа двойной длины и познакомим вас с новыми операциями над этими числами.
Излагаемый здесь материал разделен на две части. В первой части (для начинающих) рассматриваются числа применительно к компьютеру, а также дается точное определение терминов со знаков без знака, одинарная длина, двойная длина, во второй (для всех) продолжается обсуждение Форта и объясняется, как трактуются числа со знаком и без знака, одинарной и двойной длины (точности).
ПЕРЕМЕННЫЕ, КОНСТАНТЫ И МАССИВЫ
Из материала семи предыдущих глав вы уже поняли, что программирующие на Форте используют стек для передачи аргументов от одного слова к другому. Если программистам требуется хранить числа более продолжительное время, они применяют переменные и константы. В этой главе будет показано, как Форт-система трактует переменные и константы и каким образом можно непосредственно получить доступ к участку памяти.
ФУНКЦИОНИРОВАНИЕ ФОРТ-СИСТЕМЫ
В этой главе мы приоткроем «щелочку» и заглянем внутрь Форт-системы. Некоторое представление о том, что там (внутри) происходит, вы уже получили ранее, но, рискуя повториться, мы приведем здесь описание Форт-машины в целом, чтобы вы поняли, как все ее механизмы взаимодействуют друг с другом.
ВВОД-ВЫВОД
В настоящей главе мы объясним вам, как Форт-система управляет вводом-выводом, как текст поступает с клавиатуры и выводится на экран дисплея, как данные записываются во внешнюю память и считываются из нее. Особое внимание будет уделено командам доступа к дискам, вывода, работы со строками, ввода и преобразования вводимых чисел.
РАСШИРЕНИЕ КОМПИЛЯТОРА: ОПРЕДЕЛЯЮЩИЕ И КОМПИЛИРУЮЩИЕ СЛОВА
В этой главе мы переходим на следующую ступень изучения Форта. В предыдущих главах рассматривались такие его свойства, которые могут быть присущи любому языку программирования. Вы познакомились с арифметическими операциями, управляющими структурами, структурами данных, вводом-выводом, внешней памятью и т. д. Даже двоеточие имеет аналогии во многих языках в виде процедурного аппарата. Здесь же вы столкнетесь с совершенно иным уровнем возможностей языка: вы научитесь расширять сам компилятор с Форта. Создание новых определяющих и компилирующих слов служит основой для разработки исключительно читабельных, легко сопровождаемых программ и, вероятно, представляет собой самое значительное из средств Форта.
ТРИ С ПОЛОВИНОЙ ПРИМЕРА
Программирование на Форте в большой мере, чем на любом другом языке, является искусством. Форт подобен кисти художника - этот язык предоставляет программисту средства, позволяющие ему полностью контролировать свои действия. По словам Ч. Мура, хороший программист с помощью Форта может выполнить работу блестяще, плохой - загубить дело. Программист должен чувствовать «стиль» Форта. Предлагаем вашему вниманию некоторые элементы хорошего стиля программирования на Форте:
простота; предпочтение большого числа коротких определений небольшому числу длинных; соответствие между названиями слов и описываемыми или легко воспринимаемыми действиями или структурами данных; правильный выбор имен; удачное разбиение программы на блоки и понятный комментарий.
Неплохим методом освоения стиля программирования на Форте, свободным от проб и ошибок, представляется разбор существующих программ, написанных на Форте, в том числе и самой Форт-системы. Мы включили в книгу определения многих слов Форт-системы и рекомендуем вам продолжить ее изучение самостоятельно.
В настоящей главе будут рассмотрены три примера. В первом примере показано использование хорошо выделенных определений и создание специализированного прикладного «языка». Второй пример иллюстрирует способ преобразования математического выражения в определение на Форте. Вы увидите, как с помощью арифметических операций над числами с фиксированной точкой можно увеличить скорость выполнения программ и уменьшить их объем. В третьем примере речь идет о применении конструкций ассемблера Форта и демонстрируется мощь определяющих слов. И наконец, без всяких пояснений мы предоставим вам возможность научиться разбираться в тексте программ, написанных на Форте.
ИНИЦИАЛИЗАЦИЯ МАССИВА
Во многих ситуациях требуется массив со значениями, которые во время выполнения прикладной программы никогда не меняются и могут быть загружены в этот массив во время его создания по аналогии с константами, создаваемыми с помощью CONSTANT Для осуществления этих действий в Форте предусмотрено слово , (ЗАПЯТАЯ).
Предположим, вы хотите, чтобы значения массива ПРЕДЕЛЫ были постоянными. Тогда вместо выражения VARIABLE ПРЕДЕЛЫ 8 ALLOT
необходимо ввестиCREATE ПРЕДЕЛЫ 220 , 340 , 170 , 100 , 190 ,
Как правило, приведенная выше строка должна вводиться из дискового блока, но ее можно вводить и непосредственно с экрана.
Напоминаем вам, что слово CREATE во время компиляции вносит новое имя в словарь, а во время выполнения доставляет адрес своего определения. Но оно не «выделяет» какое-то число байтов под значение.
Слово , берет число из стека и помещает его в массив. Поэтому всякий раз, когда вы записываете число и ставите за ним запятую, вы добавляете к массиву одну ячейку1.
1 Для начинающих. Укоренившиеся привычки грамотно писать фразы на естественном языке приводят к тому, что некоторые новички забывают написать последнюю запятую в строке. Помните, что «,» не разделяет числа, а компилирует их

Доступ к элементам массива, созданного с помощью CREATE, обеспечивается точно так же, как и к элементам массива, созданного посредством VARIABLE, например: ПРЕДЕЛЫ 2+ ? 340 ok
Вы даже можете помещать в этот массив новые значения так, как если бы работали с массивом, созданным с помощью VARIABLE, но только в том случае, кода вы не собираетесь пропустить свою прикладную программу через целевой компилятор.
Для того чтобы сформировать массив байтов, можно воспользоваться С,. Например, мы могли бы загрузить каждое из значений в нашем определении слова КАТЕГОРИЯ при сортировке яиц, следующим образом- CREATE РАЗМЕРЫ 18 С, 21 С, 24 С, 27 С, 30 С, 255 С,
Это позволило бы переопределить слово КАТЕГОРИЯ посредством оператора цикла DO, а не рядом вложенных операторов IF ...
THEN, в частности':
1 Для тех, кто не любит докапываться до сути самостоятельно. Суть дела состоит в следующем. Так как у нас пять возможных категорий, можно использовать номер категории как индекс для цикла При выполнении каждого шага цикла мы сравниваем число из стека с элементом массива РАЗМЕРЫ, отстоящим от начала массива на смещение, равное текущему индексу цикла. Как только вес в стеке превысит значение очередного элемента массива, мы завершим цикл и с помощью I определим, сколько раз цикл выполнялся до того, как мы вышли из него Поскольку это число представляет собой смещение в нашем массиве, то оно также является и номером категории
: КАТЕГОРИЯ t вес-ма.~дм*иму -- иенер-категории } 6 0 DO DUP РАЗМЕРЫ I + С@ < IF DROP I LEAVE THEN LOOP ;
Заметьте, что мы добавили к массиву максимальное значение (255), что дает возможность упростить наше определение для категории 5
Этот новый вариант более изящен и более компактен по сравнению с прежним.
Ниже приводится перечень слов Форта, с которыми вы познакомились в данной главе. VARIABLE ххх ( -- ) Создание переменной с именем ххх. ххх ( -- а) Слово ххх при выполнении помещает в стек свой адрес. ! ( n а --) Запоминание числа одинарной длины по заданному адресу. @ ( a -- n) Замещение адреса его содержимым. ? ( а --) Вывод значения по заданному адресу с последующим пробелом. +! ( n а --) Сложение числа одинарной длины с содержимым заданного адреса.
CREATE xxx ( -- ) Создание заголовка в словаре с именем xxx. xxx: ( -- a) Слово xxx при выполнении заносит в стек свой адрес
ALLOT ( n -- ) Резервирование в поле параметров слова, определенного последним, n дополнительных байт.
С! ( b a -- ) Занесение 8-разрядного числа по заданному адресу. С@ ( а -- b ) Выборка 8-разрядного числа по заданному адресу.
FILL (ЗАПОЛНИТЬ) ( a u b -- ) Заполнение n байтов памяти, начиная с заданного адреса, значением Ь.
ERASE (ОЧИСТИТЬ) ( а n -- ) Заполнение n байтов памяти, начиная с заданного адреса, нулями.
CONSTANT xxx ( n -- ) Создание константы с именем xxx и xxx: ( -- n) значением n.Слово xxx при своем выполнении заносит в стек n. FALSE ( -- f) Занесение в стек логического значения ложь ( 0 ). TRUE ( -- t) Занесение в стек логического значения истина ( —1 ).
Операции двойной длины:
2VARIABLE xxx ( -- ) Создание переменной двойной длины ххх: ( -- a) с именем ххх. Слово ххх при выполнении помещает на стек свой адрес. 2CONSTANT ххх ( d -- ) Создает константу двойной длины с именем ххх и значением d. ххх: ( -- d) Слово ххх при выполнении помещает в стек значение d. 2! ( d а -- ) Запоминание числа двойной длины по заданному адресу. 2@ ( а -- d) Занесение в стек числа двойной длины, расположенного по заданному адресу.
Условные обозначения:
n, n1 ... - 16-разрядные числа со знаком; а - адрес; d, d1 ... - 32-разрядные числа со знаком; u, u1 ... - 16-разрядные числа без знака;
ИНСТРУМЕНТАЛЬНЫЕ СРЕДСТВА РАБОТЫ С БЛОКАМИ
Мы знаем, что слово LIST инициирует печать только одного блока. Введем несколько слов, имеющихся в большинстве Форт-систем, для вывода группы блоков и для доступа к блокам.
Слово TRIAD выводит группу из трех смежных блоков, начиная с блока, номер которого делится на три без остатка. Например,
выражение 30 TRIAD
обеспечит вывод блоков с номерами 30, 31 и 32. (Обращение к TRIAD с аргументами 31 и 32 приведет к выдаче той же самой триады блоков.)
Слово SHOW выводит группу блоков со смежными номерами. Например, выражение 30 38 SHOW
приведет к выводу трех триад блоков, начинающихся с номеров 30, 33 и 36 соответственно.
Эти слова применяются для вывода листингов прикладных программ на печатающее устройство. Каким образом осуществляется вывод? К сожалению, все Форт-системы реализуют его по-разному. Перед работой вы должны ознакомиться с документацией по своей системе. Можем предложить в качестве типовых примеров следующие выражения:
В мультизадачной системе, как правило, вы должны ввести
PRINT 17 TRIAD
Слово PRINT (ПЕЧАТЬ) передает остаток строки, содержащей эту команду, задаче вывода на печатающее устройство, а выполнение терминальной задачи продолжается обычным путем.
В однозадачных системах указанные выше слова переназначают вывод на периферийные устройства (не задачи). В подобной системе вы можете ввести такое выражение:
PRINTER 17 LIST CONSOLE
В результате вывод назначается на печатающее устройство, блок распечатывается, после чего вывод снова назначается на дисплей. Вы можете промоделировать синтаксис, принятый в мультизадачной системе, следующим образом: : PRINT PRINTER INTERPRET CONSOLE ;
В ряде систем слово SHOW автоматически назначает вывод на печатающее устройство, а после завершения вывода возвращает назначение на дисплей.
Еще одним важным словом является INDEX (КАТАЛОГ), которое распечатывает в блоках из заданного диапазона только строки комментария (нулевые). Например, выражение 30 38 INDEX
инициирует вывод комментария, содержащегося в блоках с 30-го по 38-й включительно.
Ниже приводится список рассмотренных нами команд.
Если вы еще не знакомы с редактором Форта, то, пожалуй, настало время с ним познакомиться. Возможно, что редактор, имеющийся в вашей системе, отличается от описываемого далее. В этом случае пропустите оставшуюся часть главы и изучите его по документации к своей системе.THRU ( нач кон — ) Загрузка всех блоков с номерами из диапазона от нач до кон
.( текст) ( — ) Вывод текста сообщения, ограниченного правой круглой скобкой. Используется, как правило, за пределами определения через двоеточие.
TRIAD ( n — ) Вывод трех блоков с номерами, включающими n, начиная с номера, делящегося без остатка на 3.
SHOW ( нач кон — ) Вывод блоков с номерами из диапазона от нач до кон по три блока.
INDEX ( нам кон — ) Вывод комментария только для блоков, номера которых входят в диапазон от нач до кон.
ИСПОЛЬЗОВАНИЕ ЧИСЕЛ В ОПРЕДЕЛЕНИЯХ
Если в определении содержится число, например, : БОЛЬШЕ-НА-ДВАДЦАТЬ ( n - n+20) 20 + ;
то это число компилируется в словарь в двоичной форме точно также, как оно выглядит в стеке.

Двоичное значение числа зависит от системы счисления, которая существует в системе на момент компиляции данного определения. Например, при вводе HEX : БОЛЬШЕ-НА-ДВАДЦАТЬ ( n -- n+20) 14 + ; DECIMAL
словарное определение должно содержать шестнадцатиричное значение 14, что соответствует десятичному значению 20(16 + 4). Впредь слово НЕСКОЛЬКО-БОЛЬШЕ будет всегда добавлять к содержимому стека эквивалент десятичного числа 20, независимо от текущей системы счисления. В том случае, когда вы поместите слово HEX внутрь определения, основание системы счисления будет изменяться при выполнении данного определения. Например, если вы определяете: DECIMAL : ПРИМЕР HEX 20 . DECIMAL ;
то число компилируется как двоичный эквивалент десятичного числа 20, поскольку во время компиляции текущей была DECIMAL (десятичная) система счисления. Во время выполнения произойдет следующее: ПРИМЕР 14 ok
Наше число выдается в шестнадцатиричной системе.
Заметьте, что число, помещенное внутри некоторого определения, называется литералом. (В отличие от слов, присутствующих в этом определении, которые ссылаются на другие определения, значение числа заключено в самом числе.)
Ниже приводится перечень слов Форта, рассмотренных в настоящей главе. U. ( u -- ) Вывод числа одинарной длины без знака с одним пробелом после него.
U.R ( u ширина -- ) Вывод числа без знака. Число выровнено по правой границе поля заданной ширины.
U< ( u1 u2 -- ? ) Помещение на стек истины в том случае, если u1<u2. Оба аргумента рассматриваются как числа одинарной длины без знака.
Стековая нотация для форматирования чисел:
ВЫРАЖЕНИЕ СОСТОЯНИЕ СТЕКА ТИП АРГУМЕНТОВ <# ... #> ( d -- а u) или 32-разрядный без знака ( u 0 - а и) 16-разрядный без знака
<# ... ( |d| -- а u) 32-разрядный со знаком, n SIGN #> где |d| является абсолют- или мым значением d, a n - верхней ячейкой d ( |n| 0 -- а u) 16-разрядный со знаком, где |n| - абсолютное значение n
Операции над числами двойной длины:
D+ ( dl d2 -- d-сумма) Сложение двух 32-разрядных чисел.
D- ( dl d2 -- d-разность) Вычитание одного 32-разрядного числа ив другого (dl-d2).
DNEGATE ( d -- -d) Изменение знака 32-разрядного числа на противоположный.
DABS ( d1 -- |d|) Занесение в стек абсолютного значения 32-разрядного числа.
DMAX ( d1 d2 -- d-max) Занесение в стек максимального из двух 32-разрядных чисел.
DMIN ( d1 d2 -- d-min) Занесение в стек минимального из двух 32-разрядных чисел.
D= ( d1 d2 -- ?) Занесение в стек истины в случае равенства d1 и d2.
D0= ( d -- ?) Занесение в стек истины, если d равно нулю.
D< ( d1 d2 -- ?) Занесение в стек истины, если dl меньше d2.
DU< ( ud1 ud2 -- ?) Занесение в стек истины, если ud1 меньше ud2. Оба числа без знака.
D.R ( d ширина -- ) Вывод 32-разрядного числа со знаком. Число выравнивается справа внутри поля заданной ширины.
Смешанные операции:
UM* ( ul u2 -- ud) Перемножение двух 16-разрядных чисел. Все значения без знака. (В предыдущих версиях данная операция называлась U*)
UM/MOD ( ud u1 -- u2 u3) Деление 32-разрядного числа на 16-разрядное. В стек заносятся 16-разрядные остаток и частное ( честное в вершину). Частное округлено до ближайшего меньшего целого! Все значения без знака. (В предыдущих версиях данная операция называлась U/MOD).
M* ( n1 n2 -- d- Перемножение двух 16-разрядных чи- произведение) сел. Все знамени» со знаком.
М+ ( d n -- d-сумма) Сложение 32-разрядного и 16-раэрядного чисел. Результат 32-разрядный.
М/ ( d n -- n-частное) Деление 32-разрядного числа на 16-разрядное. Результат 16-разрядный. Все значения со знаком.
М*/ ( d n u -- d) Умножение 32-разрядного на 16-разрядное и деление промежуточного результата тройной длины на 16-разрядное число (d*n/u). Результат 32-разрядный.
Условные обозначения:
n, n1 ... - 16-разрядные числа со знаком; а - адрес; d, d1 ... - 32-разрядные числа со знаком; u, u1 ... - 16-разрядные числа без знака; с - значение символа в коде ASCII.
ИСПОЛЬЗОВАНИЕ ДИСКОВОЙ ПАМЯТИ
Почти все Форт-системы используют дисковую память. Чтобы понять, что такое дисковая память, ее можно сравнить с оперативной памятью (ЗУПВ — запоминающее устройство с произвольной выборкой). Они различаются между собой примерно так же, как стационарная картотека (шкаф) и вращающаяся. До сих пор вы имели дело с памятью компьютера, которая подобна вращающейся картотеке. Компьютер может получить доступ к этой памяти почти мгновенно, поэтому программы, хранимые в ОЗУ, выполняются очень быстро. К сожалению, объем такой памяти ограничен и ее использование обходится относительно дорого. Кроме того, при выключении компьютера содержимое памяти теряется.

С другой стороны, диск называют устройством с большим объемом памяти, так как аналогично шкафу с картотекой он может хранить значительный объем информации при меньших затратах на единицу данных, чем оперативная память компьютера. Как и магнитная лента, диск сохраняет информацию при отключении питания.
Когда вы определяете некоторое слово, компилятор помещает определение этого слова в ЗУПВ, чтобы доступ к нему осуществлялся достаточно быстро. Постоянным же местом хранения исходного текста данного определения является диск. Вы можете средствами Форта записать ваш исходный текст на диске, а впоследствии считывать его с диска и передавать для обработки текстовому интерпретатору1.
Дисковая память Форт-системы подразделяется на так называемые блоки. Храниться на диске в виде блоков может любая информация. Существует соглашение, по которому блоки, содержащие исходный текст, вмещают 1024 символа и состоят из 16 строк по 64 символа каждая, что согласуется с размерами экрана вашего компьютера. (В некоторых случаях для обозначения блока с исходным текстом применяется термин экран. Для простоты мы будем пользоваться только термином блок.}
Блок с исходным текстом выглядит следующим образом: Block 50 0 ( Большая буква "F" ) 1 : STAR 42 EMIT ; 2 : STARS ( Количество ) 0 DO STAR LOOP ; 3 : MARGIN CR 30 SPACES ; 4 : BLIP MARGIN STAR ; 5 : BAR MARGIN 5 STARS ; 6 : F BAR BLIP BAR BLIP BLIP CR ; 7 8 9 F 10 11 12 13 14 15
Верхняя строка (Block 50) и числа слева от текста на диске отсутствуют. Они выводятся словом LIST, чтобы вам было легче ориентироваться. Для того чтобы вывести требуемой блок, наберите номер этого блока и слово LIST (РАСПЕЧАТАТЬ), например: 50 LIST
1 Для начинающих. Диск иногда используют для хранения самой Форт-системы. Когда вы активируете, или загружаете, Форт, это, как правило, означает его копирование из некоторого участка дисковой памяти в ЗУПВ, где он представляется в виде словаря. (В других системах Форт хранится в постоянной памяти, предназначенной только для чтения из нее (ПЗУ). Здесь он становится доступным сразу после включения питания.)
Как ввести.в блок исходный текст? Для этого существует редактор. Поскольку каждая Форт-система снабжена собственным редактором, за разъяснениями обращайтесь к документации по вашей системе. (Один из таких редакторов описан во второй части настоящей главы.)
Для простоты предположим, что блок 50 содержит определения, рассмотренные выше. Почти все они вам знакомы: это определения, которые вы использовали для вывода на дисплей большой буквы F. Теперь, имея данные определения в блоке, как передать блок 50 текстовому интерпретатору? С помощью выражения 50 LOAD
Слово LOAD (ЗАГРУЗИТЬ) передает указанный блок текстовому интерпретатору, что приводит к компиляции всех находящихся в блоке определений.
После загрузки определений вы можете набрать новое слово F и получить ожидаемый результат. Но заметьте, что мы уже поместили наше новое слово в строку 9 для того, чтобы показать, что при загрузке блока выполняется его содержимое. При загрузке именно этого блока не только производится компиляция определений, составляющих слово F, но и само слово F будет выполнено и вы увидите букву F на вашем экране.
Как уже отмечалось, текстовый интерпретатор сканирует входной поток. Ранее мы считали, что входным потоком является строка, вводимая с клавиатуры. Теперь вам известно, что можно переключать источник входного потока. Как правило, входной поток поступает с клавиатуры дисплея; когда же вы применяете слово LOAD, входной поток поступает с диска.
Итак, у входного потока два источника: непосредственно клавиатура или диск.
В гл. 10 мы более подробно обсудим использование Форт-системой дисковой памяти. Но прежде чем вы приступите к редактированию исходного текста, введем еще одну команду. Слово FLUSH (ВЫБРОС) гарантирует, что все изменения, которые вы пытались внести в некоторый блок, действительно были записаны на диск.
Когда вы редактируете конкретный блок, любое вносимое вами исправление не поступает на диск немедленно. На самом деле вы работаете с некоторой копией этого блока, расположенного в каком-то участке ЗУПВ. В конечном итоге по завершении ваших исправлений Форт-система возвратит откорректированную копию блока на диск. Но представьте себе, что вы отключили компьютер до того, как тот вернул копию блока на диск. Или, предположим, вы сменили диски. Кроме того, в результате допущенной вами программной ошибки вы могли до переноса Фортом ваших исправлений на диск просто испортить систему.
По крайней мере до тех пор, пока вы не прочитаете гл. 10, прежде чем снять диск, отключить питание или предпринять что-нибудь опасное, обязательно введите слово FLUSH1.
Ниже приводится перечень команд, введенных в данном разделе.FORSET имя ( -- ) С помощью этого слова мы забываем ( удаляем из словаря ) указанное слово и все слова, внесенные в словарь после него. LIST ( n -- ) Вывод на экран дискового блока. LOAD ( n -- ) Загрузка дискового блока ( компиляция или выполнение ). Блок 0 обычно загружен быть не может. FLUSH ( -- ) Запись всех обновленных дисковых буферов на диск, после чего освобождение этих буферов.
ИСПОЛЬЗОВАНИЕ МАССИВА СЧЕТЧИКОВ
Вернемся на нашу птицеферму. Приведем еще один пример на использование массива. Каждый его элемент служит как бы отдельным счетчиком. Следовательно, мы можем дифференцирование вести подсчет числа коробок «очень крупных» яиц, «крупных» яиц и т. д., упакованных машиной.
Вспомните, что в приведенном выше определении РАЗМЕР-ЯИЦ (см. гл. 4) у нас было четыре категории стандартных яиц и две категории нестандартных. 0 БРАК 1 МЕЛКИЕ 2 СРЕДНИЕ 3 КРУПНЫЕ 4 ОЧЕНЬ КРУПНЫЕ 5 ОШИБКА
Давайте создадим массив из шести ячеек: CREATE СЧЕТЧИКИ 12 ALLOT
Счетчики будут увеличиваться с помощью слова +!, так что мы должны иметь средства «обнуления» всех элементов массива перед началом процесса подсчета. Выражение СЧЕТЧИКИ 12 0 FILL
заполняет нулями 12 байтов, начиная с адреса СЧЕТЧИКИ. Если в вашей Форт-системе имеется слово ERASE, то в данной ситуации лучше воспользоваться им. Это слово заполняет заданное число байтов нулями. Ниже показан пример его использования. СЧЕТЧИКИ 12 ERASE
FILL (ЗАПОЛНИТЬ) ( a u b -- ) Заполнение n байтов памяти, начиная с заданного адреса, значением Ь.
ERASE (ОЧИСТИТЬ) ( а n -- ) Заполнение n байтов памяти, начиная с заданного адреса, нулями.
Иногда удобно помещать это выражение внутрь определения: : УСТАНОВИТЬ СЧЕТЧИКИ 12 ERASE ;
Далее определим слово, которое по заданному номеру категории яиц (от 0 до 5) даст нам адрес одного из счетчиков, например: : СЧЕТЧИК ( номер-категории -- а) 2* СЧЕТЧИКИ + ;
и еще одно слово для добавления единицы к счетчику с заданным номером:: УЧЕТ ( номер-категории --) СЧЕТЧИК 1 SWAP +! ;
Здесь 1 служит приращением для слова +!, a SWAP располагает его аргументы в требуемом порядке, т. е. ( n адрес --).
Теперь, например, выражение 3 УЧЕТ увеличит значение счетчика, соответствующего категории крупных яиц.
Определим слово, которое переводит вес на дюжину в номер категории1: : КАТЕГОРИЯ ( вес—на-дюжину — номер-категории) DUP 18 < IF в ELSE DUP 21 < IF I ELSE DUP 24 < IF 2 ELSE DUP 27 < IF 3 ELSE DUP З0 < IF 4 ELSE 5 THEN THEN THEN THEN THEN SWAP DROP ;
1 для специалистов. В конце главы будет приведено более простое определение.
(К тому времени, когда процесс вычисления подойдет к выражению SWAP DROP, в стеке будут находиться два значения: вес, который мы размножили с помощью команды DUP, и номер категории, расположенный в вершине. Нам требуется только номер категории. Выражение SWAP DROP убирает вес.)
Например, выражение 25 КАТЕГОРИЯ оставит в стеке число 3. Приведенное выше определение слова КАТЕГОРИЯ напоминает наше прежнее определение РАЗМЕР-ЯИЦ, но, следуя стилю Форта (слова должны создаваться по возможности более короткими), мы убрали из этого определения выдаваемые сообщения и определили еще одно слово, которое по заданному номеру сорта яиц выдает сообщение1: : МАРКИРОВКА ( номер-категории — ) DUP 0= IF ." Брак " ELSE DUP 1 = IF ." Мелкие " ELSE DUP 2 = IF ." Средние " ELSE DUP 3 = IF ." Крупные " ELSE DUP 4 = IF ." Очень крупные " ELSE ." Ошибка " THEN THEN THEN THEN THEN BROP ;
Например: 1 МАРКИРОВКА Мелкие ok
Теперь мы можем определить слово РАЗМЕР-ЯИЦ, используя три наших собственных слова: : РАЗМЕР-ЯИЦ ( вес-на-дюжину — ) КАТЕГОРИЯ DUP МАРКИРОВКА УЧЕТ ;
Таким образом, выражение 23 РАЗМЕР-ЯИЦ выведет на вашем дисплее сообщение
Средние ok
и обновит счетчик яиц среднего размера.
Каким образом мы узнаем содержимое счетчиков в конце дня? Придется проверить по отдельности каждую ячейку массива, например, с помощью выражения 3 СЧЕТЧИК? (которое выведет число упакованных коробок с «крупными» яйцами). Однако можно
1 для специалистов Более элегантный вариант этого определения приводится в следующей главе.
попытаться для печати результирующей таблицы за день в приведенном ниже формате определить свое собственное слово:КОЛИЧЕСТВО РАЗМЕР 1 Брак 112 Мелкие 132 Средние 143 Крупные 159 Очень крупные 0 Ошибка
Так как вы уже научились получать номера категорий, можно просто использовать цикл DO с номером категории в качестве индекса:: СВОДКА РАGЕ ." КОЛИЧЕСТВО РАЗМЕР" CR CR 6 0 DO I СЧЕТЧИК @ 5 U.R 7 SPACES I МАРКИРОВКА CR LOOP ;
(Выражение I СЧЕТЧИК @ 5 U.R
выбирает номер категории, подготовленный словом I, как индекс массива и выводит содержимое соответствующего элемента последнего в виде поля из пяти значений.)
КАК ПРАВИЛЬНО «ОБЪЯСНЯТЬСЯ» НА ФОРТЕ?
В Форте словом считается отдельный символ или группа символов, имеющие определение. Почти любое сочетание символов может употребляться для именования слов. Ниже приводятся группы символов, которые нельзя использовать для этих целей, поскольку компьютер может «подумать»1, что вы собираетесь выполнить одну из следующих операций:
RETURN — завершить набор символов;
BACKSPACE — исправить ошибочно набранный символ;
SPACE (пробел) — указать конец слова.
Теперь разберем слово, имя которого состоит из двух знаков пунктуации. Это слово ." и произносится оно как «точка-кавычка». Вы можете применять его внутри определения для вывода «строки» текста на своем терминале. Например2:
1 Для философов, конечно, компьютер не «думает», но, к сожалению, очень трудно подобрать слово, точно отражающее его действия. Поэтому условимся считать, что компьютер «думает».
2 В Форте определен базовый набор слов. В книге такие слова лаются на языке оригинала. В большинстве приводимых здесь примеров слова, определяемые пользователем, написаны по-русски. Версии Форта, распространенные в СССР, позволяют это делать. — Примеч. ред.
: ВСТРЕЧА ." Привет, я говорю на форте " ;<return> ok
Мы только что определили слово с именем ВСТРЕЧА. Его определение состоит только из одного слова, .", за которым следует текст, подлежащий выводу. Знак кавычки в конце текста не будет выведен; он отмечает конец текста и называется ограничителем. Специфицируя слово ВСТРЕЧА, не забудьте в конце поставить символ ;— знак конца определения.
Давайте выполним слово ВСТРЕЧА: BCTPEЧA<return> Привет, я говорю на форте ок
КАК РАБОТАТЬ НА ФОРТЕ
До сих пор вы компилировали новые определения в словарь, набирая их на клавиатуре вашего терминала. Здесь же вам предлагается другой вариант создания определений — с использованием дисковой памяти и текстового редактора Форта.
Настоящая глава состоит из двух частей. В первой части обсуждаются вопросы применения дисковой памяти для хранения исходных текстов программ на Форте, а также правила оформления этих исходных текстов. Первая часть рассчитана на читателей с любым уровнем подготовки. Во второй части рассматривается конкретный текстовый редактор. Если текстовый редактор, с которым вы работаете, отличается от рассматриваемого, мы рекомендуем вам обратиться к документации по вашей Форт-системе.
КОД ДЛЯ ПРЕДСТАВЛЕНИЯ СИМВОЛЬНОЙ ИНФОРМАЦИИ (ASCII)
Если числа в компьютере хранятся в двоичной форме, то как в нем хранятся буквы или другие символы? Тоже в двоичной форме, только в специальном коде, который был принят в качестве промышленного стандарта много лет назад, ASCII1 (стандартный американский код для обмена информацией). В табл. 7.1 приводятся все символы системы и их цифровые представления как в шестнадцатиричной, так и в десятичной форме.
Символы, помещенные в первом столбце (имеющие шестнадцатиричные коды 0 - 1F), называются управляющими, так как они указывают, что терминал или компьютер должен выполнить, например подать звуковой сигнал, вернуть каретку на одну позицию, начать новую строку и т. д. Остальные символы называются печатными, поскольку они выводят на печать видимые символы, включая буквы, цифры от 0 до 9, все доступные символы и даже пробел (шестнадцатиричный код 20). Единственным исключением является символ DEL (шестнадцатиричный код 7F), который предписывает компьютеру игнорировать последний переданный символ.
В первой главе мы ввели слово EMIT, которое берет из стека значение в коде ASCII и посылает его на терминал для распечатки этого значения в виде символа, например: 65 EMIT A ok 66 EMIT В ok
(Мы используем десятичное, а не шестнадцатиричное представние, потому что ваш современный компьютер больше всего приспособлен ко вводу именно в таком представлении2.)
Почему бы нам не проверить действие EMIT на каждом печатном символе «автоматически»? : ОТОБРАЖАЕМЫЕ 127 32 DO I EMIТ SPACE LOOP ;
1 Код ASCII совпадает с применяемым в СССР семиразрядным кодом КОИ-7. В реализациях Форта на отечественных ЭВМ используются восьмиразрядные коды (например, КОИ-8) с добавлением кодов русских букв, что и позволяет использовать русские слова. - Примеч ред.
2 Для специалистов Не тратьте время на раздел для начинающих.
Таблица 7.1. Символы в коде ASCII и их числовые эквиваленты
| Символ | Шестн | Дес. | Символ | Шестн. | Дес. | Символ | Шестн. | Дес. | Символ | Шестн | Дес. |
| NUL | 00 | 0 | SP | 20 | 32 | @ | 40 | 64 | 60 | 96 | |
| SOH | 01 | 1 | ! | 21 | 33 | A | 41 | 65 | а | 61 | 97 |
| STX | 02 | 2 | " | 22 | 34 | В | 42 | 66 | b | 62 | 98 |
| ETX | 03 | 3 | # | 23 | 35 | С | 43 | 67 | с | 63 | 99 |
| EOT | 04 | 4 | $ | 24 | 36 | D | 44 | 68 | d | 64 | 100 |
| ENQ | 05 | 5 | % | 25 | 37 | E | 45 | 69 | е | 65 | 101 |
| ACK | 06 | 6 | & | 26 | 38 | F | 46 | 70 | f | 66 | 102 |
| BEL | 07 | 7 | ' | 27 | 39 | G | 47 | 71 | 9 | 67 | 103 |
| BS | 08 | 8 | ( | 28 | 40 | H | 48 | 72 | h | 68 | 104 |
| HT | 09 | 9 | ) | 29 | 41 | I | 49 | 73 | i | 69 | 105 |
| LF | 0A | 10 | * | 2A | 42 | J | 4A | 74 | j | 6A | 106 |
| VT | 0B | 11 | + | 2B | 43 | К | 4В | 75 | k | 6B | 107 |
| FF | 0С | 12 | , | 2C | 44 | L | 4C | 76 | l | 6C | 108 |
| CR | 0D | 13 | - | 2D | 45 | M | 4D | 77 | m | 6D | 109 |
| SM | 0E | 14 | . | 2E | 46 | N | 4E | 78 | n | 6E | 110 |
| SI | 0F | 15 | / | 2P | 47 | O | 4F | 79 | o | 6F | 111 |
| DLE | 10 | 16 | 0 | 30 | 48 | P | 50 | 80 | p | 70 | 112 |
| DC1 | 11 | 17 | 1 | 31 | 49 | Q | 51 | 81 | q | 71 | 113 |
| DC2 | 12 | 18 | 2 | 32 | 50 | R | 52 | 82 | r | 72 | 114 |
| DC3 | 13 | 19 | 3 | 33 | 51 | S | 53 | 83 | s | 73 | 115 |
| DC4 | 14 | 20 | 4 | 34 | 52 | Т | 54 | 84 | t | 74 | 116 |
| NAK | 15 | 21 | 5 | 35 | 53 | U | 55 | 85 | u | 75 | 117 |
| SYN | 16 | 22 | 6 | 36 | 54 | V | 56 | 86 | v | 76 | 118 |
| ETB | 17 | 23 | 7 | 37 | 55 | W | 57 | 87 | w | 77 | 119 |
| CAN | 18 | 24 | 8 | 38 | 56 | X | 58 | 88 | x | 78 | 120 |
| EM | 19 | 25 | 9 | 39 | 57 | Y | 59 | 89 | y | 79 | 121 |
| SUB | 1A | 26 | : | ЗА | 58 | Z | 5A | 90 | z | 7A | 122 |
| ESC | 1B | 27 | ; | 3B | 59 | [ | 5В | 91 | { | 7B | 123 |
| FS | 1C | 28 | < | 3C | 60 | \ | 5C | 92 | | | 7C | 124 |
| GS | 1D | 29 | = | 3D | 61 | ] | 5D | 93 | } | 7D | 125 |
| RS | 1E | 30 | > | 3E | 62 | ^ | 5E | 94 | ~ | 7E | 126 |
| US | 1F | 31 | ? | 3F | 63 | _ | 5F | 95 | DEL (RB) | 7F | 127 |
В первом столбце перечислены символы в коде ASCII или, если это управляющие символы, в общепринятых обозначениях; в двух последующих столбцах даются их шестнадцатиричные и десятичные эквиваленты
Слово ОТОБРАЖАЕМЫЕ выведет на печать каждый требуемый символ из кода ASCII, т. е. символы с кодами от десятичного 32 до десятичного 126. (Мы используем коды ASCII в качестве индекса цикла DO.) ОТОБРАЖАЕМЫЕ ! " # $ & ' ( ) * + ... ok
Начинающие могут поинтересоваться, как поведет себя EMIT с управляющими символами; наберите на клавиатуре такой текст:

Вы услышите какой-то сигнал, который является вариантом звонка печатающей машинки для дисплея. (В некоторых системах слово EMIT вместо того чтобы выполнить команду, выводит специфические символы.)
Неплохо знать следующие управляющие символы: НАЗВАНИЕ ОПЕРАЦИЯ ДЕСЯТИЧНЫЙ ЭКВИВАЛЕНТ
BS Возврат назад на одну 8 позицию ("забой") LF Перевод строки 10 CR Возврат каретки 13
Поэкспериментируйте с этими управляющими символами и посмотрите, как они выполняются.
Код ASCII разработан таким образом, что каждый символ в нем может быть представлен одним байтом. В приводимых здесь таблицах буква «с» означает, что содержимое некоторого байта соответствует символу в коде ASCII.
В некоторых Форт-системах имеется слово ASCII, которое используется для улучшения читабельности определений, поскольку переводит отдельные символы в шестнадцатиричные значения. Вспомним, к примеру, следующее определение: : STAR 42 EMIT ;
Если в вашей системе есть это слово, то вы можете определить его так: : STAR ASCII * EMIT ;
В обоих случаях элементы словаря после трансляции определений будут абсолютно одинаковы, однако последнее определение легче воспринимается. ASCII ( -- c) перевод следующего символа из входного потока в его ASCII-эквивалент